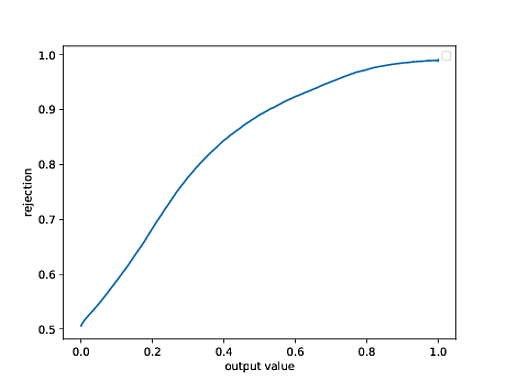
I have a plot generated using Matplotlib (it is a precision-recall curve of a histogram originally) and I need to compute the correct x value which corresponds to the y value with y = 0.9. The data are loaded from text files which are present in columns. This is the code which is used to create the plot:
import numpy as np
import matplotlib.pyplot as plt
import pylab
from sklearn import metrics
data1 = np.loadtxt('text1.txt')
data2 = np.loadtxt('text2.txt')
background = 1 - (1 + y) / 2.
signal = 1 - (1 + x) / 2.
classifier_output = np.concatenate([background,signal])
true_value = np.concatenate([np.zeros_like(background, dtype=int), np.ones_like(signal, dtype=int)])
precision, recall, threshold = metrics.precision_recall_curve(true_value, classifier_output)
plt.plot(threshold, precision[:-1])
plt.savefig('Plot.pdf', dpi = 2000)
plt.show()
Is there any way to compute the correct value on the x axis which corresponds to y = 0.9?
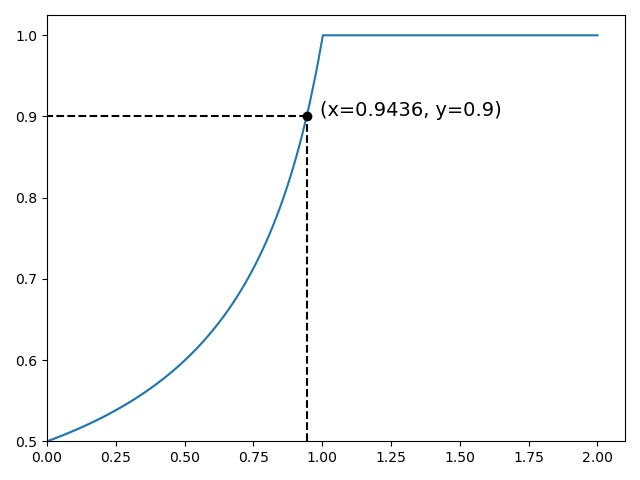
find_rootsfunction from this post.z = find_roots(threshold, precision[:-1] - 0.9)– Nicolenicoleanumpy.interp(0.9, y, x)should give you the x value at y=0.9 in case that is desired. – Fruition