How does one create a one-to-one relationship in SQL Server?
Short answer: You can't.
Long answer: You can, if you dare to read on...
I understand there are two main approaches for "implementing" 1:1 relationships when deferrable constraints are not supported by a DBMS (*cough* MS SQL Server *cough*). This post discusses those 2 main approaches.
Both of these approaches have some degree of compatibility with EF by tricking EF into treating a VIEW as a TABLE. If you aren't using EF then you probably don't need the VIEW objects, but they're still handy for convenience queries and for quickly querying a product type view of your 1:1 entities in separate tables.
Both of these approaches are built around using another table (ValidCountries) which contains only PK values, and exists for 2 reasons:
- To have FK constraints to both of the
1:1 member tables (don't forget you can also have three or more 1:1 tables too!): so a row in ValidCountries cannot exist unless all required related data exists in their respective tables.
- To provide a target for any incoming
FOREIGN KEY constraints from other entities. This is explained in more detail and demonstrated below.
The two approaches differ in their constraints on the 1:1 member tables, their use of TRIGGER objects, and their compatibility with EF. I'm sure more variations on these 2 approaches are possible - it really depends on how you modelled your data and your business requirements.
Neither of these approaches use CHECK CONSTRAINT rules with UDFs to validate data in other tables, which is currently the predominant way to implement 1:1 constraints, but that approach has a poor reputation for performance.
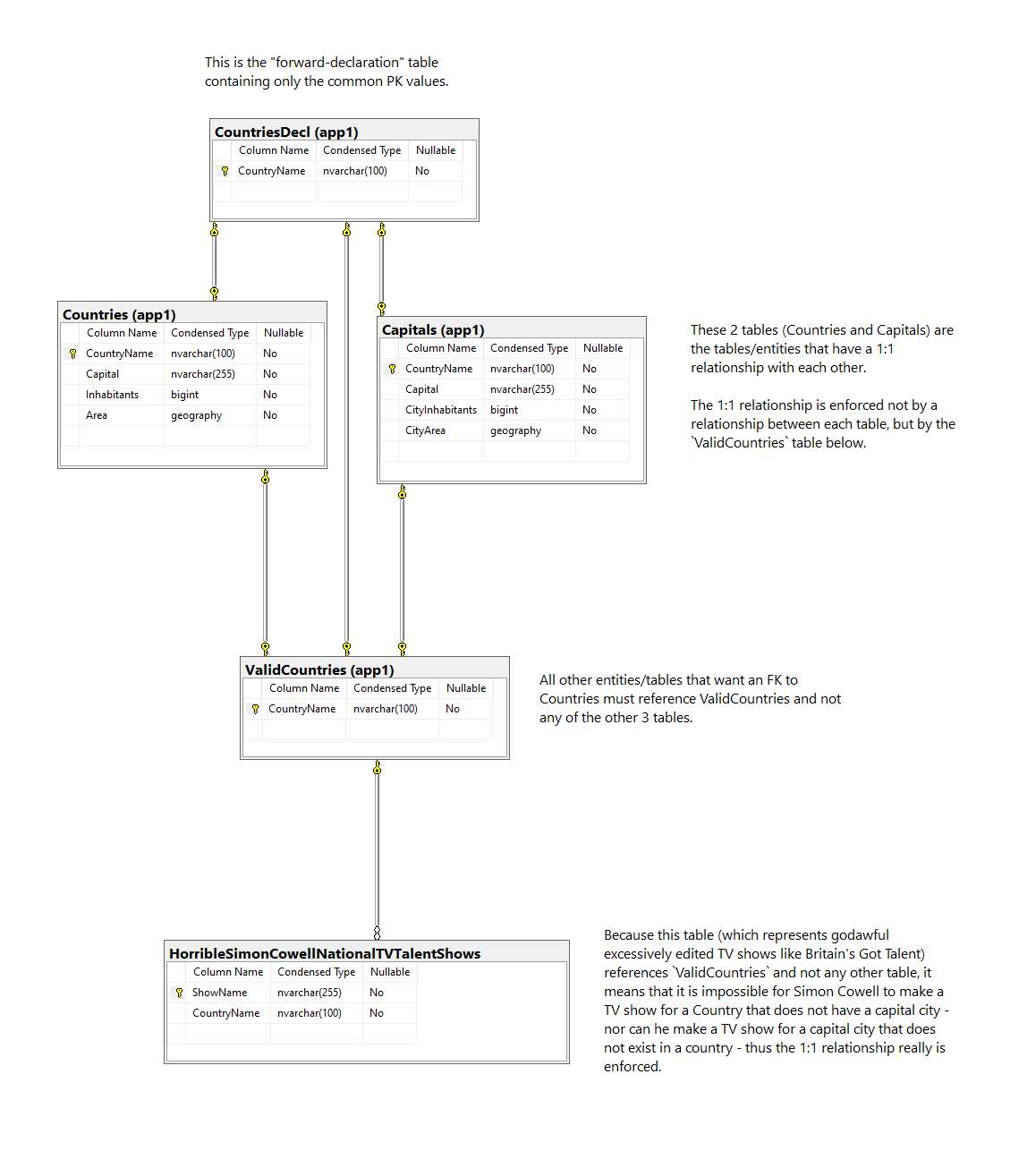
Approach 1: Use two more TABLE objects (one for forward-declarations, the other as proof-of-validity), and a read/write VIEW to expose only valid 1:1 data from a JOIN:
This approach uses a third table to "forward-declare" only the (shared) PK values, while other tables that want a 1:1 relationship with each other reference only the forward-declaration table.
Another "final" TABLE is used to prove (via FK constraints) that for any given PK, that valid definitely exists.
This complexity is then hidden behind an (technically optional) VIEW object which exposes only valid data and performs an INNER JOIN of the 3 (or more) backing tables, while also supporting INSERT/UPDATE/DELETE/MERGE DML operations.
- This works great with Entity Framework as EF is perfectly happy to pretend that a
VIEW is a TABLE. A caveat is that all these approaches are strictly database-first because all these approaches outsmart EF to bend it to our will (so be sure to disable migrations!)
- While the "final" table might seem superfluous as the
VIEW won't ever expose invalid data, it's actually quite necessary to serve as a target for incoming foreign-key references from other separate entity tables (which must never reference the forward-declarations table).
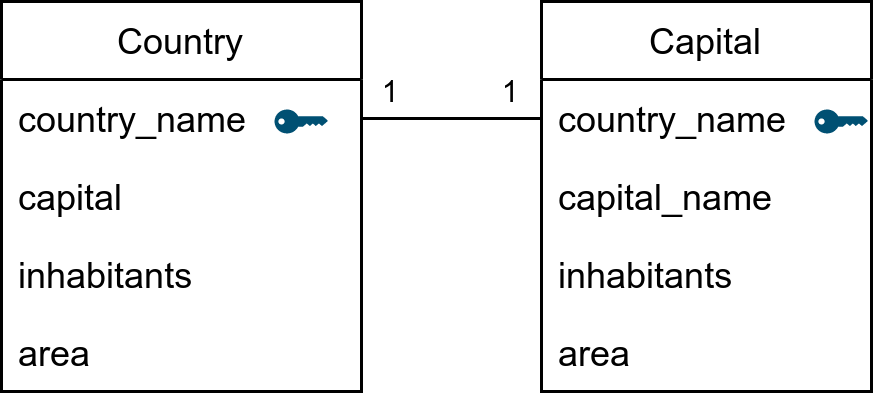
The three tables are:
- Table 1: The "forward-declaration table" with only the PK value.
- In the OP's example (of
Countries and Capitals), this would be a table named like CountryDeclarations (or CountryDecl for short) and stores only CountryName values, which is the shared PK for both the Countries and Capitals tables).
- Table 2: One (or more!) dependent tables with FKs to the forward-declaration table.
- In the OP's example this would be 2 tables:
TABLE Countries with CountryName as the table's PK and its FK to only the forward-declaration table.TABLE Capitals with CountryName as the table's PK and its FK to only the forward-declaration table.
- Table 3: The publicly-visible principal table, which has FKs to the forward-declaration table and all dependent tables.
- In the OP's example this would be
TABLE ValidCountries with a PK + FK to CountryDecl and separate FK columns to Countries and Capitals.
Here's a database-diagram of this approach:
![enter image description here]()
When querying data from the Countries and/or Capitals tables, provided provided you always INNER JOIN with ValidCountries then you get hard guarantees that you're always querying valid data.
- Or just use the
VIEW to get the JOIN already-done for you.
Remember that the 1:1 relationship is not enforced between the constituent Countries and Capitals tables: this is necessary otherwise there would be a chicken vs. egg problem on INSERT.
- Though if you're sure you'll always
INSERT into Countries before Capitals (and DELETE in the reverse order) you could add an FK constraint from Capitals directly to Countries, but this doesn't really add any benefits because the Countries table cannot provide guarantees that a corresponding Capitals row will exist.
This design is compatible with IDENTITY PKs too, just remember that only the forward-declaration table will have the IDENTITY column, all other tables will have normal int PK+FK columns.
Here's the SQL for this approach:
CREATE SCHEMA app1; /* The `app1` schema contains the individual objects to avoid namespace pollution in `dbo`. */
GO
CREATE TABLE app1.CountryDecl (
CountryName nvarchar(100) NOT NULL,
CONSTRAINT PK_CountryDecl PRIMARY KEY ( CountryName )
);
GO
CREATE TABLE app1.Countries (
CountryName nvarchar(100) NOT NULL,
CapitalName nvarchar(255) NOT NULL,
Inhabitants bigint NOT NULL,
AreaKM2 bigint NOT NULL,
CONSTRAINT PK_Countries PRIMARY KEY ( CountryName ),
CONSTRAINT FK_CountriesDecl FOREIGN KEY ( CountryName ) REFERENCES app1.CountryDecl ( CountryName ),
-- CONSTRAINT FK_Countries_Capitals FOREIGN KEY ( CountryName ) REFERENCES app1.Capitals ( CountryName ) -- This FK is entirely optional and adds no value, imo.
);
GO
CREATE TABLE app1.Capitals (
CountryName nvarchar(100) NOT NULL,
CapitalName nvarchar(255) NOT NULL,
Inhabitants bigint NOT NULL,
AreaKM2 int NOT NULL,
CONSTRAINT PK_Capitals PRIMARY KEY ( CountryName ),
CONSTRAINT FK_CountriesDecl FOREIGN KEY ( CountryName ) REFERENCES app1.CountryDecl ( CountryName )
);
GO
CREATE TABLE app1.ValidCountries (
CountryName nvarchar(100) NOT NULL,
CONSTRAINT PK_ValidCountries PRIMARY KEY ( CountryName ),
CONSTRAINT FK_ValidCountries_to_Capitals FOREIGN KEY ( CountryName ) REFERENCES app1.Capitals ( CountryName ),
CONSTRAINT FK_ValidCountries_to_Countries FOREIGN KEY ( CountryName ) REFERENCES app1.Countries ( CountryName ).
CONSTRAINT FK_ValidCountries_to_Decl FOREIGN KEY( CountryName ) REFERENCES app1.CountriesDecl ( CountryName )
);
GO
CREATE VIEW dbo.Countries AS
SELECT
-- ValidCountries:
v.CountryName,
-- Countries
cun.Inhabitants AS CountryInhabitants,
cun.Area AS CountryArea,
-- Capitals
cap.Capital AS CapitalCityName,
cap.CityArea AS CapitalCityArea,
cap.CityInhabitants AS CapitalCityInhabitants
FROM
app1.ValidCountries AS v
INNER JOIN app1.Countries AS cun ON v.CountryName = cun.CountryName
INNER JOIN app1.Capitals AS cap ON v.CountryName = cap.CountryName;
GO
CREATE TRIGGER Countries_Insert ON dbo.Countries
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO app1.CountriesDecl (
CountryName
)
SELECT
CountryName
FROM
inserted;
-------
INSERT INTO app1.Capitals (
CountryName,
Capital,
CityInhabitants,
CityArea
)
SELECT
CountryName,
CapitalCityName,
CapitalCityInhabitants,
CapitalCityArea
FROM
inserted;
-------
INSERT INTO app1.Countries (
CountryName,
Capital,
Inhabitants,
Area
)
SELECT
CountryName,
CapitalCityName,
CountryInhabitants,
CountryArea
FROM
inserted;
----
INSERT INTO app1.ValidCountries (
CountryName
)
SELECT
CountryName
FROM
inserted;
-------
END;
/* NOTE: Defining UPDATE and DELETE triggers for the VIEW is an exercise for the reader. */
- When using Entity Framework and Entity Framework Core, remember that approaches like these are ultimately about outsmarting Entity Framework (if not outright hacks), so it's important that you don't ever let EF perform any migrations or generate and run any DDL (
CREATE TABLE...) statements based on your Code-First entity model classes.
While EF no-longer supports "Database-first" models, you can still use "Code-first from Database" with code-first code-gen like https://github.com/sjh37/EntityFramework-Reverse-POCO-Code-First-Generator (disclaimer: this is my personal favourite code-gen and I'm a contributor to that project).
If you run default scaffolding or code-first-codegen on a database using this approach dthen you'll end up with a model containing separate entities for app1.Countries, app1.Capitals, app1.CountriesDecl and app1.ValidCountries - so you should configure your code-gen to filter-out those objects you don't want in your EF model.
- In this case, I'd exclude all
app1.* tables from EF, and instead instruct EF to treat VIEW dbo.Countries as a single entity (which makes sense, as mathematically every 1:1 relationship between 2 entities is the same thing as a single entity defined as a Product Type of those 2 other entities).
- Because a
VIEW does not have a PRIMARY KEY nor any FOREIGN KEY constraints, EF (by default) cannot correctly codegen an entity class from a VIEW, but the aforementioned code-gen tool makes it easy to nudge EF in the right ways (look for the ViewProcessing method, and AddForeignKeys method below it).
If you do retain the app1.Countries and app1.Capitals tables as entity types in EF, be aware that having EF perform an INSERT into those two tables will fail unless your code first does an INSERT into app1.CountriesDecl.
Or you could add a CREATE TRIGGER Countries/Capitals_Insert ON app1.Countries/app1.Capitals INSTEAD OF INSERT which will perform the IF NOT EXIST ... INSERT INTO app1.CountriesDecl.
However EF won't have any problems with UPDATE and DELETE on those 2 tables, at least.
Approach 2: Only a single extra TABLE object, but the FK columns are NULL-able - and a VIEW is used as a curtain to hide invalid/incomplete rows.
If Approach 1 can be summarized as borrowing ideas from the "objects must always be immutable" school-of-thought, then Approach 2 is inspired by languages that allow you to mutate an existing object in-place such that the compiler can verify that each mutation step alters the effective type of the object such that it satisfies some type-constraint.
For example, consider this pseudo-TypeScript (because as of 2022, TypeScript still doesn't seem to support/detect when adding properties to a POJsO (thus extending its structural type) is valid and provably extends a variable's static type):
interface MyResult { readonly name: string; readonly year: number; };
function doSomething() : MyResult {
let result = {};
// return result; // Error: Cannot return `result` yet: it doesn't conform to `MyResult` (there's no `name` nor `year` value)
result.name = "NameGoesHere"; // So let's define `name`.
// return result; // ERROR: Still cannot return `result` yet: it still doesn't yet have a `year` property.
result.year = 2022; // So let's add `year`.
return result; // No error, `result` can now be returned OK because it conforms to `interface MyResult`.
}
With that concept in-mind, we can have TABLE objects that holds partial/incomplete Country and Capital data which we can freely insert/update/delete because their mutual FOREIGN KEY constraints are NULL-able, see below.
- The tables are named
dbo.CountriesData and dbo.CapitalsData instead of dbo.Countries and dbo.Capitals respectively to indicate that the tables only contain arbitrary "data" rather than valid and correct entities. This is a personal naming-convention of mine. YMMV.
- As with Approach 1, the
VIEW dbo.Countries exists which exposes only valid entities as a single product type.
- Optionally you could also define additional
VIEW objects for Countries and Capitals separately and do the work to make EF treat those as Entities too (though you'll need to do loads more legwork to make INSERT work for each view individually).
But unlike with Approach 1, the dbo.CapitalsData table now has a composite primary-key, which is a consequence of the OP's specific database design objectives - this might not apply to your database.
- The composite-PK is necessary to allow
dbo.Countries to have a non-NULL CountryName value while not having the FK_CountriesData_to_Capitals constraint enforced. This is necessary because CountryName is also the PK of dbo.CountriesData, so it cannot be NULL. This works because SQL Server only enforces FK constraints when all columns in an FK are non-NULL. If you have a different PK design then this will be different for you.
CREATE TABLE dbo.CountriesData (
CountryName nvarchar(100) NOT NULL,
CapitalName nvarchar(255) NULL,
Inhabitants bigint NOT NULL,
Area geography NOT NULL,
CONSTRAINT PK_CountriesData PRIMARY KEY ( CountryName ),
CONSTRAINT FK_CountriesData_to_Capitals FOREIGN KEY ( CountryName, CapitalName ) REFERENCES dbo.CapitalsData ( CapitalName )
);
CREATE TABLE dbo.CapitalsData (
CountryName nvarchar(100) NOT NULL,
CapitalName nvarchar(255) NOT NULL,
Inhabitants bigint NOT NULL,
Area geography NOT NULL,
CONSTRAINT PK_CapitalsData PRIMARY KEY ( CountryName, CountryName ),
CONSTRAINT FK_CapitalssData_to_Countries FOREIGN KEY ( CapitalName ) REFERENCES dbo.CountriesData ( CountryName )
);
CREATE VIEW dbo.Countries AS
SELECT
-- Countries
cun.Inhabitants AS CountryInhabitants,
cun.Area AS CountryArea,
-- Capitals
cap.Capital AS CapitalCityName,
cap.CityArea AS CapitalCityArea,
cap.CityInhabitants AS CapitalCityInhabitants
FROM
dbo.CountriesData AS cd
INNER JOIN dbo.CapitalsData AS cad ON cd.CountryName = cad.CountryName;
CREATE TABLE dbo.ValidCountries (
-- This TABLE is largely the as in Approach 1. Ensure that all incoming FKs only reference this table and not dbo.CountriesData or dbo.CapitalsData.
-- NOTE: When using EF, provided to trick EF into treating `VIEW dbo.Countries` as a TABLE then you don't need to include this table in your EF model at all (just be sure to massage all of EF's FK relationships from other entities that initially point to `ValidCountries` to point to the `VIEW dbo.Countries` entity instead.
CountryName nvarchar(100) NOT NULL,
CapitalName nvarchar(255) NOT NULL,
CONSTRAINT PK_ValidCountries PRIMARY KEY ( CountryName ),
CONSTRAINT FK_ValidCountries_to_Capitals FOREIGN KEY ( CountryName ) REFERENCES dbo.CapitalsData ( CountryName, CapitalName ),
CONSTRAINT FK_ValidCountries_to_Countries FOREIGN KEY ( CountryName ) REFERENCES dbo.CountriesData ( CountryName )
);
CREATE TRIGGER After_UPDATE_in_CountriesData_then_INSERT_into_ValidCountries_if_valid ON dbo.CountriesData
AFTER UPDATE
AS
BEGIN
INSERT INTO dbo.ValidCountries ( CountryName, CapitalName )
SELECT
i.CountryName,
i.CapitalName
FROM
inserted.CountryName AS i
INNER JOIN dbo.CapitalsData AS capd ON -- The JOINs prevents inserting CountryNames for countries that are either invalid or already exist in dbo.ValidCountries.
capd.CountryName = i.CountryName
AND
capd.CapitalName = i.CapitalName
LEFT OUTER JOIN dbo.ValidCountries AS v ON -- This is a "LEFT ANTI JOIN" due to the WHERE condition below.
v.CountryName = i.CountryName
WHERE
v.CountryName IS NULL
AND
i.CapitalName IS NOT NULL;
END;
CREATE TRIGGER After_INSERT_in_CapitalsData_then_SET_C ON dbo.CapitalsData
AFTER INSERT
AS
BEGIN
-- Due to the specific design of dbo.CapitalsData, any INSERT will necessarily complete a valid product-type entity, so we can UPDATE dbo.CountriesData to set CapitalName to the correct value.
UPDATE
cd
SET
cd.CapitalName = inserted.CapitalName
FROM
dbo.CountriesData AS cd
INNER JOIN inserted AS i ON
cd.CountryName = i.CountryName
AND
cd.CapitalName IS NULL
WHERE
i.CountryName IS NOT NULL;
END;
- For manual DML:
- To
INSERT a new Country...
- First
INSERT INTO dbo.CountriesData with an initially NULL CapitalName value.
- This is okay because SQL Server ignores FK constraints when its value (or when at least 1 value in a composite FK) is
NULL.
- Then
INSERT INTO dbo.CapitalsData (or vice-versa, provided CountryName is conversely NULL).
- Only after both rows are inserted do you then run
UPDATE dbo.CountriesData SET CapitalName = inserted.CapitalName WHERE CountryName = inserted.CountryName.
- Whereupon your
VIEW dbo.Countries will now expose the now-valid 1:1-related data.
DELETE operations must be performed in reverse-order (i.e. first UPDATE to clear the FKs, then DELETE from each table, in any order).UPDATE operations require no special handling.
- I note that you could actually move all the above
INSERT logic into an AFTER INSERT trigger on both CountriesData and CapitalsData tables, as this means:
- That
UPDATE into an AFTER INSERT trigger on dbo.CapitalsData! (and vice-versa) - but be sure to also add the check that WHERE inserted.CountryName IS NOT NULL - but if you do that then your client's SQL code only needs to do two INSERT statements and one of the two AFTER INSERT triggers will handle the rest automatically, but only if the data is finally valid - whereupon it will be visible in VIEW dbo.Countries.
- This approach plays nicer with EF, as you don't need to faff around with the
CountriesDecl table, so doing individual INSERT ops into dbo.CountriesData and dbo.CapitalsData won't fail - but remember that there's no 1:1 relationship between those two tables/entities.

NOT NULL, absolutely-required) columns needs more columns added but it's too wide for the RDBMS (e.g. SQL Server's 8KB row length limit). If we haveTABLE People(withPersonId PRIMARY KEY) then we can add a new tableTABLE PeopleEx(withPK + FKoverPeopleEx.PersonId) to hold the new columns, but there's no way to enforce/require every row inPeopleto have a row inPeopleEx. – DepravitySUMand further schema changes would be impossible. Haven't you read Codd's paper on why RDMBS systems exist in the first place? – Depravitynvarchar(n)columns with very commonnvalues (e.g. ~200-1000). While you can usenvarchar(max)for off-table storage, that has a significant impact on performance and so is unsuitable for columns that will be frequently used in queries. It's also not uncommon to have thousands of columns. Or anything like 1,000bigintcolumns, or 800datetimeoffsetcolumns, or just 285decimalcolumns. Hitting the row-size limit happens a lot. – Depravity