Background
I have a MySQL test environment with a table which contains over 200 million rows. On this table have to execute two types of queries;
- Do certain rows exists.
Given a
client_idand a list ofsgtins, which can hold up to 50.000 items, I need to know whichsgtins are present in the table. - Select those rows.
Given a
client_idand a list ofsgtins, which can hold up to 50.000 items, I need to fetch the full row. (store, gtin...)
The table can grow to 200+ millions record for a single 'client_id'.
Test environment
Xeon E3-1545M / 32GB RAM / SSD. InnoDB buffer pool 24GB. (Production will be a larger server with 192GB RAM)
Table
CREATE TABLE `sgtins` (
`client_id` INT UNSIGNED NOT NULL,
`sgtin` varchar(255) NOT NULL,
`store` varchar(255) NOT NULL,
`gtin` varchar(255) NOT NULL,
`timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
INDEX (`client_id`, `store`, `sgtin`),
INDEX (`client_id`),
PRIMARY KEY (`client_id`,`sgtin`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Tests
First I generated random sgtin values spread over 10 'client_id's to fill the table with 200 million rows.
I created a benchmark tool which executes various queries I tried. Also I used the explain plan to find out which performance best. This tool will read, for every test, new random data from the data I used to fill the database. To ensure every query is different.
For this post I will use 28 sgtins.
Temp table
CREATE TEMPORARY TABLE sgtins_tmp_table (`sgtin` varchar(255) primary key)
engine=MEMORY;
Exist query
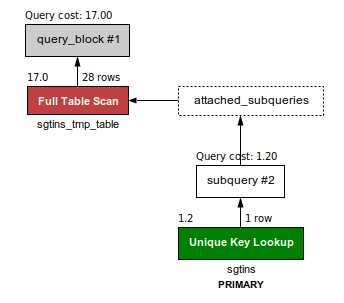
I use this query for find out if the sgtins exist. Also this is the fastest query I found. For 50K sgtins this query will take between 3 and 9 seconds.
-- cost = 17 for 28 sgtins loaded in the temp table.
SELECT sgtin
FROM sgtins_tmp_table
WHERE EXISTS
(SELECT sgtin FROM sgtins
WHERE sgtins.client_id = 4
AND sgtins.sgtin = sgtins_tmp_table.sgtin);
Select queries
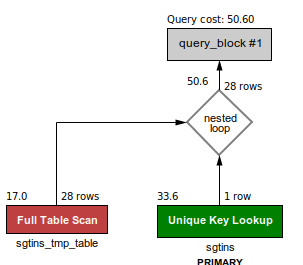
-- cost = 50.60 for 28 sgtins loaded in the temp table. 50K not usable.
SELECT sgtins.sgtin, sgtins.store, sgtins.timestamp
FROM sgtins_tmp_table, sgtins
WHERE sgtins.client_id = 4
AND sgtins_tmp_table.sgtin = sgtins.sgtin;
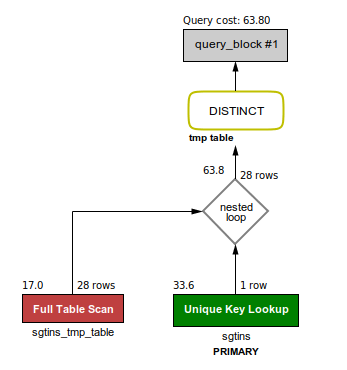
-- cost = 64 for 28 sgtins loaded in the temp table.
SELECT sgtins.sgtin, sgtins.store, sgtins.timestamp
FROM sgtins
WHERE sgtins.client_id = 4
AND sgtins.sgtin IN ( SELECT sgtins_tmp_table.sgtin
FROM sgtins_tmp_table);
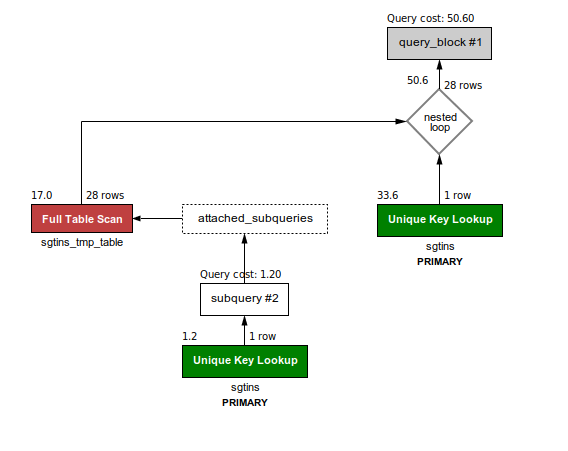
-- cost = 50.60 for 28 sgtins loaded in the temp table.
SELECT sgtins_tmp_table.epc, sgtins.store
FROM sgtins_tmp_table, sgtins
WHERE exists (SELECT organization_id, sgtin FROM sgtins WHERE client_id = 4 AND sgtins.sgtin = sgtins_tmp_table.sgtin)
AND sgtins.client_id = 4
AND sgtins_tmp_table.sgtin = sgtins.sgtin;
Summary
The exist query is usable but the selects are to slow. What can I do about it? And any advice is welcome :)
client_id,store,sgtin), is useless as I don't see any query that has these 3 params in the where clause in this specific order. however i you can provide the execution plans we can understand better what is happening – Galateaclient_id.. But keep in mind his limits in the past there was a hard limit off 1024 table partitions i believe not sure if MySQL 8 still has that limit i believe it is now 8192 – PiegariORall the time? But still you should rewrite the first corelated subquery (EXISTS) to a INNER JOIN most likely that is even faster.. – PiegariSELECT sgtins.* FROM (SELECT 1 AS sgtin UNION [ALL] ...) AS filter INNER JOIN sgtin ON ... WHERE sgtins.client_id = 4which makes a bit more sense memory wise and most likely also performance wise. – PiegariFROM (SELECT 'a' AS sgtin) AS filterwhen you useUNION. – Piegariclient_id,sgtin) this will improve a bit. After you add the index run again the queries using explain and compare the 2 of them. Adding this index it should perform an index scan – Galateasgtins and on the table with 200 million rows. The EXIST query is done in < 10s and the SELECT takes > 30 seconds and I got disconnected from MySQL. – Congressclient_id,sgtin) implies the pair is unique. But testing with 10 clientids and 28 sgtins -- That limits the table to about 280 rows, not 200M?? – FoliarIN(...)? – FoliarEXPLAINs"cost" at this level of detail; you really need to run real timing tests. – Foliar