If you're dealing with a fairly trivial pattern, where letters are based only off of the previous one, then you're spot on that a Hidden Markov Model (HMM) would solve it - in fact something as simple as a Markov Chain would work.
If you want to have a little fun, then here's a custom solution based on the HMM that you can fiddle around with.
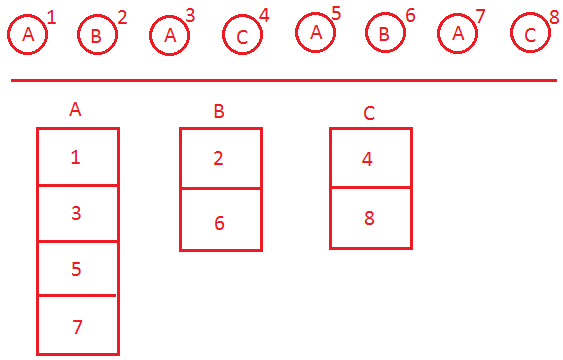
Go over the sample data, and create a linked list of every element, in the order they were inserted. Now make another list for each different character, and put the index of every list element where it belongs. Here's a (very poorly drawn) visual representation of the linked list, and the buckets below it:
![Linked list above arrays]()
Now when you are presented a sequence, and asked to predict the next character, all you have to do is look at the most recent X characters, and see how sub-sequences that were similar to it acted.
To use my example above, then look at the most recent (the last) 3 characters to get BAC. You want to see if the sequence BAC has ever happened before, and what came after it when it did happen. If you check the bucket for the first letter of BAC (the B), you can see that the letter B showed up once before. Thankfully it follows the sequence - and an A came after it, so that will be the prediction.
You might want to not only check sequences of the past X, but also every number below X, giving each one less weight if the sequence matches, to create a better heuristic.
The difficult part is deciding how far behind to look - if you look too far, it'll take too long, and you might not get any matches. If you look too short, then you might miss a pattern, and have to guess.
Good luck - hopefully this is nice and easy to implement, and works for you.