I'm trying to create GAN model. This is my discriminator.py
import torch.nn as nn
class D(nn.Module):
feature_maps = 64
kernel_size = 4
stride = 2
padding = 1
bias = False
inplace = True
def __init__(self):
super(D, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(4, self.feature_maps, self.kernel_size, self.stride, self.padding, bias=self.bias),
nn.LeakyReLU(0.2, inplace=self.inplace),
nn.Conv2d(self.feature_maps, self.feature_maps * 2, self.kernel_size, self.stride, self.padding,
bias=self.bias),
nn.BatchNorm2d(self.feature_maps * 2), nn.LeakyReLU(0.2, inplace=self.inplace),
nn.Conv2d(self.feature_maps * 2, self.feature_maps * (2 * 2), self.kernel_size, self.stride, self.padding,
bias=self.bias),
nn.BatchNorm2d(self.feature_maps * (2 * 2)), nn.LeakyReLU(0.2, inplace=self.inplace),
nn.Conv2d(self.feature_maps * (2 * 2), self.feature_maps * (2 * 2 * 2), self.kernel_size, self.stride,
self.padding, bias=self.bias),
nn.BatchNorm2d(self.feature_maps * (2 * 2 * 2)), nn.LeakyReLU(0.2, inplace=self.inplace),
nn.Conv2d(self.feature_maps * (2 * 2 * 2), 1, self.kernel_size, 1, 0, bias=self.bias),
nn.Sigmoid()
)
def forward(self, input):
output = self.main(input)
return output.view(-1)
this is my generator.py
import torch.nn as nn
class G(nn.Module):
feature_maps = 512
kernel_size = 4
stride = 2
padding = 1
bias = False
def __init__(self, input_vector):
super(G, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(input_vector, self.feature_maps, self.kernel_size, 1, 0, bias=self.bias),
nn.BatchNorm2d(self.feature_maps), nn.ReLU(True),
nn.ConvTranspose2d(self.feature_maps, int(self.feature_maps // 2), self.kernel_size, self.stride, self.padding,
bias=self.bias),
nn.BatchNorm2d(int(self.feature_maps // 2)), nn.ReLU(True),
nn.ConvTranspose2d(int(self.feature_maps // 2), int((self.feature_maps // 2) // 2), self.kernel_size, self.stride,
self.padding,
bias=self.bias),
nn.BatchNorm2d(int((self.feature_maps // 2) // 2)), nn.ReLU(True),
nn.ConvTranspose2d((int((self.feature_maps // 2) // 2)), int(((self.feature_maps // 2) // 2) // 2), self.kernel_size,
self.stride, self.padding,
bias=self.bias),
nn.BatchNorm2d(int((self.feature_maps // 2) // 2) // 2), nn.ReLU(True),
nn.ConvTranspose2d(int(((self.feature_maps // 2) // 2) // 2), 4, self.kernel_size, self.stride, self.padding,
bias=self.bias),
nn.Tanh()
)
def forward(self, input):
output = self.main(input)
return output
This is my gans.py
# Importing the libraries
from __future__ import print_function
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.autograd import Variable
from generator import G
from discriminator import D
import os
from PIL import Image
batchSize = 64 # We set the size of the batch.
imageSize = 64 # We set the size of the generated images (64x64).
input_vector = 100
nb_epochs = 500
# Creating the transformations
transform = transforms.Compose([transforms.Resize((imageSize, imageSize)), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5, 0.5), (0.5, 0.5, 0.5,
0.5)), ]) # We create a list of transformations (scaling, tensor conversion, normalization) to apply to the input images.
def pil_loader_rgba(path: str) -> Image.Image:
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGBA')
# Loading the dataset
dataset = dset.ImageFolder(root='./data', transform=transform, loader=pil_loader_rgba)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batchSize, shuffle=True,
num_workers=2) # We use dataLoader to get the images of the training set batch by batch.
# Defining the weights_init function that takes as input a neural network m and that will initialize all its weights.
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def is_cuda_available():
return torch.cuda.is_available()
def is_gpu_available():
if is_cuda_available():
if int(torch.cuda.device_count()) > 0:
return True
return False
return False
# Create results directory
def create_dir(name):
if not os.path.exists(name):
os.makedirs(name)
# Creating the generator
netG = G(input_vector)
netG.apply(weights_init)
# Creating the discriminator
netD = D()
netD.apply(weights_init)
if is_gpu_available():
netG.cuda()
netD.cuda()
# Training the DCGANs
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
generator_model = 'generator_model'
discriminator_model = 'discriminator_model'
def save_model(epoch, model, optimizer, error, filepath, noise=None):
if os.path.exists(filepath):
os.remove(filepath)
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': error,
'noise': noise
}, filepath)
def load_checkpoint(filepath):
if os.path.exists(filepath):
return torch.load(filepath)
return None
def main():
print("Device name : " + torch.cuda.get_device_name(0))
for epoch in range(nb_epochs):
for i, data in enumerate(dataloader, 0):
checkpointG = load_checkpoint(generator_model)
checkpointD = load_checkpoint(discriminator_model)
if checkpointG:
netG.load_state_dict(checkpointG['model_state_dict'])
optimizerG.load_state_dict(checkpointG['optimizer_state_dict'])
if checkpointD:
netD.load_state_dict(checkpointD['model_state_dict'])
optimizerD.load_state_dict(checkpointD['optimizer_state_dict'])
# 1st Step: Updating the weights of the neural network of the discriminator
netD.zero_grad()
# Training the discriminator with a real image of the dataset
real, _ = data
if is_gpu_available():
input = Variable(real.cuda()).cuda()
target = Variable(torch.ones(input.size()[0]).cuda()).cuda()
else:
input = Variable(real)
target = Variable(torch.ones(input.size()[0]))
output = netD(input)
errD_real = criterion(output, target)
# Training the discriminator with a fake image generated by the generator
if is_gpu_available():
noise = Variable(torch.randn(input.size()[0], input_vector, 1, 1)).cuda()
target = Variable(torch.zeros(input.size()[0])).cuda()
else:
noise = Variable(torch.randn(input.size()[0], input_vector, 1, 1))
target = Variable(torch.zeros(input.size()[0]))
fake = netG(noise)
output = netD(fake.detach())
errD_fake = criterion(output, target)
# Backpropagating the total error
errD = errD_real + errD_fake
errD.backward()
optimizerD.step()
# 2nd Step: Updating the weights of the neural network of the generator
netG.zero_grad()
if is_gpu_available():
target = Variable(torch.ones(input.size()[0])).cuda()
else:
target = Variable(torch.ones(input.size()[0]))
output = netD(fake)
errG = criterion(output, target)
errG.backward()
optimizerG.step()
# 3rd Step: Printing the losses and saving the real images and the generated images of the minibatch every 100 steps
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f' % (
epoch, nb_epochs, i, len(dataloader), errD.data, errG.data))
save_model(epoch, netG, optimizerG, errG, generator_model, noise)
save_model(epoch, netD, optimizerD, errD, discriminator_model, noise)
if i % 100 == 0:
create_dir('results')
vutils.save_image(real, '%s/real_samples.png' % "./results", normalize=True)
fake = netG(noise)
vutils.save_image(fake.data, '%s/fake_samples_epoch_%03d.png' % ("./results", epoch), normalize=True)
if __name__ == "__main__":
main()
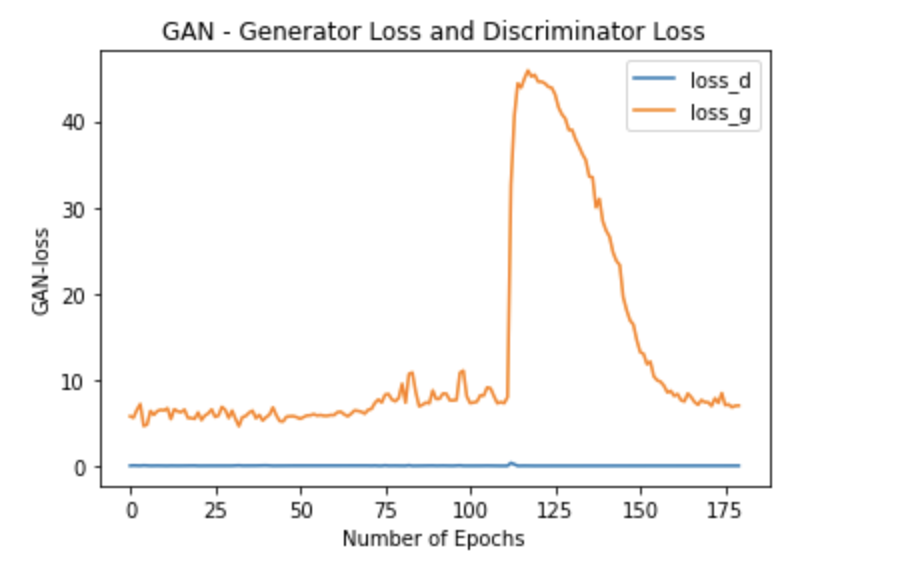
So AFTER few hours I decided to look at my results folder. I saw weird thing AFTER 39th epoch.
Generator started generating worst images. Until 39th epoch generator IMPROVED.
Pls look at below Screenshot.

Why generator suddenly became worst ? I'm trying to run 500 epochs. I thought more epochs more success
So I had a look at logs and I'm seeing below
[40/500][0/157] Loss_D: 0.0141 Loss_G: 5.7559
[40/500][1/157] Loss_D: 0.0438 Loss_G: 5.5805
[40/500][2/157] Loss_D: 0.0161 Loss_G: 6.4947
[40/500][3/157] Loss_D: 0.0138 Loss_G: 7.1711
[40/500][4/157] Loss_D: 0.0547 Loss_G: 4.6262
[40/500][5/157] Loss_D: 0.0295 Loss_G: 4.7831
[40/500][6/157] Loss_D: 0.0103 Loss_G: 6.3700
[40/500][7/157] Loss_D: 0.0276 Loss_G: 5.9162
[40/500][8/157] Loss_D: 0.0205 Loss_G: 6.3571
[40/500][9/157] Loss_D: 0.0139 Loss_G: 6.4961
[40/500][10/157] Loss_D: 0.0117 Loss_G: 6.4371
[40/500][11/157] Loss_D: 0.0057 Loss_G: 6.6858
[40/500][12/157] Loss_D: 0.0203 Loss_G: 5.4308
[40/500][13/157] Loss_D: 0.0078 Loss_G: 6.5749
[40/500][14/157] Loss_D: 0.0115 Loss_G: 6.3202
[40/500][15/157] Loss_D: 0.0187 Loss_G: 6.2258
[40/500][16/157] Loss_D: 0.0052 Loss_G: 6.5253
[40/500][17/157] Loss_D: 0.0158 Loss_G: 5.5672
[40/500][18/157] Loss_D: 0.0156 Loss_G: 5.5416
[40/500][19/157] Loss_D: 0.0306 Loss_G: 5.4550
[40/500][20/157] Loss_D: 0.0077 Loss_G: 6.1985
[40/500][21/157] Loss_D: 0.0158 Loss_G: 5.3092
[40/500][22/157] Loss_D: 0.0167 Loss_G: 5.8395
[40/500][23/157] Loss_D: 0.0119 Loss_G: 6.0849
[40/500][24/157] Loss_D: 0.0104 Loss_G: 6.5493
[40/500][25/157] Loss_D: 0.0182 Loss_G: 5.6758
[40/500][26/157] Loss_D: 0.0145 Loss_G: 5.8336
[40/500][27/157] Loss_D: 0.0050 Loss_G: 6.8472
[40/500][28/157] Loss_D: 0.0080 Loss_G: 6.4894
[40/500][29/157] Loss_D: 0.0186 Loss_G: 5.5563
[40/500][30/157] Loss_D: 0.0143 Loss_G: 6.4144
[40/500][31/157] Loss_D: 0.0377 Loss_G: 5.4557
[40/500][32/157] Loss_D: 0.0540 Loss_G: 4.6034
[40/500][33/157] Loss_D: 0.0200 Loss_G: 5.6417
[40/500][34/157] Loss_D: 0.0189 Loss_G: 5.7760
[40/500][35/157] Loss_D: 0.0197 Loss_G: 6.1732
[40/500][36/157] Loss_D: 0.0093 Loss_G: 6.4046
[40/500][37/157] Loss_D: 0.0281 Loss_G: 5.5217
[40/500][38/157] Loss_D: 0.0410 Loss_G: 5.9157
[40/500][39/157] Loss_D: 0.0667 Loss_G: 5.2522
[40/500][40/157] Loss_D: 0.0530 Loss_G: 5.6412
[40/500][41/157] Loss_D: 0.0315 Loss_G: 5.9325
[40/500][42/157] Loss_D: 0.0097 Loss_G: 6.7819
[40/500][43/157] Loss_D: 0.0157 Loss_G: 5.8630
[40/500][44/157] Loss_D: 0.0382 Loss_G: 5.1942
[40/500][45/157] Loss_D: 0.0331 Loss_G: 5.1490
[40/500][46/157] Loss_D: 0.0362 Loss_G: 5.7026
[40/500][47/157] Loss_D: 0.0237 Loss_G: 5.7493
[40/500][48/157] Loss_D: 0.0227 Loss_G: 5.7636
[40/500][49/157] Loss_D: 0.0230 Loss_G: 5.6500
[40/500][50/157] Loss_D: 0.0329 Loss_G: 5.4542
[40/500][51/157] Loss_D: 0.0306 Loss_G: 5.6473
[40/500][52/157] Loss_D: 0.0254 Loss_G: 5.8464
[40/500][53/157] Loss_D: 0.0402 Loss_G: 5.8609
[40/500][54/157] Loss_D: 0.0242 Loss_G: 5.9952
[40/500][55/157] Loss_D: 0.0400 Loss_G: 5.8378
[40/500][56/157] Loss_D: 0.0302 Loss_G: 5.8990
[40/500][57/157] Loss_D: 0.0239 Loss_G: 5.8134
[40/500][58/157] Loss_D: 0.0348 Loss_G: 5.8109
[40/500][59/157] Loss_D: 0.0361 Loss_G: 5.9011
[40/500][60/157] Loss_D: 0.0418 Loss_G: 5.8825
[40/500][61/157] Loss_D: 0.0501 Loss_G: 6.2302
[40/500][62/157] Loss_D: 0.0184 Loss_G: 6.2755
[40/500][63/157] Loss_D: 0.0273 Loss_G: 5.9655
[40/500][64/157] Loss_D: 0.0250 Loss_G: 5.7513
[40/500][65/157] Loss_D: 0.0298 Loss_G: 6.0434
[40/500][66/157] Loss_D: 0.0299 Loss_G: 6.4280
[40/500][67/157] Loss_D: 0.0205 Loss_G: 6.3743
[40/500][68/157] Loss_D: 0.0173 Loss_G: 6.2749
[40/500][69/157] Loss_D: 0.0199 Loss_G: 6.0541
[40/500][70/157] Loss_D: 0.0309 Loss_G: 6.5044
[40/500][71/157] Loss_D: 0.0177 Loss_G: 6.6093
[40/500][72/157] Loss_D: 0.0363 Loss_G: 7.2993
[40/500][73/157] Loss_D: 0.0093 Loss_G: 7.6995
[40/500][74/157] Loss_D: 0.0087 Loss_G: 7.3493
[40/500][75/157] Loss_D: 0.0540 Loss_G: 8.2688
[40/500][76/157] Loss_D: 0.0172 Loss_G: 8.3312
[40/500][77/157] Loss_D: 0.0086 Loss_G: 7.6863
[40/500][78/157] Loss_D: 0.0232 Loss_G: 7.4930
[40/500][79/157] Loss_D: 0.0175 Loss_G: 7.8834
[40/500][80/157] Loss_D: 0.0109 Loss_G: 9.5329
[40/500][81/157] Loss_D: 0.0093 Loss_G: 7.3253
[40/500][82/157] Loss_D: 0.0674 Loss_G: 10.6709
[40/500][83/157] Loss_D: 0.0010 Loss_G: 10.8321
[40/500][84/157] Loss_D: 0.0083 Loss_G: 8.5728
[40/500][85/157] Loss_D: 0.0124 Loss_G: 6.9085
[40/500][86/157] Loss_D: 0.0181 Loss_G: 7.0867
[40/500][87/157] Loss_D: 0.0130 Loss_G: 7.3527
[40/500][88/157] Loss_D: 0.0189 Loss_G: 7.2494
[40/500][89/157] Loss_D: 0.0302 Loss_G: 8.7555
[40/500][90/157] Loss_D: 0.0147 Loss_G: 7.7668
[40/500][91/157] Loss_D: 0.0325 Loss_G: 7.7779
[40/500][92/157] Loss_D: 0.0257 Loss_G: 8.3955
[40/500][93/157] Loss_D: 0.0113 Loss_G: 8.3687
[40/500][94/157] Loss_D: 0.0124 Loss_G: 7.6081
[40/500][95/157] Loss_D: 0.0088 Loss_G: 7.6012
[40/500][96/157] Loss_D: 0.0241 Loss_G: 7.6573
[40/500][97/157] Loss_D: 0.0522 Loss_G: 10.8114
[40/500][98/157] Loss_D: 0.0071 Loss_G: 11.0529
[40/500][99/157] Loss_D: 0.0043 Loss_G: 8.0707
[40/500][100/157] Loss_D: 0.0141 Loss_G: 7.2864
[40/500][101/157] Loss_D: 0.0234 Loss_G: 7.3585
[40/500][102/157] Loss_D: 0.0148 Loss_G: 7.4577
[40/500][103/157] Loss_D: 0.0190 Loss_G: 8.1904
[40/500][104/157] Loss_D: 0.0201 Loss_G: 8.1518
[40/500][105/157] Loss_D: 0.0220 Loss_G: 9.1069
[40/500][106/157] Loss_D: 0.0108 Loss_G: 9.0069
[40/500][107/157] Loss_D: 0.0044 Loss_G: 8.0970
[40/500][108/157] Loss_D: 0.0076 Loss_G: 7.2699
[40/500][109/157] Loss_D: 0.0052 Loss_G: 7.4036
[40/500][110/157] Loss_D: 0.0167 Loss_G: 7.2742
[40/500][111/157] Loss_D: 0.0032 Loss_G: 7.9825
[40/500][112/157] Loss_D: 0.3462 Loss_G: 32.6314
[40/500][113/157] Loss_D: 0.1704 Loss_G: 40.6010
[40/500][114/157] Loss_D: 0.0065 Loss_G: 44.4607
[40/500][115/157] Loss_D: 0.0142 Loss_G: 43.9761
[40/500][116/157] Loss_D: 0.0160 Loss_G: 45.0376
[40/500][117/157] Loss_D: 0.0042 Loss_G: 45.9534
[40/500][118/157] Loss_D: 0.0061 Loss_G: 45.2998
[40/500][119/157] Loss_D: 0.0023 Loss_G: 45.4654
[40/500][120/157] Loss_D: 0.0033 Loss_G: 44.6643
[40/500][121/157] Loss_D: 0.0042 Loss_G: 44.6020
[40/500][122/157] Loss_D: 0.0002 Loss_G: 44.4807
[40/500][123/157] Loss_D: 0.0004 Loss_G: 44.0402
[40/500][124/157] Loss_D: 0.0055 Loss_G: 43.9188
[40/500][125/157] Loss_D: 0.0021 Loss_G: 43.1988
[40/500][126/157] Loss_D: 0.0008 Loss_G: 41.6770
[40/500][127/157] Loss_D: 0.0001 Loss_G: 40.8719
[40/500][128/157] Loss_D: 0.0009 Loss_G: 40.3803
[40/500][129/157] Loss_D: 0.0023 Loss_G: 39.0143
[40/500][130/157] Loss_D: 0.0254 Loss_G: 39.0317
[40/500][131/157] Loss_D: 0.0008 Loss_G: 37.9451
[40/500][132/157] Loss_D: 0.0253 Loss_G: 37.1046
[40/500][133/157] Loss_D: 0.0046 Loss_G: 36.2807
[40/500][134/157] Loss_D: 0.0025 Loss_G: 35.5878
[40/500][135/157] Loss_D: 0.0011 Loss_G: 33.6500
[40/500][136/157] Loss_D: 0.0061 Loss_G: 33.5011
[40/500][137/157] Loss_D: 0.0015 Loss_G: 30.0363
[40/500][138/157] Loss_D: 0.0019 Loss_G: 31.0197
[40/500][139/157] Loss_D: 0.0027 Loss_G: 28.4693
[40/500][140/157] Loss_D: 0.0189 Loss_G: 27.3072
[40/500][141/157] Loss_D: 0.0051 Loss_G: 26.6637
[40/500][142/157] Loss_D: 0.0077 Loss_G: 24.8390
[40/500][143/157] Loss_D: 0.0123 Loss_G: 23.8334
[40/500][144/157] Loss_D: 0.0014 Loss_G: 23.3755
[40/500][145/157] Loss_D: 0.0036 Loss_G: 19.6341
[40/500][146/157] Loss_D: 0.0025 Loss_G: 18.1076
[40/500][147/157] Loss_D: 0.0029 Loss_G: 16.9415
[40/500][148/157] Loss_D: 0.0028 Loss_G: 16.4647
[40/500][149/157] Loss_D: 0.0048 Loss_G: 14.6184
[40/500][150/157] Loss_D: 0.0074 Loss_G: 13.2544
[40/500][151/157] Loss_D: 0.0053 Loss_G: 13.0052
[40/500][152/157] Loss_D: 0.0070 Loss_G: 11.8815
[40/500][153/157] Loss_D: 0.0078 Loss_G: 12.1657
[40/500][154/157] Loss_D: 0.0094 Loss_G: 10.4259
[40/500][155/157] Loss_D: 0.0073 Loss_G: 9.9345
[40/500][156/157] Loss_D: 0.0082 Loss_G: 9.7609
[41/500][0/157] Loss_D: 0.0079 Loss_G: 9.2920
[41/500][1/157] Loss_D: 0.0134 Loss_G: 8.5241
[41/500][2/157] Loss_D: 0.0156 Loss_G: 8.6983
[41/500][3/157] Loss_D: 0.0250 Loss_G: 8.1148
[41/500][4/157] Loss_D: 0.0160 Loss_G: 8.3324
[41/500][5/157] Loss_D: 0.0187 Loss_G: 7.6281
[41/500][6/157] Loss_D: 0.0191 Loss_G: 7.4707
[41/500][7/157] Loss_D: 0.0092 Loss_G: 8.3976
[41/500][8/157] Loss_D: 0.0118 Loss_G: 7.9800
[41/500][9/157] Loss_D: 0.0126 Loss_G: 7.3999
[41/500][10/157] Loss_D: 0.0165 Loss_G: 7.0854
[41/500][11/157] Loss_D: 0.0095 Loss_G: 7.6392
[41/500][12/157] Loss_D: 0.0079 Loss_G: 7.3862
[41/500][13/157] Loss_D: 0.0181 Loss_G: 7.3812
[41/500][14/157] Loss_D: 0.0168 Loss_G: 6.9518
[41/500][15/157] Loss_D: 0.0094 Loss_G: 7.8525
[41/500][16/157] Loss_D: 0.0165 Loss_G: 7.3024
[41/500][17/157] Loss_D: 0.0029 Loss_G: 8.4487
[41/500][18/157] Loss_D: 0.0169 Loss_G: 7.0449
[41/500][19/157] Loss_D: 0.0167 Loss_G: 7.1307
[41/500][20/157] Loss_D: 0.0255 Loss_G: 6.7970
[41/500][21/157] Loss_D: 0.0154 Loss_G: 6.9745
[41/500][22/157] Loss_D: 0.0110 Loss_G: 6.9925
As you can see there is a HUGE change happened to Generator loss(Loss_G).
Any idea why that happened ?
Any idea how to overcome such a problem ?
clipvalueto your optimizers or a custom setup. – Downwash