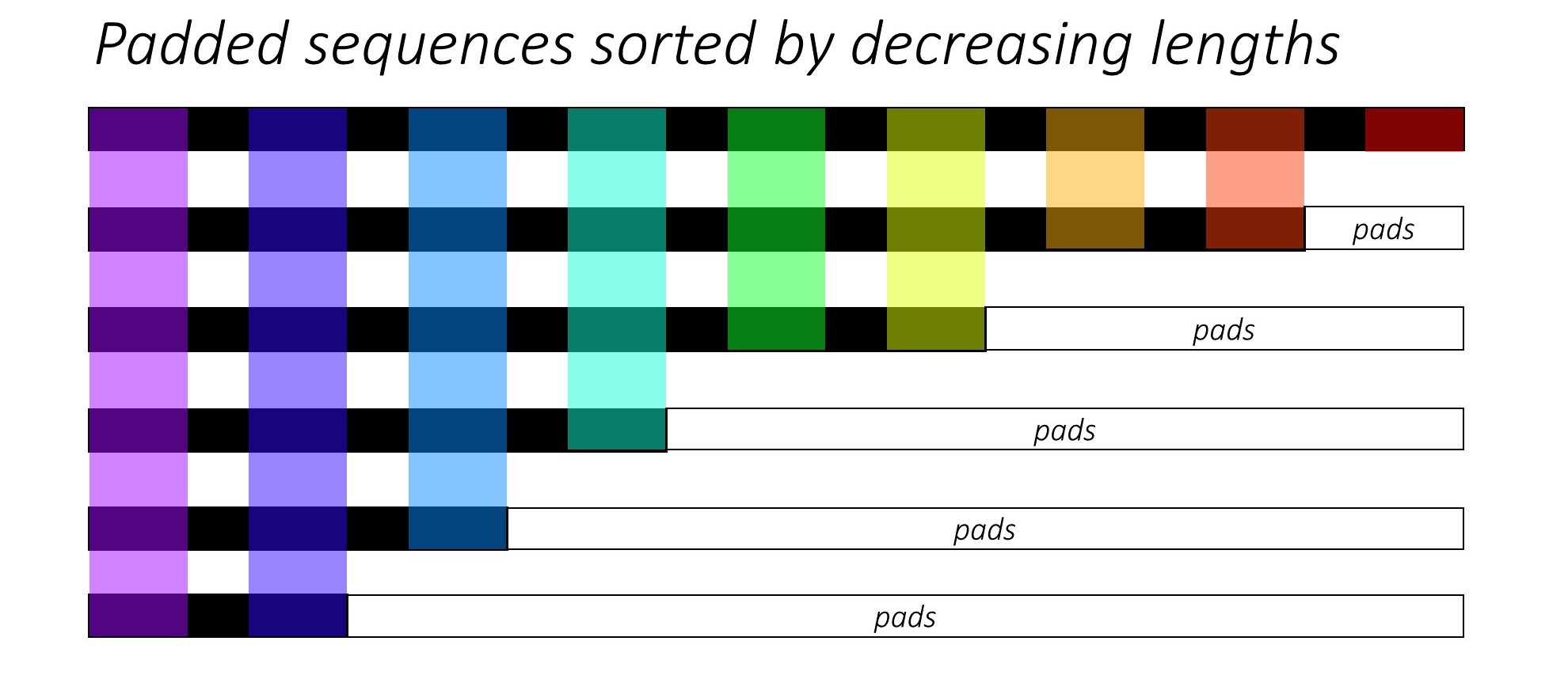
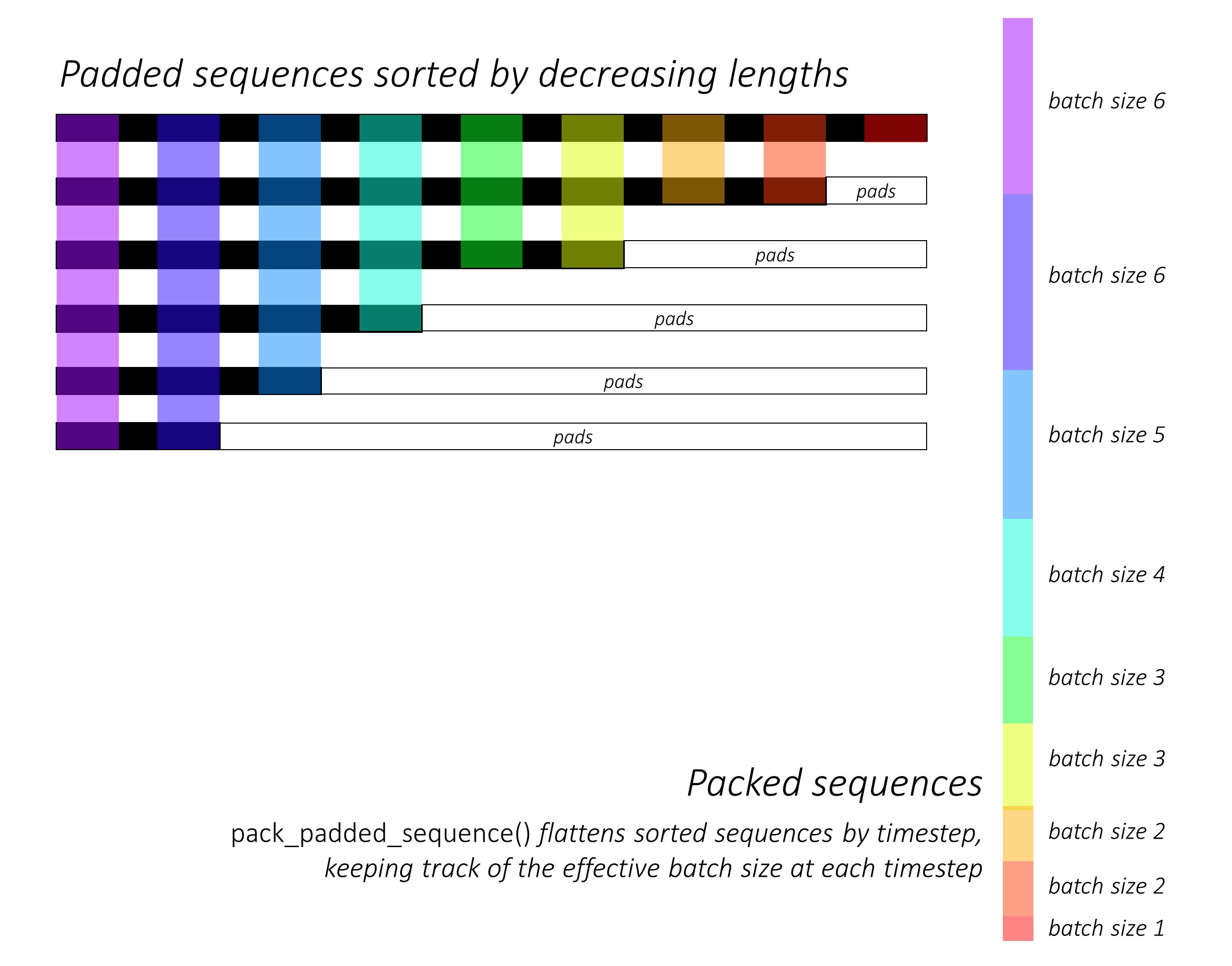
The above answers addressed the question why very well. I just want to add an example for better understanding the use of pack_padded_sequence.
Let's take an example
Note: pack_padded_sequence requires sorted sequences in the batch (in the descending order of sequence lengths). In the below example, the sequence batch were already sorted for less cluttering. Visit this gist link for the full implementation.
First, we create a batch of 2 sequences of different sequence lengths as below. We have 7 elements in the batch totally.
- Each sequence has embedding size of 2.
- The first sequence has the length: 5
- The second sequence has the length: 2
import torch
seq_batch = [torch.tensor([[1, 1],
[2, 2],
[3, 3],
[4, 4],
[5, 5]]),
torch.tensor([[10, 10],
[20, 20]])]
seq_lens = [5, 2]
We pad seq_batch to get the batch of sequences with equal length of 5 (The max length in the batch). Now, the new batch has 10 elements totally.
# pad the seq_batch
padded_seq_batch = torch.nn.utils.rnn.pad_sequence(seq_batch, batch_first=True)
"""
>>>padded_seq_batch
tensor([[[ 1, 1],
[ 2, 2],
[ 3, 3],
[ 4, 4],
[ 5, 5]],
[[10, 10],
[20, 20],
[ 0, 0],
[ 0, 0],
[ 0, 0]]])
"""
Then, we pack the padded_seq_batch. It returns a tuple of two tensors:
- The first is the data including all the elements in the sequence batch.
- The second is the
batch_sizes which will tell how the elements related to each other by the steps.
# pack the padded_seq_batch
packed_seq_batch = torch.nn.utils.rnn.pack_padded_sequence(padded_seq_batch, lengths=seq_lens, batch_first=True)
"""
>>> packed_seq_batch
PackedSequence(
data=tensor([[ 1, 1],
[10, 10],
[ 2, 2],
[20, 20],
[ 3, 3],
[ 4, 4],
[ 5, 5]]),
batch_sizes=tensor([2, 2, 1, 1, 1]))
"""
Now, we pass the tuple packed_seq_batch to the recurrent modules in Pytorch, such as RNN, LSTM. This only requires 5 + 2=7 computations in the recurrrent module.
lstm = nn.LSTM(input_size=2, hidden_size=3, batch_first=True)
output, (hn, cn) = lstm(packed_seq_batch.float()) # pass float tensor instead long tensor.
"""
>>> output # PackedSequence
PackedSequence(data=tensor(
[[-3.6256e-02, 1.5403e-01, 1.6556e-02],
[-6.3486e-05, 4.0227e-03, 1.2513e-01],
[-5.3134e-02, 1.6058e-01, 2.0192e-01],
[-4.3123e-05, 2.3017e-05, 1.4112e-01],
[-5.9372e-02, 1.0934e-01, 4.1991e-01],
[-6.0768e-02, 7.0689e-02, 5.9374e-01],
[-6.0125e-02, 4.6476e-02, 7.1243e-01]], grad_fn=<CatBackward>), batch_sizes=tensor([2, 2, 1, 1, 1]))
>>>hn
tensor([[[-6.0125e-02, 4.6476e-02, 7.1243e-01],
[-4.3123e-05, 2.3017e-05, 1.4112e-01]]], grad_fn=<StackBackward>),
>>>cn
tensor([[[-1.8826e-01, 5.8109e-02, 1.2209e+00],
[-2.2475e-04, 2.3041e-05, 1.4254e-01]]], grad_fn=<StackBackward>)))
"""
We need to convert output back to the padded batch of output:
padded_output, output_lens = torch.nn.utils.rnn.pad_packed_sequence(output, batch_first=True, total_length=5)
"""
>>> padded_output
tensor([[[-3.6256e-02, 1.5403e-01, 1.6556e-02],
[-5.3134e-02, 1.6058e-01, 2.0192e-01],
[-5.9372e-02, 1.0934e-01, 4.1991e-01],
[-6.0768e-02, 7.0689e-02, 5.9374e-01],
[-6.0125e-02, 4.6476e-02, 7.1243e-01]],
[[-6.3486e-05, 4.0227e-03, 1.2513e-01],
[-4.3123e-05, 2.3017e-05, 1.4112e-01],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00]]],
grad_fn=<TransposeBackward0>)
>>> output_lens
tensor([5, 2])
"""
Compare this effort with the standard way
In the standard way, we only need to pass the padded_seq_batch to lstm module. However, it requires 10 computations. It involves several computes more on padding elements which would be computationally inefficient.
Note that it does not lead to inaccurate representations, but need much more logic to extract correct representations.
- For LSTM (or any recurrent modules) with only forward direction, if we would like to extract the hidden vector of the last step as a representation for a sequence, we would have to pick up hidden vectors from T(th) step, where T is the length of the input. Picking up the last representation will be incorrect. Note that T will be different for different inputs in batch.
- For Bi-directional LSTM (or any recurrent modules), it is even more cumbersome, as one would have to maintain two RNN modules, one that works with padding at the beginning of the input and one with padding at end of the input, and finally extracting and concatenating the hidden vectors as explained above.
Let's see the difference:
# The standard approach: using padding batch for recurrent modules
output, (hn, cn) = lstm(padded_seq_batch.float())
"""
>>> output
tensor([[[-3.6256e-02, 1.5403e-01, 1.6556e-02],
[-5.3134e-02, 1.6058e-01, 2.0192e-01],
[-5.9372e-02, 1.0934e-01, 4.1991e-01],
[-6.0768e-02, 7.0689e-02, 5.9374e-01],
[-6.0125e-02, 4.6476e-02, 7.1243e-01]],
[[-6.3486e-05, 4.0227e-03, 1.2513e-01],
[-4.3123e-05, 2.3017e-05, 1.4112e-01],
[-4.1217e-02, 1.0726e-01, -1.2697e-01],
[-7.7770e-02, 1.5477e-01, -2.2911e-01],
[-9.9957e-02, 1.7440e-01, -2.7972e-01]]],
grad_fn= < TransposeBackward0 >)
>>> hn
tensor([[[-0.0601, 0.0465, 0.7124],
[-0.1000, 0.1744, -0.2797]]], grad_fn= < StackBackward >),
>>> cn
tensor([[[-0.1883, 0.0581, 1.2209],
[-0.2531, 0.3600, -0.4141]]], grad_fn= < StackBackward >))
"""
The above results show that hn, cn are different in two ways while output from two ways lead to different values for padding elements.