Problem
I am trying to use 5 years of consecutive, historical data to forecast values for the following year.
Data Structure
My input data input_04_08 looks like this where the first column is the day of the year (1 to 365) and the second column is the recorded input.
1,2
2,2
3,0
4,0
5,0
My output data output_04_08 looks like this, a single column with the recorded output on that day of the year.
27.6
28.9
0
0
0
I then normalise the values between 0 and 1 so the first sample given to the network would look like
Number of training patterns: 1825
Input and output dimensions: 2 1
First sample (input, target):
[ 0.00273973 0.04 ] [ 0.02185273]
Approach(s)
Feed Forward Network
I have implemented the following code in PyBrain
input_04_08 = numpy.loadtxt('./data/input_04_08.csv', delimiter=',')
input_09 = numpy.loadtxt('./data/input_09.csv', delimiter=',')
output_04_08 = numpy.loadtxt('./data/output_04_08.csv', delimiter=',')
output_09 = numpy.loadtxt('./data/output_09.csv', delimiter=',')
input_04_08 = input_04_08 / input_04_08.max(axis=0)
input_09 = input_09 / input_09.max(axis=0)
output_04_08 = output_04_08 / output_04_08.max(axis=0)
output_09 = output_09 / output_09.max(axis=0)
ds = SupervisedDataSet(2, 1)
for x in range(0, 1825):
ds.addSample(input_04_08[x], output_04_08[x])
n = FeedForwardNetwork()
inLayer = LinearLayer(2)
hiddenLayer = TanhLayer(25)
outLayer = LinearLayer(1)
n.addInputModule(inLayer)
n.addModule(hiddenLayer)
n.addOutputModule(outLayer)
in_to_hidden = FullConnection(inLayer, hiddenLayer)
hidden_to_out = FullConnection(hiddenLayer, outLayer)
n.addConnection(in_to_hidden)
n.addConnection(hidden_to_out)
n.sortModules()
trainer = BackpropTrainer(n, ds, learningrate=0.01, momentum=0.1)
for epoch in range(0, 100000000):
if epoch % 10000000 == 0:
error = trainer.train()
print 'Epoch: ', epoch
print 'Error: ', error
result = numpy.array([n.activate(x) for x in input_09])
and this gave me the following result with final error of 0.00153840123381
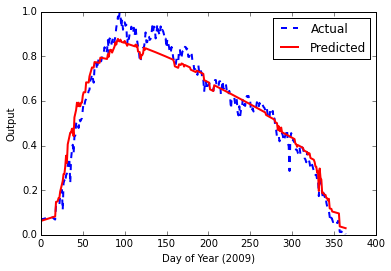
Admittedly, this looks good. However, having read more about LSTM (Long Short-Term Memory) neural networks, and there applicability to time series data, I am trying to build one.
LSTM Network
Below is my code
input_04_08 = numpy.loadtxt('./data/input_04_08.csv', delimiter=',')
input_09 = numpy.loadtxt('./data/input_09.csv', delimiter=',')
output_04_08 = numpy.loadtxt('./data/output_04_08.csv', delimiter=',')
output_09 = numpy.loadtxt('./data/output_09.csv', delimiter=',')
input_04_08 = input_04_08 / input_04_08.max(axis=0)
input_09 = input_09 / input_09.max(axis=0)
output_04_08 = output_04_08 / output_04_08.max(axis=0)
output_09 = output_09 / output_09.max(axis=0)
ds = SequentialDataSet(2, 1)
for x in range(0, 1825):
ds.newSequence()
ds.appendLinked(input_04_08[x], output_04_08[x])
fnn = buildNetwork( ds.indim, 25, ds.outdim, hiddenclass=LSTMLayer, bias=True, recurrent=True)
trainer = BackpropTrainer(fnn, ds, learningrate=0.01, momentum=0.1)
for epoch in range(0, 10000000):
if epoch % 100000 == 0:
error = trainer.train()
print 'Epoch: ', epoch
print 'Error: ', error
result = numpy.array([fnn.activate(x) for x in input_09])
This results in a final error of 0.000939719502501, but this time, when I feed the test data, the output plot looks terrible.
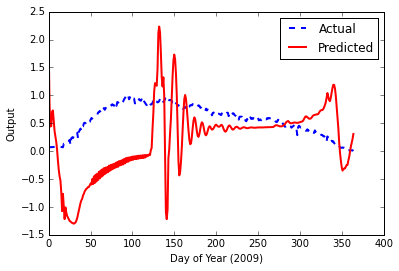
Possible Problems
I have looked around here at pretty much all the PyBrain questions, these stood out, but haven't helped me figure things out
- Training an LSTM neural network to forecast time series in pybrain, python
- Time Series Prediction via Neural Networks
- Time series forecasting (eventually with python)
I have read a few blog posts, these helped further my understanding a bit, but obviously not enough
Naturally, I have also gone through the PyBrain docs but couldn't find much to help with the sequential dataset bar here.
Any ideas/tips/direction would be welcome.