I have converted a Keras model into a Core ML model using coremltools. The original Keras model has the following architecture:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
word_embeddings (InputLayer) (None, 30) 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 30, 256) 12800000 input_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 30, 256) 0 embedding[0][0]
__________________________________________________________________________________________________
bi_lstm_0 (Bidirectional) (None, 30, 1024) 3149824 activation_1[0][0]
__________________________________________________________________________________________________
bi_lstm_1 (Bidirectional) (None, 30, 1024) 6295552 bi_lstm_0[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 30, 2304) 0 bi_lstm_1[0][0]
bi_lstm_0[0][0]
activation_1[0][0]
__________________________________________________________________________________________________
attlayer (AttentionWeightedAver (None, 2304) 2304 concatenate_1[0][0]
__________________________________________________________________________________________________
softmax (Dense) (None, 64) 147520 attlayer[0][0]
==================================================================================================
I can run inferences against the model in Keras/Python with the following input:
model.predict(tokenized)
# where tokenized = [[ 13 93 276 356 11 2469 18 144 453 269 11 0 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0]]
# of class 'numpy.ndarray' and shape (1, 30)
However, after conversion, my Core ML model shows the following shape for the input layer.
input {
name: "word_embeddings"
type {
multiArrayType {
shape: 1
dataType: FLOAT32
}
}
}
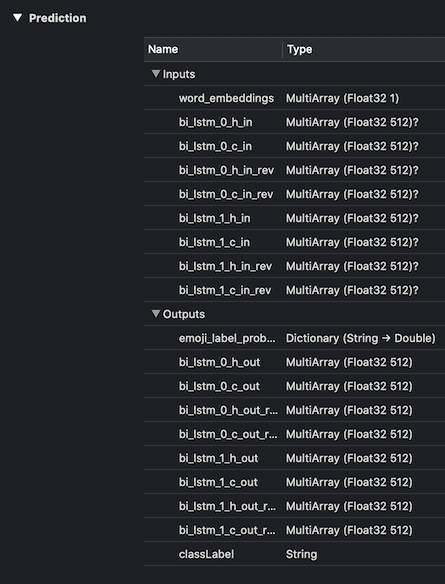
Why has the input layer (word_embeddings) lost its shape after Core ML conversion? I would expect its type to show MultiArray (Float32 1 x 30). Ideally, I would like to be able to pass in a full 30-element vector as I did previously.
I've read Apple's Core ML LSTM doc which suggests that I may need to repeatedly call model.prediction(..) with a single element at a time, capturing the output states of each prediction and passing them in as input to the next until I've reached the end of the full sequence (all 30 elements). Alternatively, could I leverage the Core ML Batch API to make this easier?
Is this necessary?
For context, the model takes a "sentence", that is, a list of 30 words (tokenized to unique integers) and outputs an "emoji" classification, one of 64 possible values.
Conversion running in Colab with coremltools == 3.3 with keras == 2.3.1 and Python 2.7.17.