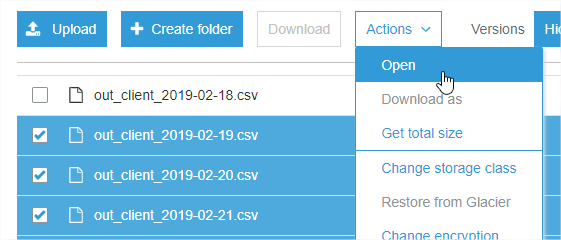
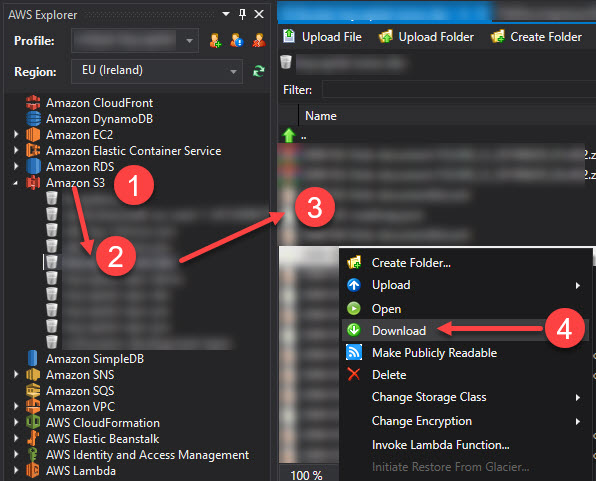
I wrote a simple shell script to download NOT JUST all files but also all versions of every file from a specific folder under AWS s3 bucket. Here it is & you may find it useful
# Script generates the version info file for all the
# content under a particular bucket and then parses
# the file to grab the versionId for each of the versions
# and finally generates a fully qualified http url for
# the different versioned files and use that to download
# the content.
s3region="s3.ap-south-1.amazonaws.com"
bucket="your_bucket_name"
# note the location has no forward slash at beginning or at end
location="data/that/you/want/to/download"
# file names were like ABB-quarterly-results.csv, AVANTIFEED--quarterly-results.csv
fileNamePattern="-quarterly-results.csv"
# AWS CLI command to get version info
content="$(aws s3api list-object-versions --bucket $bucket --prefix "$location/")"
#save the file locally, if you want
echo "$content" >> version-info.json
versions=$(echo "$content" | grep -ir VersionId | awk -F ":" '{gsub(/"/, "", $3);gsub(/,/, "", $3);gsub(/ /, "", $3);print $3 }')
for version in $versions
do
echo ############### $fileId ###################
#echo $version
url="https://$s3region/$bucket/$location/$fileId$fileNamePattern?versionId=$version"
echo $url
content="$(curl -s "$url")"
echo "$content" >> $fileId$fileNamePattern-$version.csv
echo ############### $i ###################
done