I have a load of 3 hour MP3 files, and every ~15 minutes a distinct 1 second sound effect is played, which signals the beginning of a new chapter.
Is it possible to identify each time this sound effect is played, so I can note the time offsets?
The sound effect is similar every time, but because it's been encoded in a lossy file format, there will be a small amount of variation.
The time offsets will be stored in the ID3 Chapter Frame MetaData.
Example Source, where the sound effect plays twice.
ffmpeg -ss 0.9 -i source.mp3 -t 0.95 sample1.mp3 -acodec copy -y
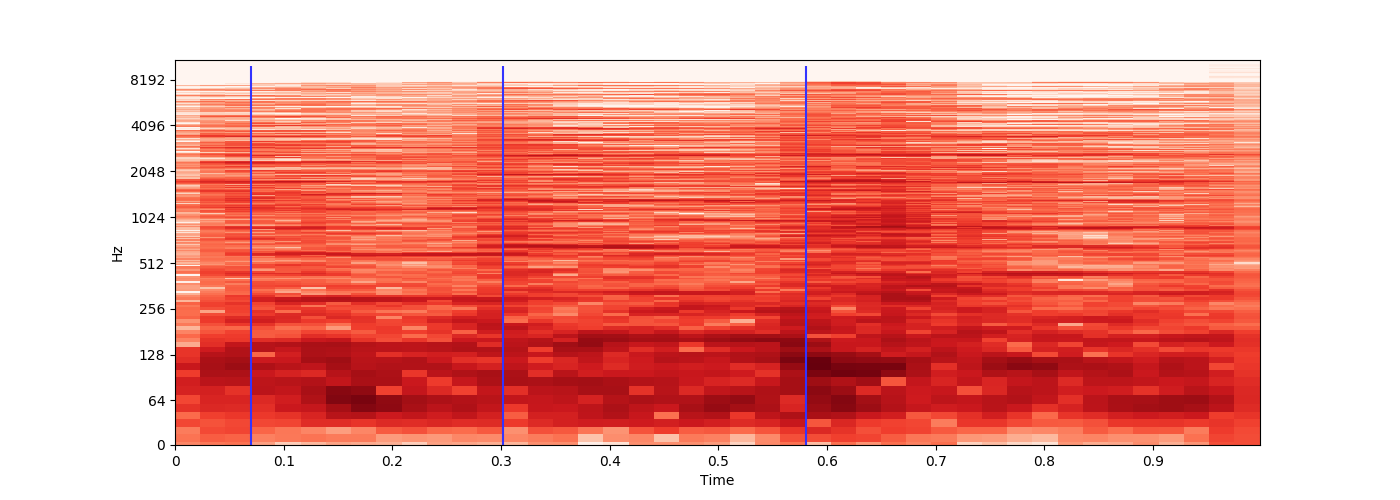{kind=link}
ffmpeg -ss 4.5 -i source.mp3 -t 0.95 sample2.mp3 -acodec copy -y
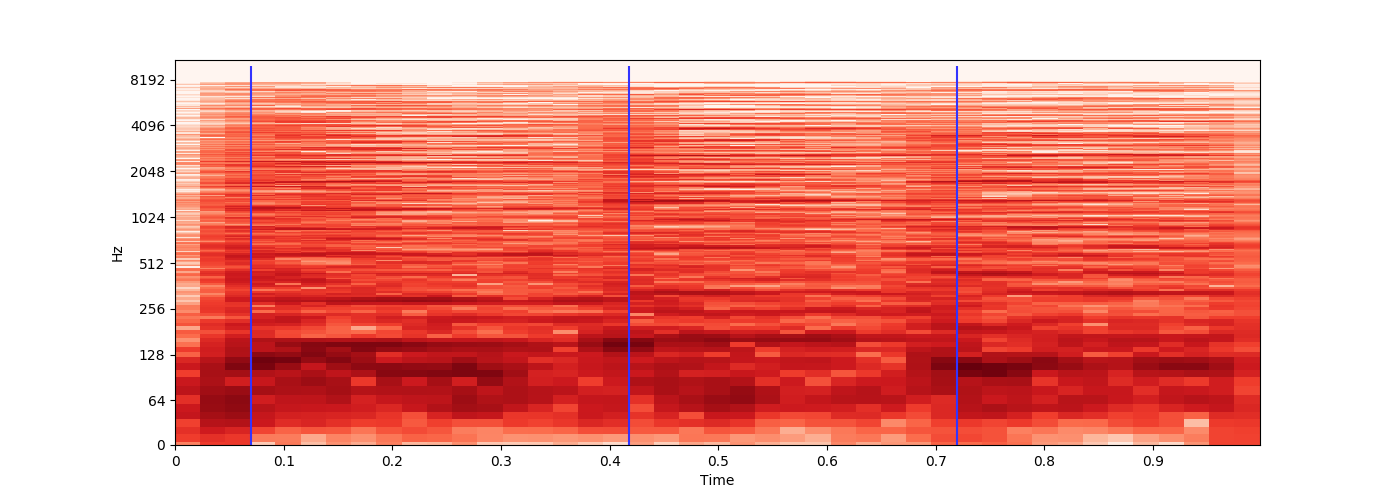{kind=link}
I'm very new to audio processing, but my initial thought was to extract a sample of the 1 second sound effect, then use librosa in python to extract a floating point time series for both files, round the floating point numbers, and try to get a match.
import numpy
import librosa
print("Load files")
source_series, source_rate = librosa.load('source.mp3') # 3 hour file
sample_series, sample_rate = librosa.load('sample.mp3') # 1 second file
print("Round series")
source_series = numpy.around(source_series, decimals=5);
sample_series = numpy.around(sample_series, decimals=5);
print("Process series")
source_start = 0
sample_matching = 0
sample_length = len(sample_series)
for source_id, source_sample in enumerate(source_series):
if source_sample == sample_series[sample_matching]:
sample_matching += 1
if sample_matching >= sample_length:
print(float(source_start) / source_rate)
sample_matching = 0
elif sample_matching == 1:
source_start = source_id;
else:
sample_matching = 0
This does not work with the MP3 files above, but did with an MP4 version - where it was able to find the sample I extracted, but it was only that one sample (not all 12).
I should also note this script takes just over 1 minute to process the 3 hour file (which includes 237,426,624 samples). So I can imagine that some kind of averaging on every loop would cause this to take considerably longer.
frames_to_time, but must admit I'm not sure I'm going about it in the right way (will keep trying though). Thanks again. – Phagocyte