I have to extract text from PDF pages as it is with the indentation into a CSV file.
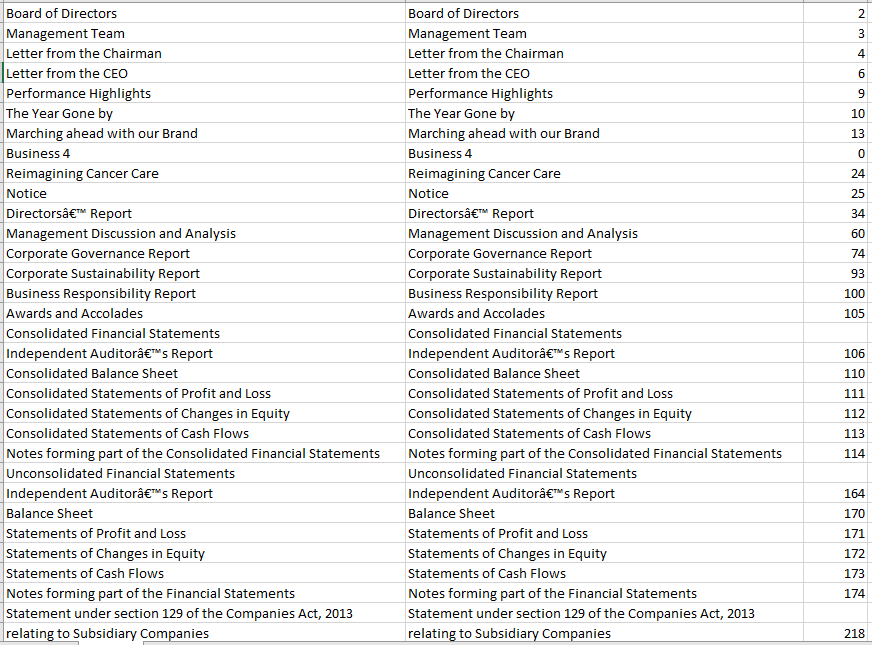
Index page from PDF text book:

I should split the text into class and subclass type hierarchy along with the page numbers. For example in the image, Application server is the class and Apache Tomcat is the subclass in the page number 275
This is the expected output of the CSV:

I have used Tika parser to parse the PDF, but the indentation is not maintained properly (not unique) in the parsed content for splitting the text into class and subclasses.
This is how the parsed text looks like:

Can anyone suggest me the right approach for this requirement?