Our CloneDR tool finds duplicated code by comparing abstract syntax trees from parsers. (It comes in language-specific versions for many languages, including Java and JavaScript).
This means it can find cloned code in spite of format changes and modifications of the body of the clone, both of which are often done while cloning. Found clones match language concepts such as expression, declaration, statements, functions, and even classes. Clones that are similar are reported along with the differences/variation points as proposed parameters.
It can find clone sets with multiple instances (we've some applications with hundreds of clones of a single bit of code), and it can find clones across many source files.
It produces HTML reports that are directly readable by people, and XML reports that can be processed by other downstream tools. (You can see some sample HTML reports via the link).
Similarity is hard to define, and in fact you can define it in many ways. CloneDR defines it as the ratio of identical elements (technically, AST nodes) across a clone set divided by the total number of elements across the clone set. This ratio is a value between 0 and 1. It is compared against a threshold; we've found that 95% is surprisingly robust as threshold in terms of the quality of reported clones.
It is useful to establish a minimum size for interesting clones. a*b is a clone of x*y (with 2 parameters) but isn't useful to report because it is too small. CloneDR also uses a size threshold which we call "line count", but in fact is the size of the clone in elements divided by the average number of elements per line across the entire code base. This produces clones which usually have more lines than the threshold, but it will find clones for enormous expressions that are within a line. We've found that 5-6 "lines" is also fairly robust in terms of reported clone quality.
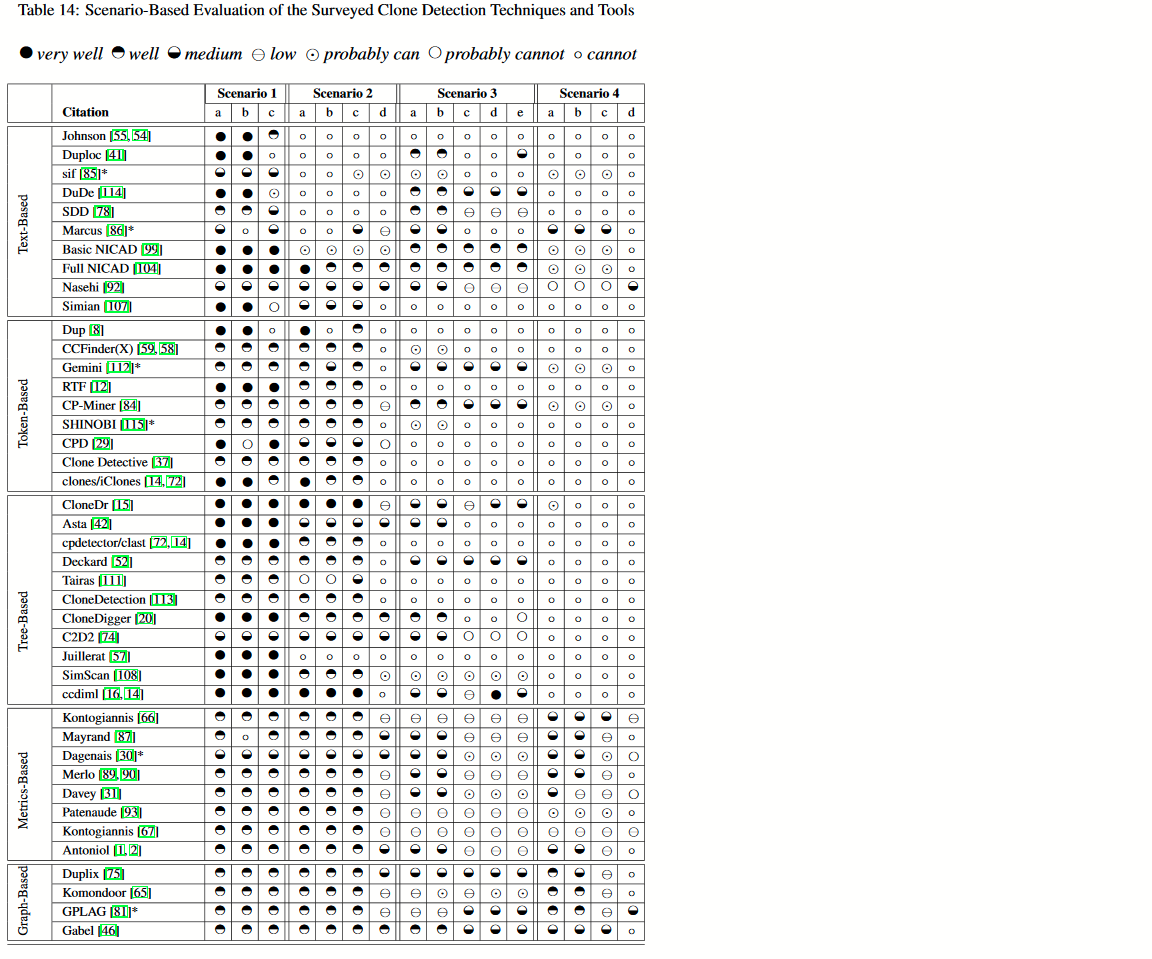
This table shows how effective the AST matching approach of CloneDR is compared to many other clone detection tools (ranking it “very well”). The only one that comes close is CCDIML …. which is an academic re-implementation of the CloneDR approach. There are other approaches (namely PDG-based approaches) which can detect clones that are scattered about more effectively, but in practice, in my personal experience, people that clone code don’t usually cut the cloned part into a bunch of separate parts to scatter them about; they are just too lazy. YMMV.
![enter image description here]()
[Table from: Roy, Cordy, Koschke: Comparison and Evaluation of Code Clone Detection Techniques and Tools: A Qualitative Approach , Science of Computer Programming, Volume 74 Issue 7, May, 2009. This paper sketches many different clone detection approaches and evaluates their effectiveness.]
[PMD isn't listed, but apparantly using Rabin-Karp string matching, "text based" according to the above table, rather than AST matching.]
Re OP's requirements:
CloneDR (and in fact no tool I know) will NOT find a set of similar methods across multiple methods, if those methods occur in different orders in different classes. In this case, CloneDR is more likely to report the individual methods as clones; the net result is the same. It will find such a set if the members occur sequentially in the same order in the different classes, as happens when one class body has been wholesale copied from another.
Similar code blocks across multiple methods is quite commonly detected. The generated report shows how the the similar code blocks are related, including an abstracted version of the code which is essentially the parameterized code block you need for a method body.