So today we run into a disturbing solr issue. After a restart of the whole cluster one of the shard stop being able to index/store documents. We had no hint about the issue until we started indexing (querying the server looks fine). The error is:
2014-05-19 18:36:20,707 ERROR o.a.s.u.p.DistributedUpdateProcessor [qtp406017988-19] ClusterState says we are the leader, but locally we don't think so
2014-05-19 18:36:20,709 ERROR o.a.s.c.SolrException [qtp406017988-19] org.apache.solr.common.SolrException: ClusterState says we are the leader (http://x.x.x.x:7070/solr/shard3_replica1), but locally we don't think so. Request came from null
at org.apache.solr.update.processor.DistributedUpdateProcessor.doDefensiveChecks(DistributedUpdateProcessor.java:503)
at org.apache.solr.update.processor.DistributedUpdateProcessor.setupRequest(DistributedUpdateProcessor.java:267)
at org.apache.solr.update.processor.DistributedUpdateProcessor.processAdd(DistributedUpdateProcessor.java:550)
at org.apache.solr.handler.loader.JsonLoader$SingleThreadedJsonLoader.processUpdate(JsonLoader.java:126)
at org.apache.solr.handler.loader.JsonLoader$SingleThreadedJsonLoader.load(JsonLoader.java:101)
at org.apache.solr.handler.loader.JsonLoader.load(JsonLoader.java:65)
at org.apache.solr.handler.UpdateRequestHandler$1.load(UpdateRequestHandler.java:92)
at org.apache.solr.handler.ContentStreamHandlerBase.handleRequestBody(ContentStreamHandlerBase.java:74)
at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:135)
at org.apache.solr.core.SolrCore.execute(SolrCore.java:1916)
We run Solr 4.7 in Cluster mode (5 shards) on jetty. Each shard run on a different host with one zookeeper server.
I checked the zookeeper log and I cannot see anything there.
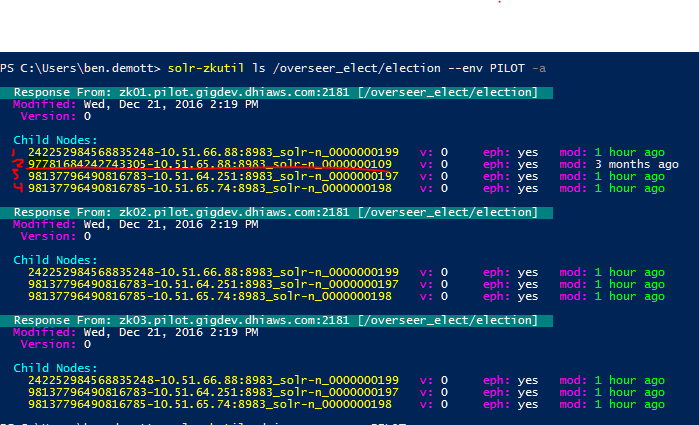
The only difference is that in the /overseer_election/election folder I see this specific server repeated 3 times, while the other server are only mentioned twice.
45654861x41276x432-x.x.x.x:7070_solr-n_00000003xx
74030267x31685x368-x.x.x.x:7070_solr-n_00000003xx
74030267x31685x369-x.x.x.x:7070_solr-n_00000003xx
Not even sure if this is relevant. (Can it be?) Any clue what other check can we do?