I have extracted a image document from tesseract and It has extracted successful. But I am not able to understand coordinate of extracted document.
Problem description: -
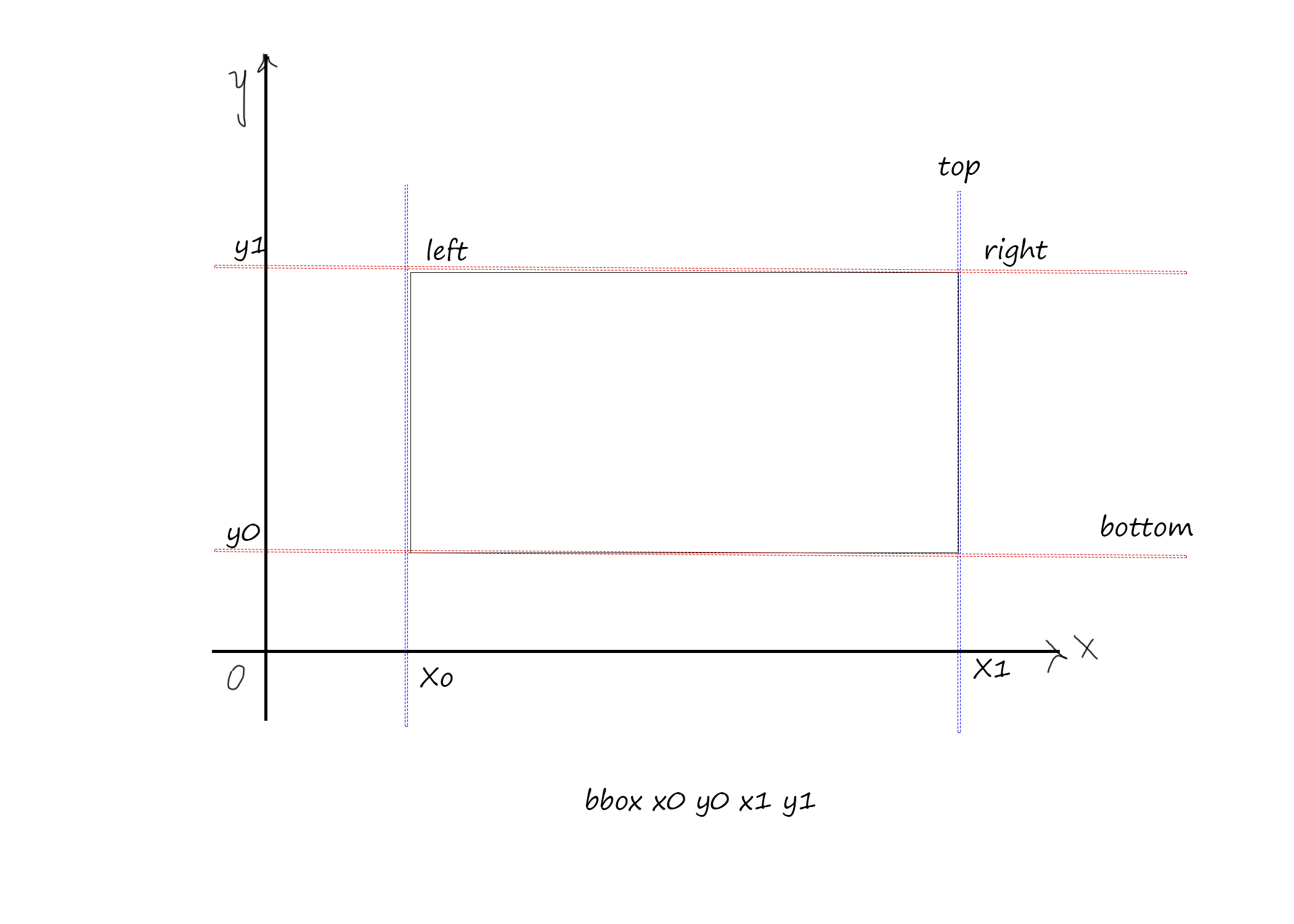
It showing coordinates but let me know that are these coordinates representing pixel or something else. These are in four like title="bbox 10 13 43 46" , so what is 10, 13 43 and 46. What position they are representing
complete code after extracting
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>
</title>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta name='ocr-system' content='tesseract'/>
</head>
<body>
<div class='ocr_page' id='page_1' title='image "D:\ABC.tif"; bbox 0 0 464 101'>
<div class='ocr_carea' id='block_1_1' title="bbox 10 13 330 55">
<p 1class='ocr_par'>
<span class='ocr_line' id='line_1_1' title="bbox 10 13 330 55">
<span class='ocr_word' id='word_1_1' title="bbox 10 13 43 46">
<span class='ocrx_word' id='xword_1_1' title="x_wconf -1"><strong>hi</strong></span>
</span>
<span class='ocr_word' id='word_1_2' title="bbox 148 13 268 47">
<span class='ocrx_word' id='xword_1_2' title="x_wconf -1"><strong>whats</strong></span>
</span>
<span class='ocr_word' id='word_1_3' title="bbox 283 22 330 55">
<span class='ocrx_word' id='xword_1_3' title="x_wconf -1"><strong>up</strong></span>
</span>
</span>
</p>
</div>
</div>
</body>
</html>