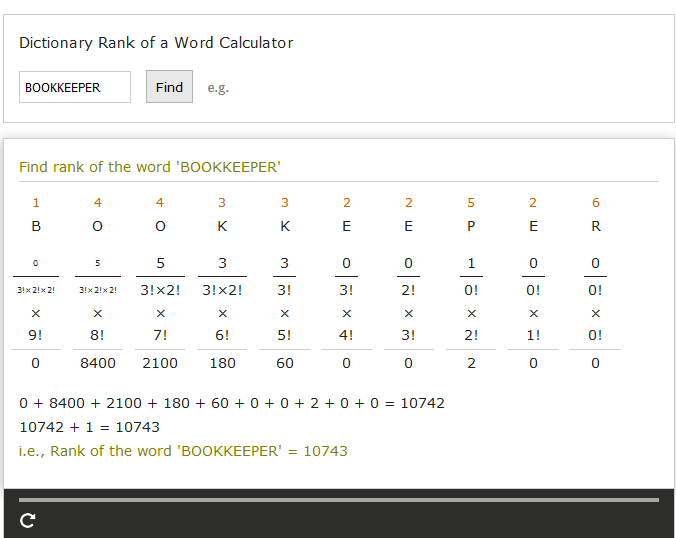
I'm posting this although much has already been posted about this question. I didn't want to post as an answer since it's not working. The answer to this post (Finding the rank of the Given string in list of all possible permutations with Duplicates) did not work for me.
So I tried this (which is a compilation of code I've plagiarized and my attempt to deal with repetitions). The non-repeating cases work fine. BOOKKEEPER generates 83863, not the desired 10743.
(The factorial function and letter counter array 'repeats' are working correctly. I didn't post to save space.)
while (pointer != length)
{
if (sortedWordChars[pointer] != wordArray[pointer])
{
// Swap the current character with the one after that
char temp = sortedWordChars[pointer];
sortedWordChars[pointer] = sortedWordChars[next];
sortedWordChars[next] = temp;
next++;
//For each position check how many characters left have duplicates,
//and use the logic that if you need to permute n things and if 'a' things
//are similar the number of permutations is n!/a!
int ct = repeats[(sortedWordChars[pointer]-64)];
// Increment the rank
if (ct>1) { //repeats?
System.out.println("repeating " + (sortedWordChars[pointer]-64));
//In case of repetition of any character use: (n-1)!/(times)!
//e.g. if there is 1 character which is repeating twice,
//x* (n-1)!/2!
int dividend = getFactorialIter(length - pointer - 1);
int divisor = getFactorialIter(ct);
int quo = dividend/divisor;
rank += quo;
} else {
rank += getFactorialIter(length - pointer - 1);
}
} else
{
pointer++;
next = pointer + 1;
}
}