TLDR; skip to the last section (part 4.) for code implementation
1. Fuzzy vs Word embeddings
Unlike a fuzzy match, which is basically edit distance or levenshtein distance to match strings at alphabet level, word2vec (and other models such as fasttext and GloVe) represent each word in a n-dimensional euclidean space. The vector that represents each word is called a word vector or word embedding.
These word embeddings are n-dimensional vector representations of a large vocabulary of words. These vectors can be summed up to create a representation of the sentence's embedding. Sentences with word with similar semantics will have similar vectors, and thus their sentence embeddings will also be similar. Read more about how word2vec works internally here.
![enter image description here]()
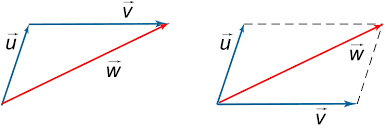
Let's say I have a sentence with 2 words. Word2Vec will represent each word here as a vector in some euclidean space. Summing them up, just like standard vector addition will result in another vector in the same space. This can be a good choice for representing a sentence using individual word embeddings.
NOTE: There are other methods of combining word embeddings such as a weighted sum with tf-idf weights OR just directly using sentence embeddings with an algorithm called Doc2Vec. Read more about this here.
2. Similarity between word vectors / sentence vectors
“You shall know a word by the company it keeps”
Words that occur with words (context) are usually similar in semantics/meaning. The great thing about word2vec is that words vectors for words with similar context lie closer to each other in the euclidean space. This lets you do stuff like clustering or just simple distance calculations.
![enter image description here]()
A good way to find how similar 2 words vectors is cosine-similarity. Read more here.
3. Pre-trained word2vec models (and others)
The awesome thing about word2vec and such models is that you don't need to train them on your data for most cases. You can use pre-trained word embedding that has been trained on a ton of data and encodes the contextual/semantic similarities between words based on their co-occurrence with other words in sentences.
You can check similarity between these sentence embeddings using cosine_similarity
4. Sample code implementation
I use a glove model (similar to word2vec) which is already trained on wikipedia, where each word is represented as a 50-dimensional vector. You can choose other models than the one I used from here - https://github.com/RaRe-Technologies/gensim-data
from scipy import spatial
import gensim.downloader as api
model = api.load("glove-wiki-gigaword-50") #choose from multiple models https://github.com/RaRe-Technologies/gensim-data
s0 = 'Mark zuckerberg owns the facebook company'
s1 = 'Facebook company ceo is mark zuckerberg'
s2 = 'Microsoft is owned by Bill gates'
s3 = 'How to learn japanese'
def preprocess(s):
return [i.lower() for i in s.split()]
def get_vector(s):
return np.sum(np.array([model[i] for i in preprocess(s)]), axis=0)
print('s0 vs s1 ->',1 - spatial.distance.cosine(get_vector(s0), get_vector(s1)))
print('s0 vs s2 ->', 1 - spatial.distance.cosine(get_vector(s0), get_vector(s2)))
print('s0 vs s3 ->', 1 - spatial.distance.cosine(get_vector(s0), get_vector(s3)))
#Semantic similarity between sentence pairs
s0 vs s1 -> 0.965923011302948
s0 vs s2 -> 0.8659112453460693
s0 vs s3 -> 0.5877998471260071