I am running word count program from my windows machine on hadoop cluster which is setup on remote linux machine. Program is running successfully and I am getting output but I am getting following exception and my waitForCompletion(true) is not returning true.
java.io.IOException: java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort
at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:345)
at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:430)
at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:870)
at org.apache.hadoop.mapreduce.Job$1.run(Job.java:331)
at org.apache.hadoop.mapreduce.Job$1.run(Job.java:328)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1682)
at org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:328)
at org.apache.hadoop.mapreduce.Job.isComplete(Job.java:612)
at org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1629)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1591)
at practiceHadoop.WordCount$1.run(WordCount.java:60)
at practiceHadoop.WordCount$1.run(WordCount.java:1)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1682)
at practiceHadoop.WordCount.main(WordCount.java:24)
Caused by: java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:831)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:751)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1495)
at org.apache.hadoop.ipc.Client.call(Client.java:1437)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy16.getJobReport(Unknown Source)
at org.apache.hadoop.mapreduce.v2.api.impl.pb.client.MRClientProtocolPBClientImpl.getJobReport(MRClientProtocolPBClientImpl.java:133)
at sun.reflect.GeneratedMethodAccessor2.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:326)
... 17 more
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:685)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:788)
at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:409)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1552)
at org.apache.hadoop.ipc.Client.call(Client.java:1383)
... 26 more
My MapReduce Program which I run on eclipse (windows)
UserGroupInformation ugi = UserGroupInformation.createRemoteUser("admin");
ugi.doAs(new PrivilegedExceptionAction<Void>() {
public Void run() throws Exception {
try {
Configuration configuration = new Configuration();
configuration.set("yarn.resourcemanager.address", "192.168.33.75:50001"); // see step 3
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("yarn.app.mapreduce.am.env",
"HADOOP_MAPRED_HOME=/home/admin/hadoop-3.1.0");
configuration.set("mapreduce.map.env", "HADOOP_MAPRED_HOME=/home/admin/hadoop-3.1.0");
configuration.set("mapreduce.reduce.env", "HADOOP_MAPRED_HOME=/home/admin/hadoop-3.1.0");
configuration.set("fs.defaultFS", "hdfs://192.168.33.75:54310"); // see step 2
configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("mapred.remote.os", "Linux");
configuration.set("yarn.application.classpath",
"{{HADOOP_CONF_DIR}},{{HADOOP_COMMON_HOME}}/share/hadoop/common/*,{{HADOOP_COMMON_HOME}}/share/hadoop/common/lib/*,"
+ " {{HADOOP_HDFS_HOME}}/share/hadoop/hdfs/*,{{HADOOP_HDFS_HOME}}/share/hadoop/hdfs/lib/*,"
+ "{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/*,{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/lib/*,"
+ "{{HADOOP_YARN_HOME}}/share/hadoop/yarn/*,{{HADOOP_YARN_HOME}}/share/hadoop/yarn/lib/*");
configuration.set("mlv_construct", "min");
configuration.set("column_name", "TotalCost");
Job job = Job.getInstance(configuration);
job.setJar("C:\\Users\\gauravp\\Desktop\\WordCountProgam.jar");
job.setJarByClass(WordCount.class); // use this when uploaded the Jar to the server and
// running the job directly and locally on the server
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MapForWordCount.class);
job.setReducerClass(ReduceForWordCount.class);
Path input = new Path("/user/admin/wordCountInput.txt");
Path output = new Path("/user/admin/output");
FileSystem fs = FileSystem.get(configuration);
fs.delete(output);
FileInputFormat.addInputPath(job, input);
FileOutputFormat.setOutputPath(job, output);
if (job.waitForCompletion(true)) {
System.out.println("Job done...");
}
One more observation : My connection from windows machine to remote linux machine ports (54310 and 50001) vanish after some time.
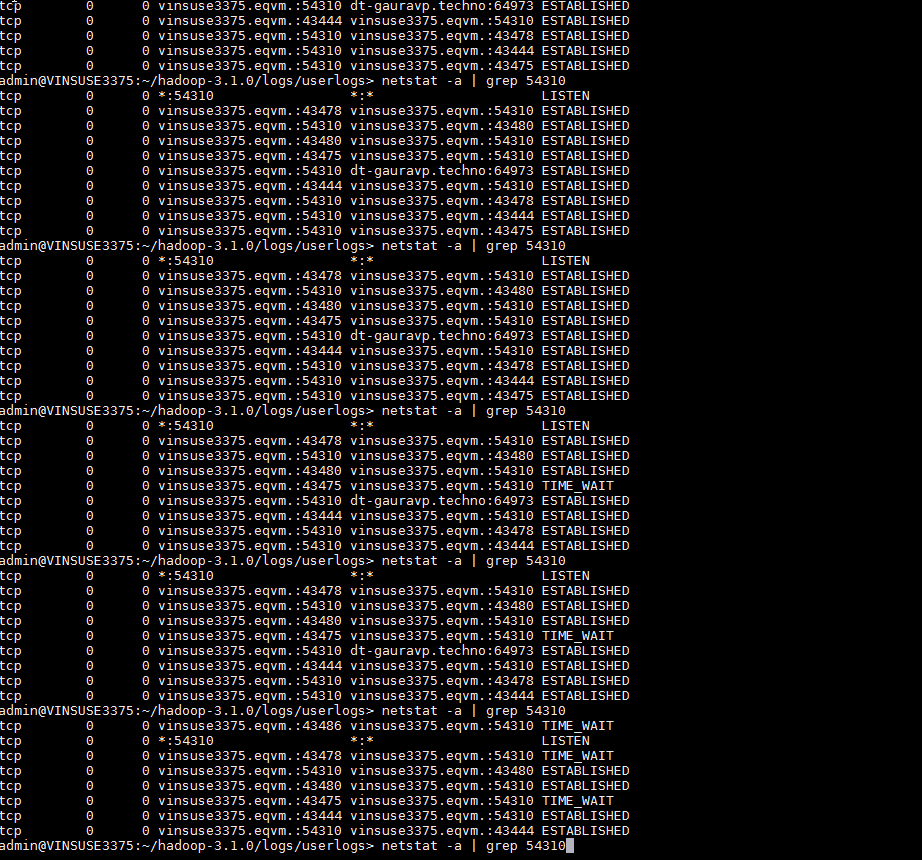{kind=link}
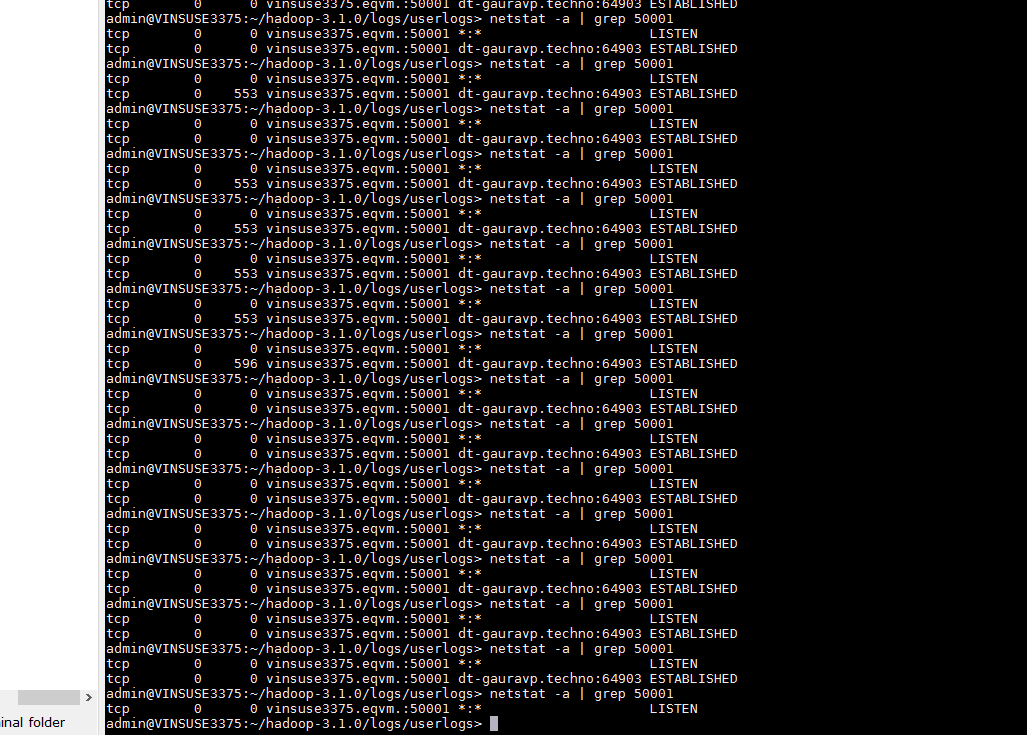{kind=link}
I am stuck here from last 5 days. Please help me. Thanks in advance.