Both tfidf vectorizer and transformer are same but differ only in Normalization step.
tfidf transformer perform that extra step called "Normalization" to make all the values within the 0 to 1 range,where as tfidf vectorizer doesnot perform the Normalization step.
For Normalizing purpose tfidf transformer uses the "Norm" like Euclidean Norm(L2).
Example:
tf-idf = [4,0.2,0]
Above vector was obtained after calculated the term-frequency(tf) and inverse document frequency(idf).
NOTE:The above vector is obtained in tfidf vectorizer also.but tfidf vectorizer stop process after getting the above vector
Here we are using the Euclidean Norm to do the Normalization.
Formula for Euclidean Norm to do Normalization
= [4,0.2,0]
---------------------
sqrt(4^2 + 0.2^2 + 0)
=[1,0.05,0]
So the above vector is the normalized vector which is computed by the tfidf transformer.
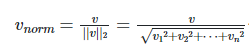{kind=link}