Super simple column assignment
A pandas dataframe is implemented as an ordered dict of columns.
This means that the __getitem__ [] can not only be used to get a certain column, but __setitem__ [] = can be used to assign a new column.
For example, this dataframe can have a column added to it by simply using the [] accessor
size name color
0 big rose red
1 small violet blue
2 small tulip red
3 small harebell blue
df['protected'] = ['no', 'no', 'no', 'yes']
size name color protected
0 big rose red no
1 small violet blue no
2 small tulip red no
3 small harebell blue yes
Note that this works even if the index of the dataframe is off.
df.index = [3,2,1,0]
df['protected'] = ['no', 'no', 'no', 'yes']
size name color protected
3 big rose red no
2 small violet blue no
1 small tulip red no
0 small harebell blue yes
[]= is the way to go, but watch out!
However, if you have a pd.Series and try to assign it to a dataframe where the indexes are off, you will run in to trouble. See example:
df['protected'] = pd.Series(['no', 'no', 'no', 'yes'])
size name color protected
3 big rose red yes
2 small violet blue no
1 small tulip red no
0 small harebell blue no
This is because a pd.Series by default has an index enumerated from 0 to n. And the pandas [] = method tries to be "smart"
What actually is going on.
When you use the [] = method pandas is quietly performing an outer join or outer merge using the index of the left hand dataframe and the index of the right hand series. df['column'] = series
Side note
This quickly causes cognitive dissonance, since the []= method is trying to do a lot of different things depending on the input, and the outcome cannot be predicted unless you just know how pandas works. I would therefore advice against the []= in code bases, but when exploring data in a notebook, it is fine.
Going around the problem
If you have a pd.Series and want it assigned from top to bottom, or if you are coding productive code and you are not sure of the index order, it is worth it to safeguard for this kind of issue.
You could downcast the pd.Series to a np.ndarray or a list, this will do the trick.
df['protected'] = pd.Series(['no', 'no', 'no', 'yes']).values
or
df['protected'] = list(pd.Series(['no', 'no', 'no', 'yes']))
But this is not very explicit.
Some coder may come along and say "Hey, this looks redundant, I'll just optimize this away".
Explicit way
Setting the index of the pd.Series to be the index of the df is explicit.
df['protected'] = pd.Series(['no', 'no', 'no', 'yes'], index=df.index)
Or more realistically, you probably have a pd.Series already available.
protected_series = pd.Series(['no', 'no', 'no', 'yes'])
protected_series.index = df.index
3 no
2 no
1 no
0 yes
Can now be assigned
df['protected'] = protected_series
size name color protected
3 big rose red no
2 small violet blue no
1 small tulip red no
0 small harebell blue yes
Alternative way with df.reset_index()
Since the index dissonance is the problem, if you feel that the index of the dataframe should not dictate things, you can simply drop the index, this should be faster, but it is not very clean, since your function now probably does two things.
df.reset_index(drop=True)
protected_series.reset_index(drop=True)
df['protected'] = protected_series
size name color protected
0 big rose red no
1 small violet blue no
2 small tulip red no
3 small harebell blue yes
Note on df.assign
While df.assign make it more explicit what you are doing, it actually has all the same problems as the above []=
df.assign(protected=pd.Series(['no', 'no', 'no', 'yes']))
size name color protected
3 big rose red yes
2 small violet blue no
1 small tulip red no
0 small harebell blue no
Just watch out with df.assign that your column is not called self. It will cause errors. This makes df.assign smelly, since there are these kind of artifacts in the function.
df.assign(self=pd.Series(['no', 'no', 'no', 'yes'])
TypeError: assign() got multiple values for keyword argument 'self'
You may say, "Well, I'll just not use self then". But who knows how this function changes in the future to support new arguments. Maybe your column name will be an argument in a new update of pandas, causing problems with upgrading.

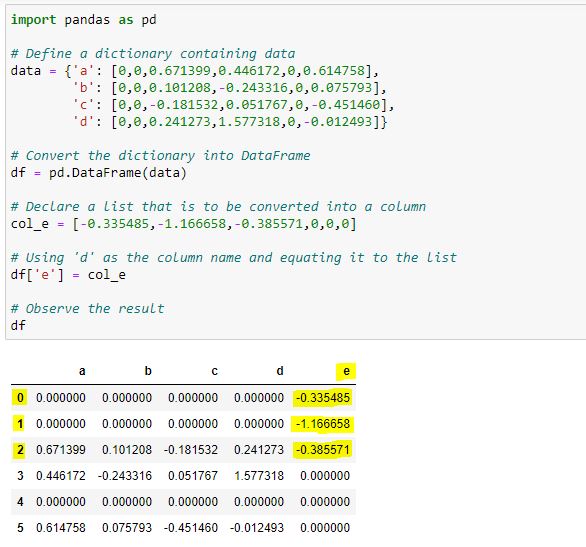
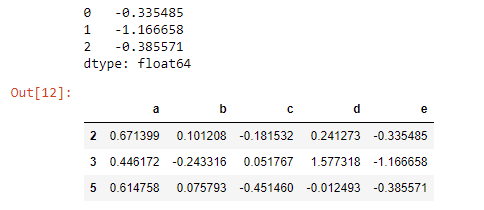
df['e'] = e, but that doesn't work if the indexes don't match, but the indexes only don't match because OP created it like that (e = Series(<np_array>)), but that was removed from the question in revision 5. – Outburst