This question already has several great answers. Although the question is now old, I faced this problem today, so I feel that perhaps this answer can help.
S3 has two kinds of end points, and if you are facing this error, you have probably selected the S3 bucket directly as the endpoint in the Origin Domain Name field for your CloudFront Distribution.
This would look something like: bucket-name.s3.amazonaws.com and is a perfectly valid endpoint. In fact, it would seem that AWS does expect this as default behaviour; this entry will be in the drop-down list you have when you are creating your CloudFront distribution.
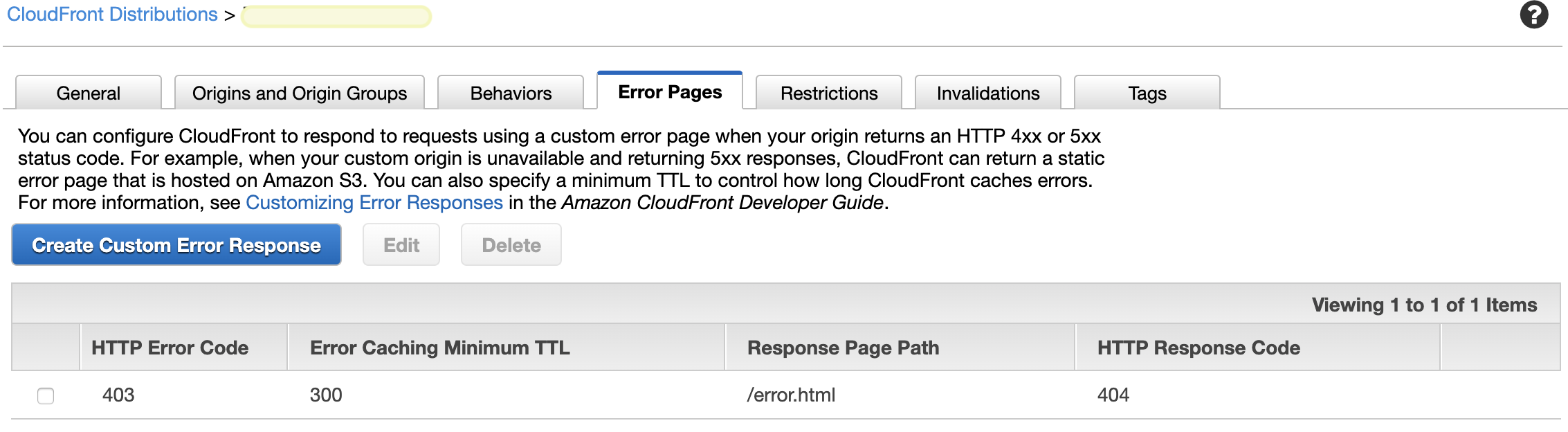
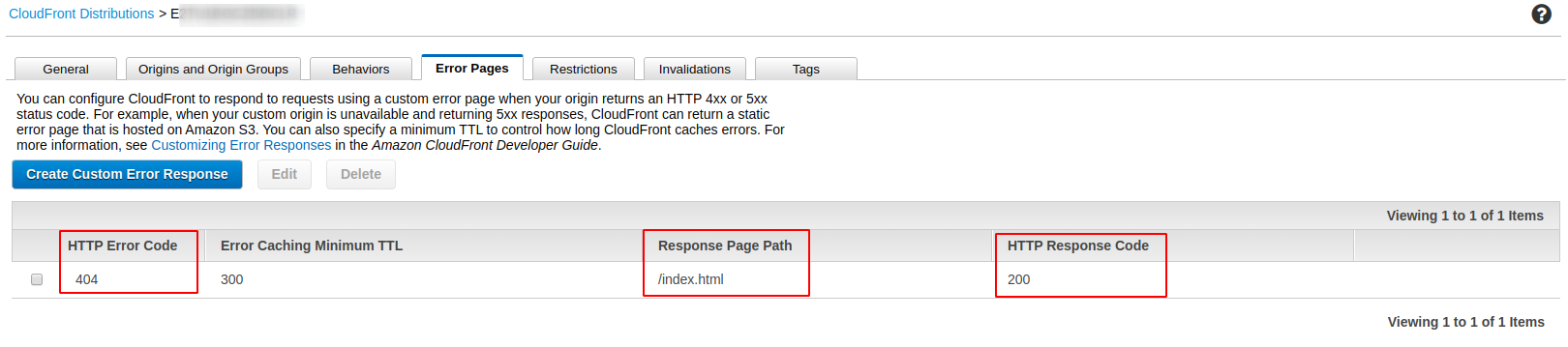
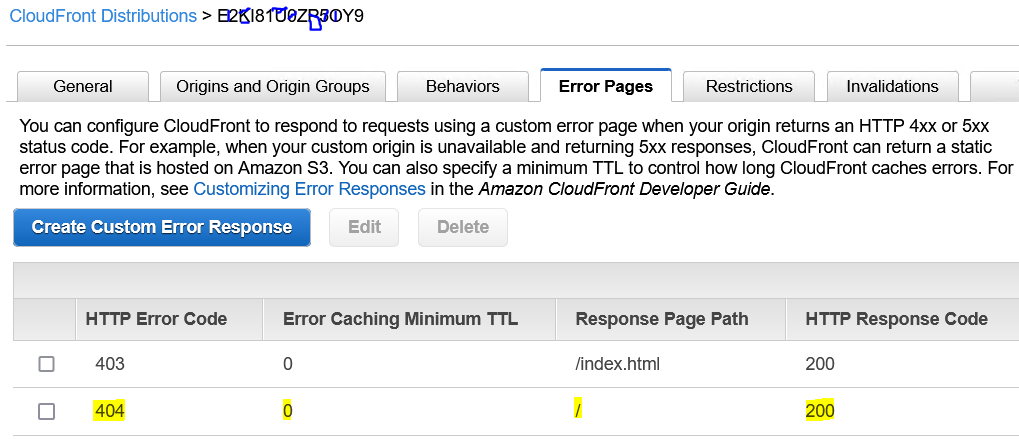
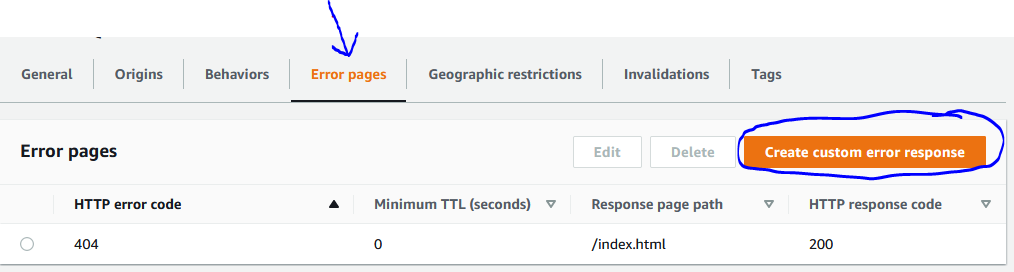
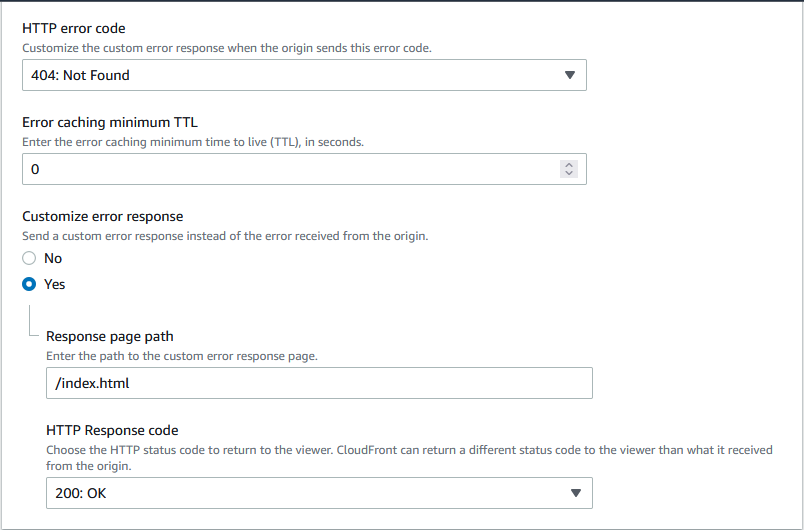
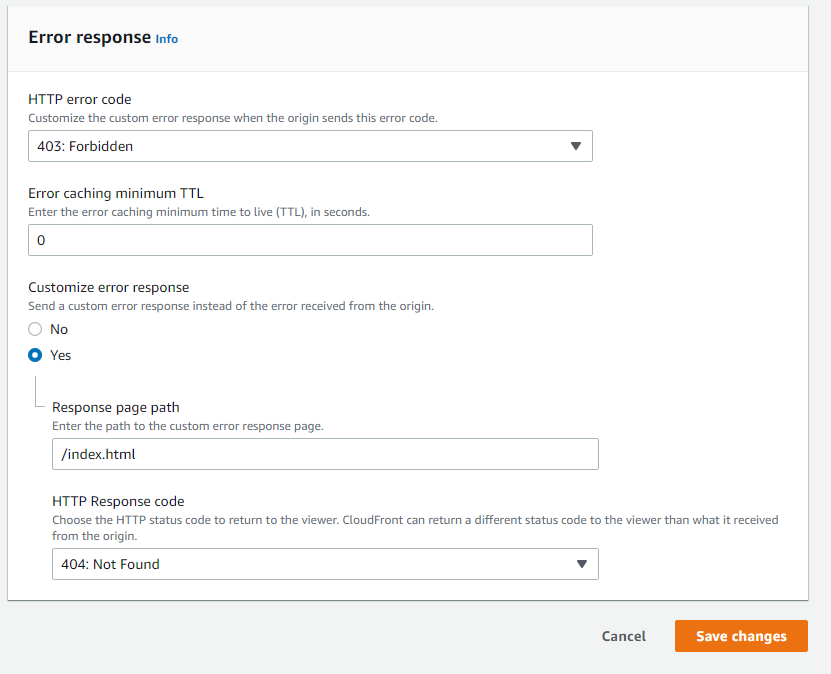
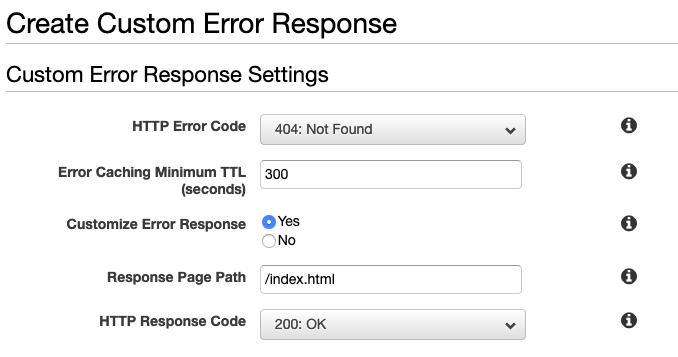
However, doing this and then setting error pages may or may not solve your problem.
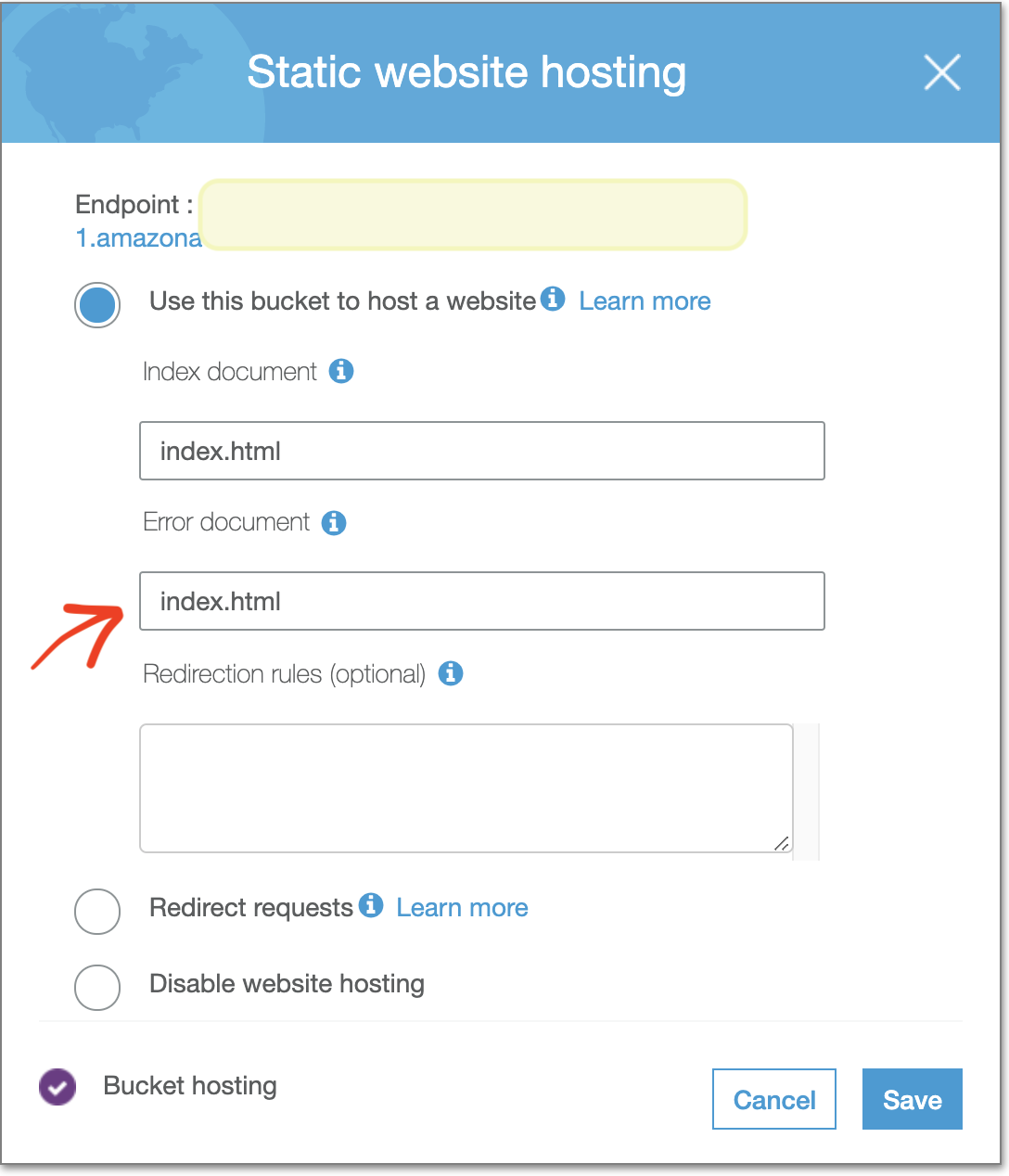
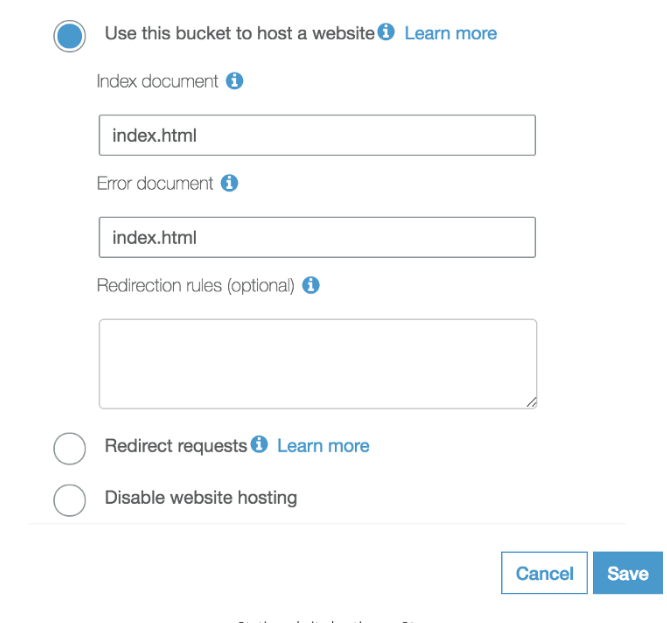
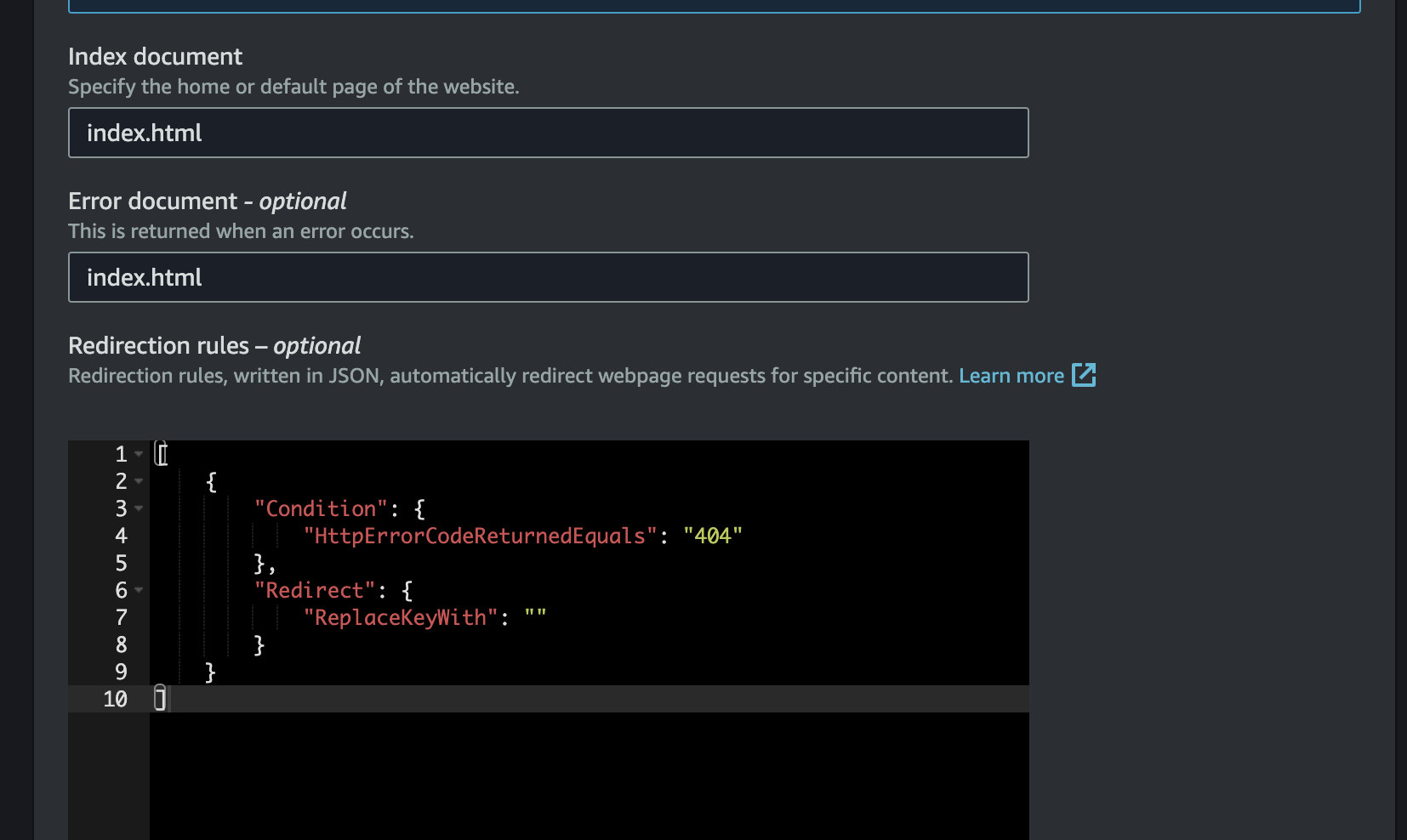
S3 has, however, a dedicated Website Endpoint. This is accessible from your S3 Bucket > Properties > Static Website Hosting. (You will see the link on the top).
You should use this link instead of the original auto-populated link that comes up in CloudFront. You can put this in while creating your distribution, or after creation, you can edit from the tab Origins and Origins Groups, and then invalidating caches.
This link will look like: bucket-name.s3-website.region-name.amazonaws.com.
Once this propagates and changes, this should then fix your problem.
tl;dr: Don't use the default S3 endpoint in CloudFront. Use the S3 website endpoint instead. Your origin domain should look like this: my-application.s3-website.us-east-1.amazonaws.com and not like my-application.s3.amazonaws.com.
More Information about website endpoints is available in the AWS Documentation here.
{kind=link}
{kind=link}
{kind=link}
index.htmlandbundle.json any other route than/. It needs to serve those files on all routes. – Accordionindex.html– Clerkbundle.jsis called explicitly wheneverindex.htmlis served. So what you need is to make sure thatindex.htmlis served on any path you expect to support deep-linking, and it will callbundle.jsappropriately. If you don't have a 404 file - make index.html your 404. If you do - use an explicit paths list in your cloudfront behaviors. – Om