I have a dataframe that looks like
Year quarter
2000 q2
2001 q3
How do I add a new column by combining these columns to get the following dataframe?
Year quarter period
2000 q2 2000q2
2001 q3 2001q3
I have a dataframe that looks like
Year quarter
2000 q2
2001 q3
How do I add a new column by combining these columns to get the following dataframe?
Year quarter period
2000 q2 2000q2
2001 q3 2001q3
If both columns are strings, you can concatenate them directly:
df["period"] = df["Year"] + df["quarter"]
If one (or both) of the columns are not string typed, you should convert it (them) first,
df["period"] = df["Year"].astype(str) + df["quarter"]
If you need to join multiple string columns, you can use agg:
df['period'] = df[['Year', 'quarter', ...]].agg('-'.join, axis=1)
Where "-" is the separator.
add(dataframe.iloc[:, 0:10]) for example? –
Hurtful sum. –
Stoltzfus dataframe["period"] = dataframe["Year"].map(str) + dataframe["quarter"].map(str) map is just applying string conversion to all entries. –
Goodhumored dataframe["period"] = dataframe["Year"].map(str) + '__' + dataframe["quarter"] –
Examine SettingWithCopyWarning when I use this solution - how can I do this without triggering that warning? –
Drawl astype should be used for casting pandas.Series to another type. So instead of .map(str), use .astype(str). –
Afteryears .agg... use .apply(lambda x: '_'.join(x), axis=1). This was 5 times faster than the .agg version. –
Christcrossrow .fillna('').agg('-'.join, axis=1). –
Oneidaoneil [''.join(i) for i in zip(df["Year"].map(str),df["quarter"])]
or slightly slower but more compact:
df.Year.str.cat(df.quarter)
df['Year'].astype(str) + df['quarter']
UPDATE: Timing graph Pandas 0.23.4
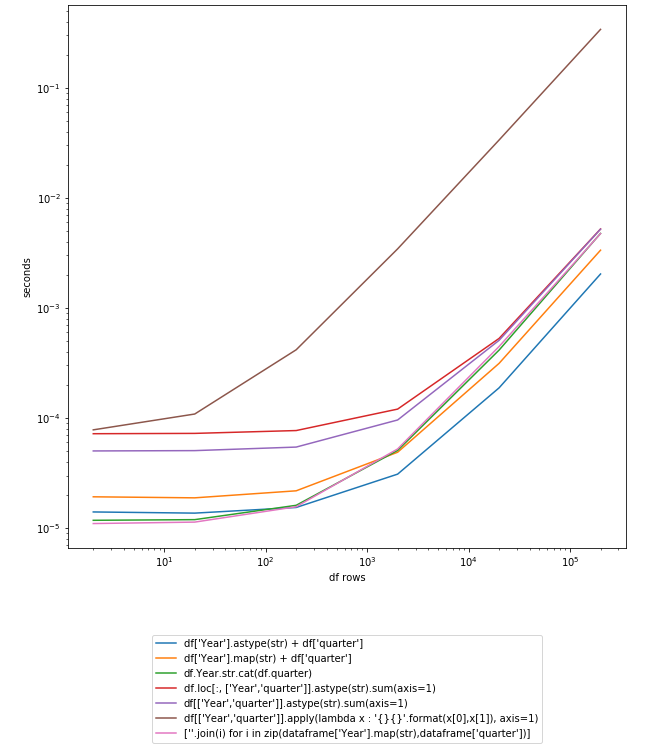
Let's test it on 200K rows DF:
In [250]: df
Out[250]:
Year quarter
0 2014 q1
1 2015 q2
In [251]: df = pd.concat([df] * 10**5)
In [252]: df.shape
Out[252]: (200000, 2)
UPDATE: new timings using Pandas 0.19.0
Timing without CPU/GPU optimization (sorted from fastest to slowest):
In [107]: %timeit df['Year'].astype(str) + df['quarter']
10 loops, best of 3: 131 ms per loop
In [106]: %timeit df['Year'].map(str) + df['quarter']
10 loops, best of 3: 161 ms per loop
In [108]: %timeit df.Year.str.cat(df.quarter)
10 loops, best of 3: 189 ms per loop
In [109]: %timeit df.loc[:, ['Year','quarter']].astype(str).sum(axis=1)
1 loop, best of 3: 567 ms per loop
In [110]: %timeit df[['Year','quarter']].astype(str).sum(axis=1)
1 loop, best of 3: 584 ms per loop
In [111]: %timeit df[['Year','quarter']].apply(lambda x : '{}{}'.format(x[0],x[1]), axis=1)
1 loop, best of 3: 24.7 s per loop
Timing using CPU/GPU optimization:
In [113]: %timeit df['Year'].astype(str) + df['quarter']
10 loops, best of 3: 53.3 ms per loop
In [114]: %timeit df['Year'].map(str) + df['quarter']
10 loops, best of 3: 65.5 ms per loop
In [115]: %timeit df.Year.str.cat(df.quarter)
10 loops, best of 3: 79.9 ms per loop
In [116]: %timeit df.loc[:, ['Year','quarter']].astype(str).sum(axis=1)
1 loop, best of 3: 230 ms per loop
In [117]: %timeit df[['Year','quarter']].astype(str).sum(axis=1)
1 loop, best of 3: 230 ms per loop
In [118]: %timeit df[['Year','quarter']].apply(lambda x : '{}{}'.format(x[0],x[1]), axis=1)
1 loop, best of 3: 9.38 s per loop
Answer contribution by @anton-vbr
df.T.apply(lambda x: x.str.cat(sep='')) –
Retract .str.cat() method? –
Moonfish df['Year'].map(str) works. Does str serve as an arg and it basically just sets everything in the df['Year'] as string? Thanks. –
Claraclarabella apply(str) is typically faster than astype(str), would be interesting to see how that stacks up here. –
Assembler [111] and [107] above, in a function that takes as input a list of arbitrary length. I guess it's obvious one could loop through the list to iteratively build up the full concatenated strings, but thought there might be a better way. –
Tecla df = pd.DataFrame({'Year': ['2014', '2015'], 'quarter': ['q1', 'q2']})
df['period'] = df[['Year', 'quarter']].apply(lambda x: ''.join(x), axis=1)
Yields this dataframe
Year quarter period
0 2014 q1 2014q1
1 2015 q2 2015q2
This method generalizes to an arbitrary number of string columns by replacing df[['Year', 'quarter']] with any column slice of your dataframe, e.g. df.iloc[:,0:2].apply(lambda x: ''.join(x), axis=1).
You can check more information about apply() method here
lambda x: ''.join(x) is just ''.join, no? –
Bethought lambda x: ''.join(x) construction doesn't do anything; it's like using lambda x: sum(x) instead of just sum. –
Bethought join if string != "some_string" how could you add that? –
Often ''.join, i.e.: df['period'] = df[['Year', 'quarter']].apply(''.join, axis=1). –
Steady TypeError: ('sequence item 0: expected str instance, int found', as I want to combine an integer categorical variable with a string category. –
Cacogenics join takes only str instances in an iterable. Use a map to convert them all into str and then use join. –
Sewn df['Foo'].map(function) + '-' + df['Bar'].map(function) approach. For ~48k rows applying a join along axis 1 took 1.15s whereas the other approach takes 100ms. Not unreasonable on a small dataset, but if you are working with a lot of data that can make a big difference. –
Sapphirine The method cat() of the .str accessor works really well for this:
>>> import pandas as pd
>>> df = pd.DataFrame([["2014", "q1"],
... ["2015", "q3"]],
... columns=('Year', 'Quarter'))
>>> print(df)
Year Quarter
0 2014 q1
1 2015 q3
>>> df['Period'] = df.Year.str.cat(df.Quarter)
>>> print(df)
Year Quarter Period
0 2014 q1 2014q1
1 2015 q3 2015q3
cat() even allows you to add a separator so, for example, suppose you only have integers for year and period, you can do this:
>>> import pandas as pd
>>> df = pd.DataFrame([[2014, 1],
... [2015, 3]],
... columns=('Year', 'Quarter'))
>>> print(df)
Year Quarter
0 2014 1
1 2015 3
>>> df['Period'] = df.Year.astype(str).str.cat(df.Quarter.astype(str), sep='q')
>>> print(df)
Year Quarter Period
0 2014 1 2014q1
1 2015 3 2015q3
Joining multiple columns is just a matter of passing either a list of series or a dataframe containing all but the first column as a parameter to str.cat() invoked on the first column (Series):
>>> df = pd.DataFrame(
... [['USA', 'Nevada', 'Las Vegas'],
... ['Brazil', 'Pernambuco', 'Recife']],
... columns=['Country', 'State', 'City'],
... )
>>> df['AllTogether'] = df['Country'].str.cat(df[['State', 'City']], sep=' - ')
>>> print(df)
Country State City AllTogether
0 USA Nevada Las Vegas USA - Nevada - Las Vegas
1 Brazil Pernambuco Recife Brazil - Pernambuco - Recife
Do note that if your pandas dataframe/series has null values, you need to include the parameter na_rep to replace the NaN values with a string, otherwise the combined column will default to NaN.
lambda or map; also it just reads most cleanly. –
Venable sep keyword? in pandas-0.23.4. Thanks! –
Ajaajaccio sep parameter is only necessary if you intend to separate the parts of the concatenated string. If you get an error, please show us your failing example. –
Moonfish .str.cat(df[['State', 'City']], sep ='\n'), for example. I haven't tested it yet, though. –
Moonfish Use of a lamba function this time with string.format().
import pandas as pd
df = pd.DataFrame({'Year': ['2014', '2015'], 'Quarter': ['q1', 'q2']})
print df
df['YearQuarter'] = df[['Year','Quarter']].apply(lambda x : '{}{}'.format(x[0],x[1]), axis=1)
print df
Quarter Year
0 q1 2014
1 q2 2015
Quarter Year YearQuarter
0 q1 2014 2014q1
1 q2 2015 2015q2
This allows you to work with non-strings and reformat values as needed.
import pandas as pd
df = pd.DataFrame({'Year': ['2014', '2015'], 'Quarter': [1, 2]})
print df.dtypes
print df
df['YearQuarter'] = df[['Year','Quarter']].apply(lambda x : '{}q{}'.format(x[0],x[1]), axis=1)
print df
Quarter int64
Year object
dtype: object
Quarter Year
0 1 2014
1 2 2015
Quarter Year YearQuarter
0 1 2014 2014q1
1 2 2015 2015q2
df_game['formatted_game_time'] = df_game[['wday', 'month', 'day', 'year', 'time']].apply(lambda x: '{}, {}/{}/{} @ {}'.format(x[0], x[1], x[2], x[3], x[4]), axis=1) –
Volney generalising to multiple columns, why not:
columns = ['whatever', 'columns', 'you', 'choose']
df['period'] = df[columns].astype(str).sum(axis=1)
You can use lambda:
combine_lambda = lambda x: '{}{}'.format(x.Year, x.quarter)
And then use it with creating the new column:
df['period'] = df.apply(combine_lambda, axis = 1)
Let us suppose your dataframe is df with columns Year and Quarter.
import pandas as pd
df = pd.DataFrame({'Quarter':'q1 q2 q3 q4'.split(), 'Year':'2000'})
Suppose we want to see the dataframe;
df
>>> Quarter Year
0 q1 2000
1 q2 2000
2 q3 2000
3 q4 2000
Finally, concatenate the Year and the Quarter as follows.
df['Period'] = df['Year'] + ' ' + df['Quarter']
You can now print df to see the resulting dataframe.
df
>>> Quarter Year Period
0 q1 2000 2000 q1
1 q2 2000 2000 q2
2 q3 2000 2000 q3
3 q4 2000 2000 q4
If you do not want the space between the year and quarter, simply remove it by doing;
df['Period'] = df['Year'] + df['Quarter']
df['Period'] = df['Year'].map(str) + df['Quarter'].map(str) –
Exorcism TypeError: Series cannot perform the operation + when I run either df2['filename'] = df2['job_number'] + '.' + df2['task_number'] or df2['filename'] = df2['job_number'].map(str) + '.' + df2['task_number'].map(str). –
Xanthate df2['filename'] = df2['job_number'].astype(str) + '.' + df2['task_number'].astype(str) did work. –
Xanthate dataframe that I created above, you will see that all the columns are strings. –
Environs Although the @silvado answer is good if you change df.map(str) to df.astype(str) it will be faster:
import pandas as pd
df = pd.DataFrame({'Year': ['2014', '2015'], 'quarter': ['q1', 'q2']})
In [131]: %timeit df["Year"].map(str)
10000 loops, best of 3: 132 us per loop
In [132]: %timeit df["Year"].astype(str)
10000 loops, best of 3: 82.2 us per loop
Here is an implementation that I find very versatile:
In [1]: import pandas as pd
In [2]: df = pd.DataFrame([[0, 'the', 'quick', 'brown'],
...: [1, 'fox', 'jumps', 'over'],
...: [2, 'the', 'lazy', 'dog']],
...: columns=['c0', 'c1', 'c2', 'c3'])
In [3]: def str_join(df, sep, *cols):
...: from functools import reduce
...: return reduce(lambda x, y: x.astype(str).str.cat(y.astype(str), sep=sep),
...: [df[col] for col in cols])
...:
In [4]: df['cat'] = str_join(df, '-', 'c0', 'c1', 'c2', 'c3')
In [5]: df
Out[5]:
c0 c1 c2 c3 cat
0 0 the quick brown 0-the-quick-brown
1 1 fox jumps over 1-fox-jumps-over
2 2 the lazy dog 2-the-lazy-dog
more efficient is
def concat_df_str1(df):
""" run time: 1.3416s """
return pd.Series([''.join(row.astype(str)) for row in df.values], index=df.index)
and here is a time test:
import numpy as np
import pandas as pd
from time import time
def concat_df_str1(df):
""" run time: 1.3416s """
return pd.Series([''.join(row.astype(str)) for row in df.values], index=df.index)
def concat_df_str2(df):
""" run time: 5.2758s """
return df.astype(str).sum(axis=1)
def concat_df_str3(df):
""" run time: 5.0076s """
df = df.astype(str)
return df[0] + df[1] + df[2] + df[3] + df[4] + \
df[5] + df[6] + df[7] + df[8] + df[9]
def concat_df_str4(df):
""" run time: 7.8624s """
return df.astype(str).apply(lambda x: ''.join(x), axis=1)
def main():
df = pd.DataFrame(np.zeros(1000000).reshape(100000, 10))
df = df.astype(int)
time1 = time()
df_en = concat_df_str4(df)
print('run time: %.4fs' % (time() - time1))
print(df_en.head(10))
if __name__ == '__main__':
main()
final, when sum(concat_df_str2) is used, the result is not simply concat, it will trans to integer.
df.values[:, 0:3] or df.values[:, [0,2]]. –
Healy Using zip could be even quicker:
df["period"] = [''.join(i) for i in zip(df["Year"].map(str),df["quarter"])]
Graph:
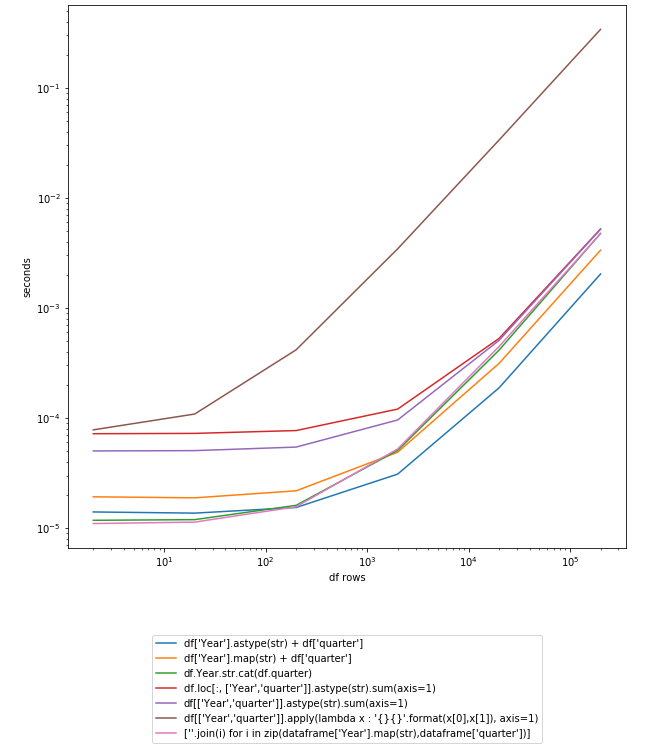
import pandas as pd
import numpy as np
import timeit
import matplotlib.pyplot as plt
from collections import defaultdict
df = pd.DataFrame({'Year': ['2014', '2015'], 'quarter': ['q1', 'q2']})
myfuncs = {
"df['Year'].astype(str) + df['quarter']":
lambda: df['Year'].astype(str) + df['quarter'],
"df['Year'].map(str) + df['quarter']":
lambda: df['Year'].map(str) + df['quarter'],
"df.Year.str.cat(df.quarter)":
lambda: df.Year.str.cat(df.quarter),
"df.loc[:, ['Year','quarter']].astype(str).sum(axis=1)":
lambda: df.loc[:, ['Year','quarter']].astype(str).sum(axis=1),
"df[['Year','quarter']].astype(str).sum(axis=1)":
lambda: df[['Year','quarter']].astype(str).sum(axis=1),
"df[['Year','quarter']].apply(lambda x : '{}{}'.format(x[0],x[1]), axis=1)":
lambda: df[['Year','quarter']].apply(lambda x : '{}{}'.format(x[0],x[1]), axis=1),
"[''.join(i) for i in zip(dataframe['Year'].map(str),dataframe['quarter'])]":
lambda: [''.join(i) for i in zip(df["Year"].map(str),df["quarter"])]
}
d = defaultdict(dict)
step = 10
cont = True
while cont:
lendf = len(df); print(lendf)
for k,v in myfuncs.items():
iters = 1
t = 0
while t < 0.2:
ts = timeit.repeat(v, number=iters, repeat=3)
t = min(ts)
iters *= 10
d[k][lendf] = t/iters
if t > 2: cont = False
df = pd.concat([df]*step)
pd.DataFrame(d).plot().legend(loc='upper center', bbox_to_anchor=(0.5, -0.15))
plt.yscale('log'); plt.xscale('log'); plt.ylabel('seconds'); plt.xlabel('df rows')
plt.show()
This solution uses an intermediate step compressing two columns of the DataFrame to a single column containing a list of the values. This works not only for strings but for all kind of column-dtypes
import pandas as pd
df = pd.DataFrame({'Year': ['2014', '2015'], 'quarter': ['q1', 'q2']})
df['list']=df[['Year','quarter']].values.tolist()
df['period']=df['list'].apply(''.join)
print(df)
Result:
Year quarter list period
0 2014 q1 [2014, q1] 2014q1
1 2015 q2 [2015, q2] 2015q2
.apply(''.join) why not use .str.join('')? –
Furlani Here is my summary of the above solutions to concatenate / combine two columns with int and str value into a new column, using a separator between the values of columns. Three solutions work for this purpose.
# be cautious about the separator, some symbols may cause "SyntaxError: EOL while scanning string literal".
# e.g. ";;" as separator would raise the SyntaxError
separator = "&&"
# pd.Series.str.cat() method does not work to concatenate / combine two columns with int value and str value. This would raise "AttributeError: Can only use .cat accessor with a 'category' dtype"
df["period"] = df["Year"].map(str) + separator + df["quarter"]
df["period"] = df[['Year','quarter']].apply(lambda x : '{} && {}'.format(x[0],x[1]), axis=1)
df["period"] = df.apply(lambda x: f'{x["Year"]} && {x["quarter"]}', axis=1)
df["period"] = (df["Year"].astype(str) + separator + df["quarter"].astype(str)).astype('category') –
Flocculent my take....
listofcols = ['col1','col2','col3']
df['combined_cols'] = ''
for column in listofcols:
df['combined_cols'] = df['combined_cols'] + ' ' + df[column]
'''
When combining columns with strings by concatenating them using the addition operator + if any is NaN then entire output will be NaN so use fillna()
df["join"] = "some" + df["col"].fillna(df["val_if_nan"])
As many have mentioned previously, you must convert each column to string and then use the plus operator to combine two string columns. You can get a large performance improvement by using NumPy.
%timeit df['Year'].values.astype(str) + df.quarter
71.1 ms ± 3.76 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit df['Year'].astype(str) + df['quarter']
565 ms ± 22.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
df2['filename'] = df2['job_number'].values.astype(str) + '.' + df2['task_number'].values.astype(str) --> Output: TypeError: ufunc 'add' did not contain a loop with signature matching types dtype('<U21') dtype('<U21') dtype('<U21'). Both job_number and task_number are ints. –
Xanthate df['Year'].values.astype(str) + df.quarter –
Malleable One can use assign method of DataFrame:
df= (pd.DataFrame({'Year': ['2014', '2015'], 'quarter': ['q1', 'q2']}).
assign(period=lambda x: x.Year+x.quarter ))
Similar to @geher answer but with any separator you like:
SEP = " "
INPUT_COLUMNS_WITH_SEP = ",sep,".join(INPUT_COLUMNS).split(",")
df.assign(sep=SEP)[INPUT_COLUMNS_WITH_SEP].sum(axis=1)
def madd(x):
"""Performs element-wise string concatenation with multiple input arrays.
Args:
x: iterable of np.array.
Returns: np.array.
"""
for i, arr in enumerate(x):
if type(arr.item(0)) is not str:
x[i] = x[i].astype(str)
return reduce(np.core.defchararray.add, x)
For example:
data = list(zip([2000]*4, ['q1', 'q2', 'q3', 'q4']))
df = pd.DataFrame(data=data, columns=['Year', 'quarter'])
df['period'] = madd([df[col].values for col in ['Year', 'quarter']])
df
Year quarter period
0 2000 q1 2000q1
1 2000 q2 2000q2
2 2000 q3 2000q3
3 2000 q4 2000q4
from functools import reduce –
Poitiers Use .combine_first.
df['Period'] = df['Year'].combine_first(df['Quarter'])
.combine_first will result in either the value from 'Year' being stored in 'Period', or, if it is Null, the value from 'Quarter'. It will not concatenate the two strings and store them in 'Period'. –
Festoon For a little terse code, we can use .eval(). We can concatenate two (or more) string dtype columns horizontally using the + operator as follows.
df = pd.DataFrame({'A': ['x', 'y', 'z'], 'B': ['1', '2', '3']}, dtype='string')
df['C'] = df.eval("A + B")
You can even include the new column assignment inside the evaluated expression (which also opens up the possibility to do it in-place).
df = df.eval('C = A + B')
df.eval('C = A + B', inplace=True)
eval doesn't allow a similarly terse way to add delimiters; however, we can call str.cat() (which has the sep= kwarg) inside the numerical expression.
df = df.eval("D = A.str.cat([B, C], '_')")
which produces the following output (where columns, A, B and C are concatenated horizontally):

There are major string concatenation methods given on this page:
+: df['A'] + df['B'][f"{x}{y}" for x,y in zip(df['A'].tolist(), df['B'].tolist())])]
str.cat(): df['A'].str.cat(df['B'])As the following figure shows, vectorized concatenation (via +) is fastest if the strings being concatenated are short such as in the OP. However, if the strings are long (e.g. each cell contains a tweet or a book excerpt), then an explicit Python loop (use f-string in a list comprehension) is the fastest.
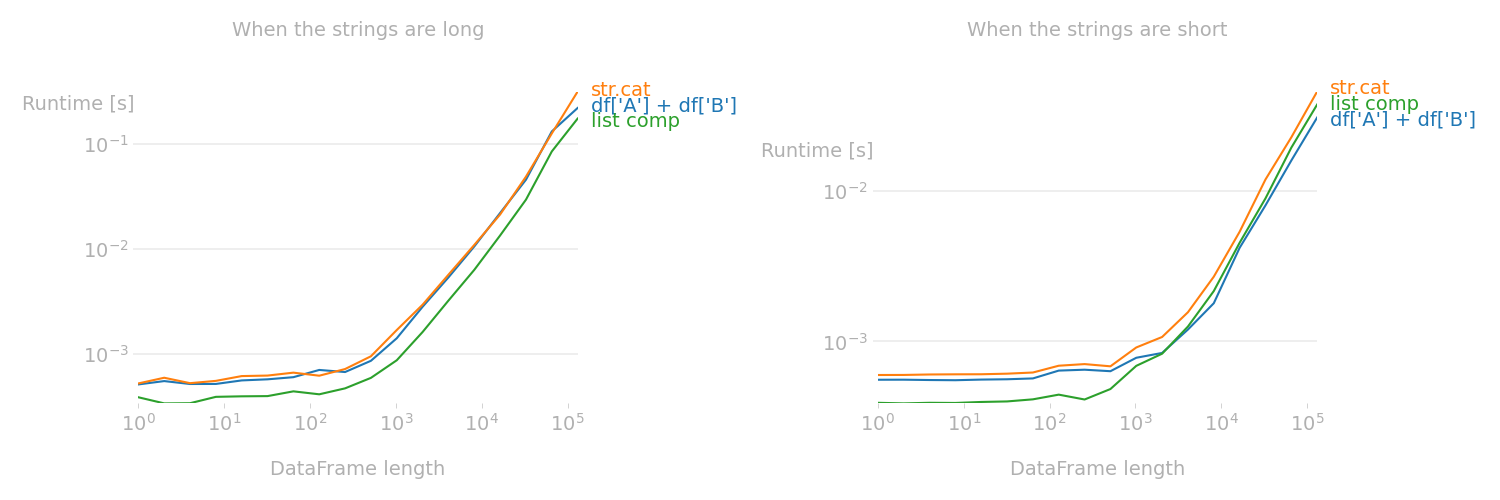
Code to reproduce the above figure:
import matplotlib.pyplot as plt
import pandas as pd
import perfplot
fig, axs = plt.subplots(1, 2, figsize=(15,5))
for ax, s, title in zip(axs, ('a'*1000, 'a'), ("long", "short")):
plt.sca(ax)
perfplot.plot(
kernels=[lambda df: df.assign(C=df['A'] + '_' + df['B']),
lambda df: df.assign(C=df['A'].str.cat(df['B'], '_')),
lambda df: df.assign(C=[f"{x}_{y}" for x,y in zip(df['A'].tolist(), df['B'].tolist())])],
n_range=[2**k for k in range(18)],
setup=lambda n: pd.DataFrame({'A': [s]*n, 'B': [s]*n}),
labels=["df['A'] + df['B']", "str.cat", "list comp"],
xlabel="DataFrame length",
title=f"When the strings are {title}",
equality_check=pd.DataFrame.equals)
fig.tight_layout()
fig.savefig("string_concat_perf.png")
© 2022 - 2024 — McMap. All rights reserved.