I want to generate a rank 5 100x600 matrix in numpy with all the entries sampled from np.random.uniform(0, 20), so that all the entries will be uniformly distributed between [0, 20). What will be the best way to do so in python?
I see there is an SVD-inspired way to do so here (https://math.stackexchange.com/questions/3567510/how-to-generate-a-rank-r-matrix-with-entries-uniform), but I am not sure how to code it up. I am looking for a working example of this SVD-inspired way to get uniformly distributed entries.
I have actually managed to code up a rank 5 100x100 matrix by vertically stacking five 20x100 rank 1 matrices, then shuffling the vertical indices. However, the resulting 100x100 matrix does not have uniformly distributed entries [0, 20).
Here is my code (my best attempt):
import numpy as np
def randomMatrix(m, n, p, q):
# creates an m x n matrix with lower bound p and upper bound q, randomly.
count = np.random.uniform(p, q, size=(m, n))
return count
Qs = []
my_rank = 5
for i in range(my_rank):
L = randomMatrix(20, 1, 0, np.sqrt(20))
# L is tall
R = randomMatrix(1, 100, 0, np.sqrt(20))
# R is long
Q = np.outer(L, R)
Qs.append(Q)
Q = np.vstack(Qs)
#shuffle (preserves rank 5 [confirmed])
np.random.shuffle(Q)
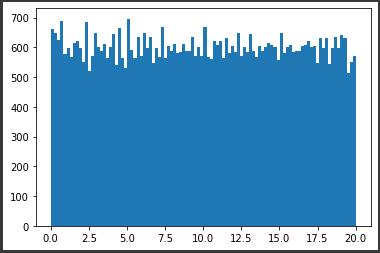
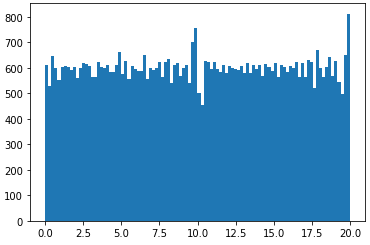
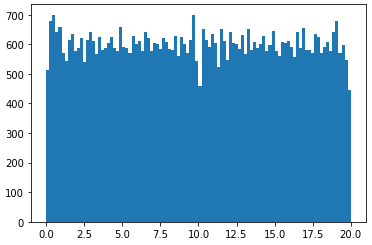
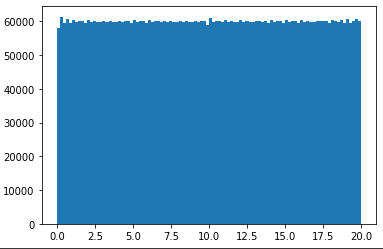

(20**2/12)**0.5 ~= 5.77and there is not values outside the range[0;20)andnp.linalg.matrix_rank(mat)is 5, then this means you succeed to find a quite good solution. A better metric should be to compute the histogram and end then apply basic statistical tests in order to compute a p-value (I guess an Anova should do the job pretty well). usingnp.random.randis almost perfect except the rank is not 5... – StandinN(10, 5.77)works could fit the mean and the SD criteria but not the range. If you truncate the normal distribution, it changes the SD. If you try to tune the parameters of the truncated normal distribution to find one that fit the std-dev of 5.77, you should see that sigma=+inf is a good fit... and the resulting distribution is...U(0, 20);) . Thus, no, the normal distribution will not be considered uniform unless it is nearly so. Very good catch for the Anova! I miss this point. I guess the non-parametric Kruskal-Wallis test should do the job. – Standin