Robert C. Martin always had a rather obscure way of describing things. His points are always very good but require a bit of deciphering -- "afferent vs. efferent coupling", ugh! Another thing about the way Martin writes is that it's always kind of blurred between descriptive and prescriptive ("would" or "should"?)
"Stability"
First it's important to understand how Martin defines "stability". He defines it in terms of afferent and efferent couplings yielding a stability metric:
instability = efferent / (efferent + afferent)
"Afferent" and "efferent" are such obscure terms. For simplicity, let's use "outgoing dependencies" in place of "efferent couplings" and "incoming dependencies" for "afferent couplings". So we have this:
instability = outgoing / (outgoing + incoming)
It's very much divorced from the likelihood of change, and has everything to do with the difficulty of change. As confusing as it is, by this definition, a "stable" package could still be changing all the time (it would be bad and really difficult to manage though, of course).
If you get a divide by zero error with the above formula, then your package is neither being used nor using anything.
Stable Dependencies Principle
To understand Martin's point about SAP in context, it's easier to start with SDP (Stable Dependencies Principle). It states:
The dependencies between packages should be in the direction of the
stability of the packages. A package should only depend upon packages
that are more stable than it is.
That's pretty easy to understand. The cost of changing a design cascades with the number (and complexity) of incoming dependencies to it. Probably anyone who has worked in a large-scale codebase can appreciate this one pretty quickly where a central design change might end up wanting to break 10,000 really complex parts in the codebase.
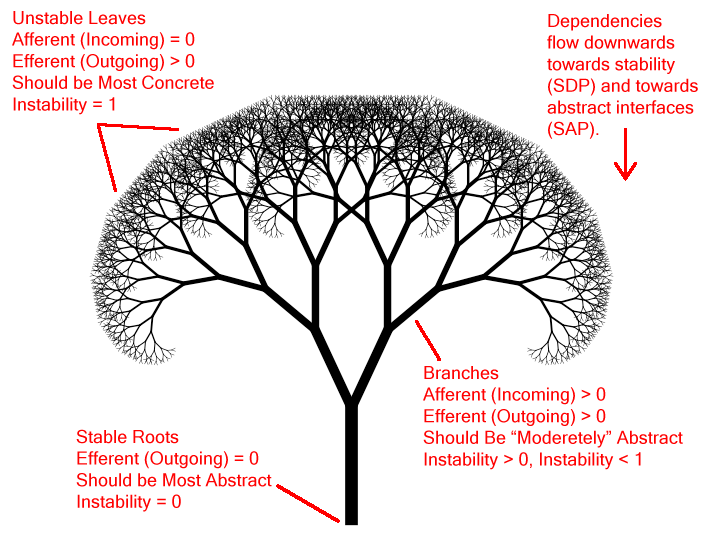
So the dependencies should (would?) flow towards the parts that are unchanging, firmly-rooted, unwavering, like a tree flowing down from its leaves towards its roots.
The stability metrics that the roots should have boil down to zero efferent couplings (zero outgoing dependencies). That is, this stable "root" package should not depend on anything else. In other words, it should be totally independent of the outside world. This is the characteristic that defines "maximum stability" according to Martin's metrics: total independence.
Maximum independence = "stable root" (as I'm calling it)
Maximum dependence = "unstable leaf" (as I'm calling it)
Given this kind of totally-independent, ultra stable root design, how can we still gain back a level of flexibility where we can easily extend and change its implementation without affecting the interface/design? And that's where abstractions come in.
Stable Abstractions Principle
Abstractions allow us to decouple implementation from interface/design.
And thus, here comes the stable abstractions principle:
Packages that are maximally stable should be maximally abstract.
Unstable packages should be concrete. The abstractness of a package
should be in proportion to its stability.
The idea is to allow these central root designs to be ultra-stable, as stated by SDP, while still retaining a degree of flexibility for changes which do not impact the core design through abstraction.
As a simple example, consider a software development kit at the heart of some engine and used by plugin developers worldwide. By definition, this SDK would have to have a very stable design given the combination of numerous incoming dependencies (all these plugin developers using it) against minimal or no outgoing dependencies (the SDK depends on little else). This principle would suggest that its interfaces should be abstract to have the maximum degree of flexibility for change without impacting the stable design.
![Stability Tree]()
"Moderately abstract" here might be an abstract base class. "Maximally abstract" would be a pure interface.
Concrete
On the flip side, with the abstract is a need for the concrete. Otherwise there would be nothing to provide the implementation for an abstraction. So this principle also suggests that the concrete parts should (would?) be the unstable parts. If you imagine this as a tree (inverted from the usual programming tree) with dependencies flowing downwards from leaf to root, the leaves should be the most concrete, the roots should be the most abstract.
The leaves would typically have the most outgoing dependencies (lots of dependencies to things outside -- to all those branches and roots), while they would have zero incoming dependencies (nothing would depend on them). The roots would be opposite (everything depends on them, they depend on nothing).
This is how I've come to understand Martin's descriptions. They are difficult to understand and I may be off on some parts.
Surely in all cases regardless of stability we should be depending
upon abstractions and hiding the concrete implementation?
Perhaps you're thinking more in terms of entities. An abstract interface for an entity would still require a concrete implementation somewhere. The concrete part may be unstable, and would likewise be easier to change since nothing else depends on it directly (no afferent couplings). The abstract part should be stable as many could potentially depend on it (lots of incoming dependencies, few or no outgoing dependencies), and so it would be difficult to change.
At the same time, if you work your way up to a more dependent package like the application package where you have your main entry point for your application where everything is assembled together, to make all the interfaces abstract here would often increase the difficulty of change, and would still transfer the need to have a concrete (unstable) implementation somewhere else. At some point in a codebase, there has to be dependencies to concrete parts, if only to select the appropriate concrete implementation for an abstract interface.
To Abstract or Not to Abstract
I was wondering if anyone knows any disadvantage to depending on
abstractions rather than concretes (i suppose, that outweighs the
advantages).
Performance comes to mind. Typically abstractions have some kind of runtime cost in the form of dynamic dispatch, e.g., which then become susceptible to branch mispredictions. A lot of Martin's writing revolves around classical object-oriented paradigms. Moreover, OOP in general wants to model things at the singular entity kind of level. At the extreme level, it might want to make a single pixel of an image into an abstract interface with its own operations.
In my field, I tend to use entity-component systems with a data-oriented design mindset. This kind of flips the classical OOP world upside down. Structures are often designed to aggregate data for multiple entities at once with a design mindset looking for optimal memory layout (designing for the machine rather than logically for the human). Entities are designed as collections of components, and components are modeled as raw data using a data-oriented mindset. Interfaces still get abstract for systems that process components, but the abstractions are designed to process things in bulk, and the dependencies flow from systems to central components which are not abstract in the slightest.
This is a very common technique employed in game engines and it offers a lot potential in terms of performance and flexibility. Yet it is in stark contrast to the kind of focus Martin places on object-oriented programming, as it is strong departure from OOP overall.