One possibility, maybe naïve, is to introduce a sleep in the step. For this you need to know the maximum number of instances of the ParDo that can be running at the same time. If autoscalingAlgorithm is set to NONE you can obtain that from numWorkers and workerMachineType (DataflowPipelineOptions). Precisely, the effective rate will be divided by the total number of threads: desired_rate/(num_workers*num_threads(per worker)). The sleep time will be the inverse of that effective rate:
Integer desired_rate = 1; // QPS limit
if (options.getNumWorkers() == 0) { num_workers = 1; }
else { num_workers = options.getNumWorkers(); }
if (options.getWorkerMachineType() != null) {
machine_type = options.getWorkerMachineType();
num_threads = Integer.parseInt(machine_type.substring(machine_type.lastIndexOf("-") + 1));
}
else { num_threads = 1; }
Double sleep_time = (double)(num_workers * num_threads) / (double)(desired_rate);
Then you can use TimeUnit.SECONDS.sleep(sleep_time.intValue()); or equivalent inside the throttled Fn. In my example, as a use case, I wanted to read from a public file, parse out the empty lines and call the Natural Language Processing API with a maximum rate of 1 QPS (I initialized desired_rate to 1 previously):
p
.apply("Read Lines", TextIO.read().from("gs://apache-beam-samples/shakespeare/kinglear.txt"))
.apply("Omit Empty Lines", ParDo.of(new OmitEmptyLines()))
.apply("NLP requests", ParDo.of(new ThrottledFn()))
.apply("Write Lines", TextIO.write().to(options.getOutput()));
The rate-limited Fn is ThrottledFn, notice the sleep function:
static class ThrottledFn extends DoFn<String, String> {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
// Instantiates a client
try (LanguageServiceClient language = LanguageServiceClient.create()) {
// The text to analyze
String text = c.element();
Document doc = Document.newBuilder()
.setContent(text).setType(Type.PLAIN_TEXT).build();
// Detects the sentiment of the text
Sentiment sentiment = language.analyzeSentiment(doc).getDocumentSentiment();
String nlp_results = String.format("Sentiment: score %s, magnitude %s", sentiment.getScore(), sentiment.getMagnitude());
TimeUnit.SECONDS.sleep(sleep_time.intValue());
Log.info(nlp_results);
c.output(nlp_results);
}
}
}
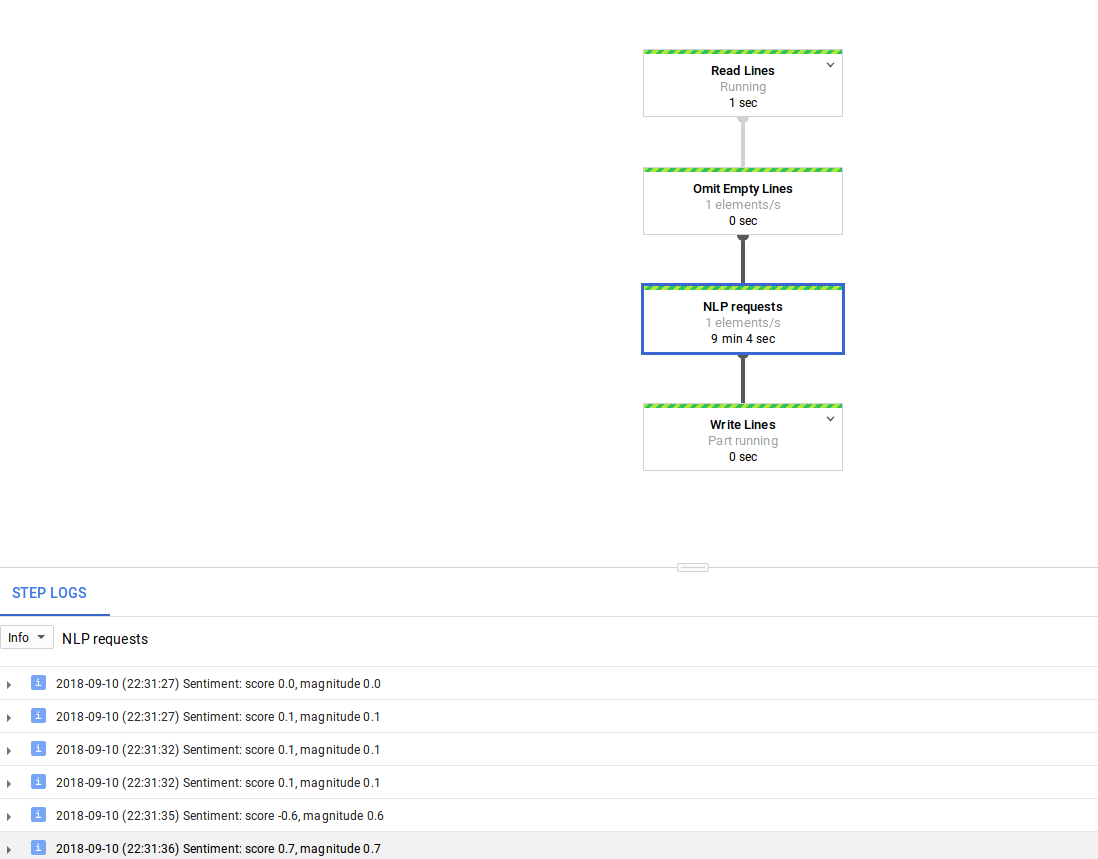
With this I get a 1 element/s rate as seen in the image below and avoid hitting quota when using multiple workers, even if requests are not really spread out (you might get 8 simultaneous requests and then 8s sleep, etc.). This was just a test, possibly a better implemention would be using guava's rateLimiter.
![enter image description here]()
If the pipeline is using autoscaling (THROUGHPUT_BASED) then it would be more complicated and the number of workers should be updated (for example, Stackdriver Monitoring has a job/current_num_vcpus metric). Other general considerations would be controlling the number of parallel ParDos by using a dummy GroupByKey or splitting the source with splitIntoBundles, etc. I'd like to see if there are other nicer solutions.