I have a DataFrame with the following columns.
scala> show_times.printSchema
root
|-- account: string (nullable = true)
|-- channel: string (nullable = true)
|-- show_name: string (nullable = true)
|-- total_time_watched: integer (nullable = true)
This is data about how many times customer has watched watched a particular show. I'm supposed to categorize the customer for each show based on total time watched.
The dataset has 133 million rows in total with 192 distinct show_names.
For each individual show I'm supposed to bin the customer into 3 categories (1,2,3).
I use Spark MLlib's QuantileDiscretizer
Currently I loop through every show and run QuantileDiscretizer in the sequential manner as in the code below.
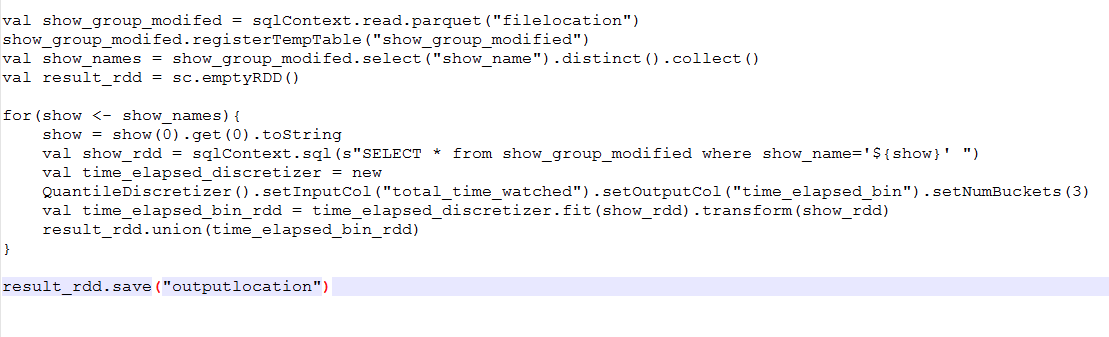
What I'd like to have in the end is for the following sample input to get the sample output.
Sample Input:
account,channel,show_name,total_time_watched
acct1,ESPN,show1,200
acct2,ESPN,show1,250
acct3,ESPN,show1,800
acct4,ESPN,show1,850
acct5,ESPN,show1,1300
acct6,ESPN,show1,1320
acct1,ESPN,show2,200
acct2,ESPN,show2,250
acct3,ESPN,show2,800
acct4,ESPN,show2,850
acct5,ESPN,show2,1300
acct6,ESPN,show2,1320
Sample Output:
account,channel,show_name,total_time_watched,Time_watched_bin
acct1,ESPN,show1,200,1
acct2,ESPN,show1,250,1
acct3,ESPN,show1,800,2
acct4,ESPN,show1,850,2
acct5,ESPN,show1,1300,3
acct6,ESPN,show1,1320,3
acct1,ESPN,show2,200,1
acct2,ESPN,show2,250,1
acct3,ESPN,show2,800,2
acct4,ESPN,show2,850,2
acct5,ESPN,show2,1300,3
acct6,ESPN,show2,1320,3
Is there a more efficient and distributed way to do it using some groupBy-like operation instead of looping through each show_name and bin it one after other?