I need a regular expression that validates a number, but doesn't require a digit after the decimal. ie.
123
123.
123.4
would all be valid
123..
would be invalid
Any would be greatly appreciated!
I need a regular expression that validates a number, but doesn't require a digit after the decimal. ie.
123
123.
123.4
would all be valid
123..
would be invalid
Any would be greatly appreciated!
Use the following:
/^\d*\.?\d*$/
^ - Beginning of the line;\d* - 0 or more digits;\.? - An optional dot (escaped, because in regex, . is a special character);\d* - 0 or more digits (the decimal part);$ - End of the line.This allows for .5 decimal rather than requiring the leading zero, such as 0.5
\d+\.?\d*, would have matched '3.45' in 'cow3.45tornado'! –
Shipway /^\d*\.?\d+$/ which would force a digit after a decimal point. –
Voronezh /\d+\.?\d*/
One or more digits (\d+), optional period (\.?), zero or more digits (\d*).
Depending on your usage or regex engine you may need to add start/end line anchors:
/^\d+\.?\d*$/

. and the empty string. –
Raynell -1 and not - . –
Silvanasilvano - at all. –
Raynell | at the end. –
Raynell . after a number, so how do you type 1. –
Houseclean You need a regular expression like the following to do it properly:
/^[+-]?((\d+(\.\d*)?)|(\.\d+))$/
The same expression with whitespace, using the extended modifier (as supported by Perl):
/^ [+-]? ( (\d+ (\.\d*)?) | (\.\d+) ) $/x
or with comments:
/^ # Beginning of string
[+-]? # Optional plus or minus character
( # Followed by either:
( # Start of first option
\d+ # One or more digits
(\.\d*)? # Optionally followed by: one decimal point and zero or more digits
) # End of first option
| # or
(\.\d+) # One decimal point followed by one or more digits
) # End of grouping of the OR options
$ # End of string (i.e. no extra characters remaining)
/x # Extended modifier (allows whitespace & comments in regular expression)
For example, it will match:
And will reject these non-numbers:
The simpler solutions can incorrectly reject valid numbers or match these non-numbers.
^A?(B|C)$. Previously, it was written like ^A?B|C$ which actually means (^A?B)|(C$) which was incorrect. Note: ^(A?B|C)$ is also incorrect, because it actually means ^((A?B)|(C))$ which would not match "+.5". –
Wolof this matches all requirements:
^\d+(\.\d+)?$
Try this regex:
\d+\.?\d*
\d+ digits before optional decimal
.? optional decimal(optional due to the ? quantifier)
\d* optional digits after decimal
123. –
Lucianolucias I ended up using the following:
^\d*\.?\d+$
This makes the following invalid:
.
3.
This is what I did. It's more strict than any of the above (and more correct than some):
^0$|^[1-9]\d*$|^\.\d+$|^0\.\d*$|^[1-9]\d*\.\d*$
Strings that passes:
0
0.
1
123
123.
123.4
.0
.0123
.123
0.123
1.234
12.34
Strings that fails:
.
00000
01
.0.
..
00.123
02.134
you can use this:
^\d+(\.\d)?\d*$
matches:
11
11.1
0.2
does not match:
.2
2.
2.6.9
^[+-]?(([1-9][0-9]*)?[0-9](\.[0-9]*)?|\.[0-9]+)$
should reflect what people usually think of as a well formed decimal number.
The digits before the decimal point can be either a single digit, in which case it can be from 0 to 9, or more than one digits, in which case it cannot start with a 0.
If there are any digits present before the decimal sign, then the decimal and the digits following it are optional. Otherwise, a decimal has to be present followed by at least one digit. Note that multiple trailing 0's are allowed after the decimal point.
grep -E '^[+-]?(([1-9][0-9]*)?[0-9](\.[0-9]*)?|\.[0-9]+)$'
correctly matches the following:
9
0
10
10.
0.
0.0
0.100
0.10
0.01
10.0
10.10
.0
.1
.00
.100
.001
as well as their signed equivalents, whereas it rejects the following:
.
00
01
00.0
01.3
and their signed equivalents, as well as the empty string.
try this. ^[0-9]\d{0,9}(\.\d{1,3})?%?$ it is tested and worked for me.
What you asked is already answered so this is just an additional info for those who want only 2 decimal digits if optional decimal point is entered:
^\d+(\.\d{2})?$
^ : start of the string
\d : a digit (equal to [0-9])
+ : one and unlimited times
Capturing Group (.\d{2})?
? : zero and one times
. : character .
\d : a digit (equal to [0-9])
{2} : exactly 2 times
$ : end of the string
1 : match
123 : match
123.00 : match
123. : no match
123.. : no match
123.0 : no match
123.000 : no match
123.00.00 : no match
^\d+((.)|(.\d{0,1})?)$
use \d+ instead of \d{0,1} if you want to allow more then one number use \d{0,2} instead of \d{0,1} if you want to allow up to two numbers after coma. See the example below for reference:
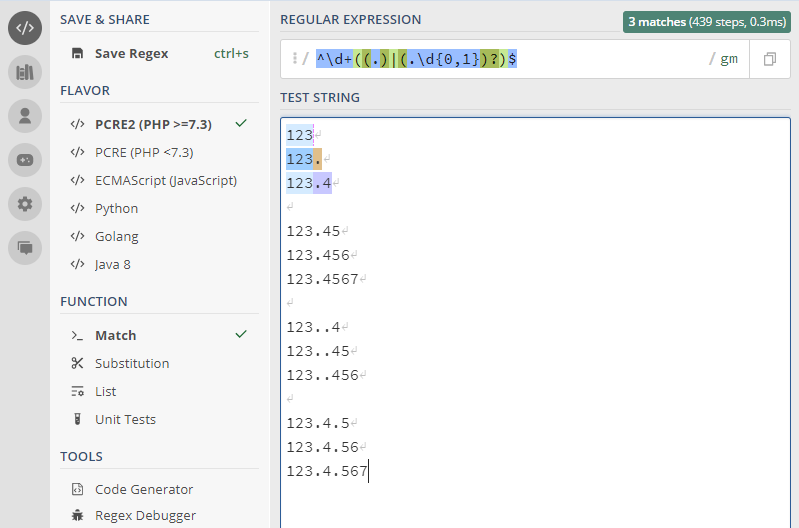
or
^\d+((.)|(.\d{0,2})?)$
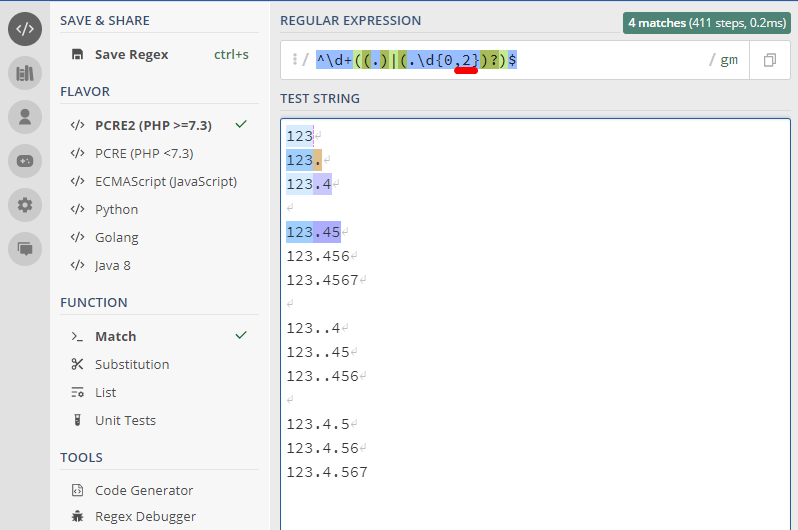
or
^\d+((.)|(.\d+)?)$
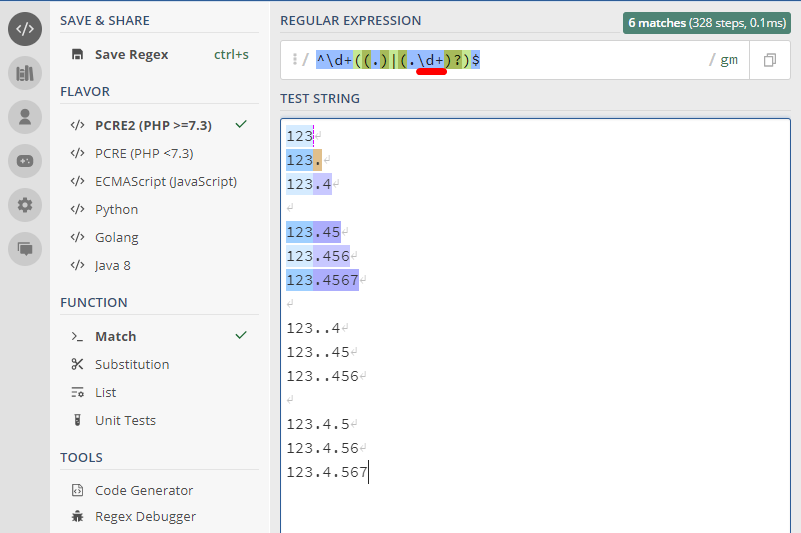
(These are generated by regex101)
^ asserts position at start of a line\d matches a digit (equivalent to [0-9])+ matches the previous token between one and unlimited times, as many times as possible, giving back as needed (greedy)((.)|(.\d{0,1})?)(.)(.). matches any character (except for line terminators)(.\d{0,1})?(.\d{0,1})?? matches the previous token between zero and one times, as many times as possible, giving back as needed (greedy). matches any character (except for line terminators)\d matches a digit (equivalent to [0-9]){0,1} matches the previous token between zero and one times, as many times as possible, giving back as needed (greedy)$ asserts position at the end of a linePlay with regex here: https://regex101.com/
123a1. –
Cahn For those who wanna match the same thing as JavaScript does:
[-+]?(\d+\.?\d*|\.\d+)
Matches:
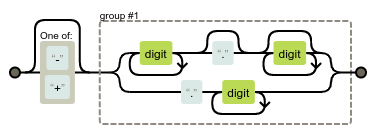
Drawing: https://regexper.com/#%5B-%2B%5D%3F%28%5Cd%2B%5C.%3F%5Cd*%7C%5C.%5Cd%2B%29
(?<![^d])\d+(?:\.\d+)?(?![^d])
clean and simple.
This uses Suffix and Prefix, RegEx features.
It directly returns true - false for IsMatch condition
^\d+(()|(\.\d+)?)$
Came up with this. Allows both integer and decimal, but forces a complete decimal (leading and trailing numbers) if you decide to enter a decimal.
In Perl, use Regexp::Common which will allow you to assemble a finely-tuned regular expression for your particular number format. If you are not using Perl, the generated regular expression can still typically be used by other languages.
Printing the result of generating the example regular expressions in Regexp::Common::Number:
$ perl -MRegexp::Common=number -E 'say $RE{num}{int}'
(?:(?:[-+]?)(?:[0123456789]+))
$ perl -MRegexp::Common=number -E 'say $RE{num}{real}'
(?:(?i)(?:[-+]?)(?:(?=[.]?[0123456789])(?:[0123456789]*)(?:(?:[.])(?:[0123456789]{0,}))?)(?:(?:[E])(?:(?:[-+]?)(?:[0123456789]+))|))
$ perl -MRegexp::Common=number -E 'say $RE{num}{real}{-base=>16}'
(?:(?i)(?:[-+]?)(?:(?=[.]?[0123456789ABCDEF])(?:[0123456789ABCDEF]*)(?:(?:[.])(?:[0123456789ABCDEF]{0,}))?)(?:(?:[G])(?:(?:[-+]?)(?:[0123456789ABCDEF]+))|))
All of the regexes here are wrong because they don't consider a lot of edge cases:
Assuming only the US format the following numbers are valid:
0.1
.1
1
12
123
1234
1,234
12345
12,345
123456
123,456
123456789
123,456,789
1.0
12.0
123.0
1234.0
1,234.0
12345.0
12,345.0
123456.0
123,456.0
123456789.0
123,456,789.0
+0.1
+.1
+1.0
+12.0
+123.0
+1234.0
+1,234.0
+12345.0
+12,345.0
+123456.0
+123,456.0
+123456789.0
+123,456,789.0
-0.1
-.1
-1.0
-12.0
-123.0
-1234.0
-1,234.0
-12345.0
-12,345.0
-123456.0
-123,456.0
-123456789.0
-123,456,789.0
Assuming only the US format the following numbers are invalid:
1,000,
1,4
1,00
1,000,1
1,000,10
1.1.
1..1
..1
.1.
-1.1.
-1..1
-..1
-.1.
The following regex matches only the valid US numbers:
^[+-]?((\d*)|(\d{1,3}(,\d{3})+))(\.\d+)?$
if you want non-US numbers:
^[+-]?((\d*)|(\d{1,3}(\.\d{3})+))(,\d+)?$
Edit 1:
BTW: In some cases, numbers are represented in exponential form
4800 -> 4.80000000000000E+03
My regex doesn't consider those numbers yet.
© 2022 - 2024 — McMap. All rights reserved.