I am aggregating data from a Postgres table, the query is taking approx 2 seconds which I want to reduce to less than a second.
Please find below the execution details:
Query
select
a.search_keyword,
hll_cardinality( hll_union_agg(a.users) ):: int as user_count,
hll_cardinality( hll_union_agg(a.sessions) ):: int as session_count,
sum(a.total) as keyword_count
from
rollup_day a
where
a.created_date between '2018-09-01' and '2019-09-30'
and a.tenant_id = '62850a62-19ac-477d-9cd7-837f3d716885'
group by
a.search_keyword
order by
session_count desc
limit 100;
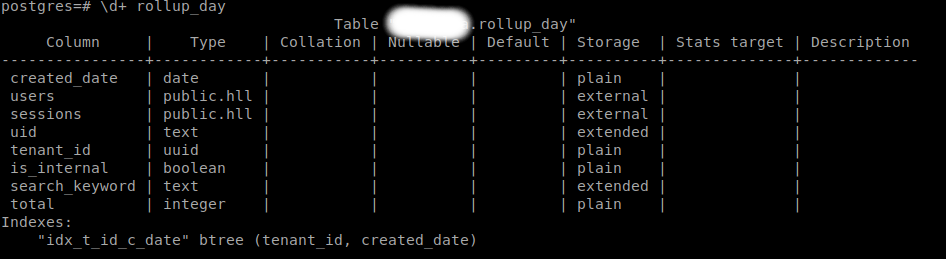
Table metadata
- Total number of rows - 506527
- Composite Index on columns : tenant_id and created_date
Query plan
Custom Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1722.685..1722.694 rows=100 loops=1)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=localhost port=5454 dbname=postgres
-> Limit (cost=64250.24..64250.49 rows=100 width=42) (actual time=1783.087..1783.106 rows=100 loops=1)
-> Sort (cost=64250.24..64558.81 rows=123430 width=42) (actual time=1783.085..1783.093 rows=100 loops=1)
Sort Key: ((hll_cardinality(hll_union_agg(sessions)))::integer) DESC
Sort Method: top-N heapsort Memory: 33kB
-> GroupAggregate (cost=52933.89..59532.83 rows=123430 width=42) (actual time=905.502..1724.363 rows=212633 loops=1)
Group Key: search_keyword
-> Sort (cost=52933.89..53636.53 rows=281055 width=54) (actual time=905.483..1351.212 rows=280981 loops=1)
Sort Key: search_keyword
Sort Method: external merge Disk: 18496kB
-> Seq Scan on rollup_day a (cost=0.00..17890.22 rows=281055 width=54) (actual time=29.720..112.161 rows=280981 loops=1)
Filter: ((created_date >= '2018-09-01'::date) AND (created_date <= '2019-09-30'::date) AND (tenant_id = '62850a62-19ac-477d-9cd7-837f3d716885'::uuid))
Rows Removed by Filter: 225546
Planning Time: 0.129 ms
Execution Time: 1786.222 ms
Planning Time: 0.103 ms
Execution Time: 1722.718 ms
What I've tried
- I've tried with indexes on tenant_id and created_date but as the data is huge so it's always doing sequence scan rather than an index scan for filters. I've read about it and found, the Postgres query engine switch to sequence scan if the data returned is > 5-10% of the total rows. Please follow the link for more reference.
- I've increased the work_mem to 100MB but it only improved the performance a little bit.
Any help would be really appreciated.
Update
Query plan after setting work_mem to 100MB
Custom Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1375.926..1375.935 rows=100 loops=1)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=localhost port=5454 dbname=postgres
-> Limit (cost=48348.85..48349.10 rows=100 width=42) (actual time=1307.072..1307.093 rows=100 loops=1)
-> Sort (cost=48348.85..48633.55 rows=113880 width=42) (actual time=1307.071..1307.080 rows=100 loops=1)
Sort Key: (sum(total)) DESC
Sort Method: top-N heapsort Memory: 35kB
-> GroupAggregate (cost=38285.79..43996.44 rows=113880 width=42) (actual time=941.504..1261.177 rows=172945 loops=1)
Group Key: search_keyword
-> Sort (cost=38285.79..38858.52 rows=229092 width=54) (actual time=941.484..963.061 rows=227261 loops=1)
Sort Key: search_keyword
Sort Method: quicksort Memory: 32982kB
-> Seq Scan on rollup_day_104290 a (cost=0.00..17890.22 rows=229092 width=54) (actual time=38.803..104.350 rows=227261 loops=1)
Filter: ((created_date >= '2019-01-01'::date) AND (created_date <= '2019-12-30'::date) AND (tenant_id = '62850a62-19ac-477d-9cd7-837f3d716885'::uuid))
Rows Removed by Filter: 279266
Planning Time: 0.131 ms
Execution Time: 1308.814 ms
Planning Time: 0.112 ms
Execution Time: 1375.961 ms
Update 2
After creating an index on created_date and increased work_mem to 120MB
create index date_idx on rollup_day(created_date);
The total number of rows is: 12,124,608
Query Plan is:
Custom Scan (cost=0.00..0.00 rows=0 width=0) (actual time=2635.530..2635.540 rows=100 loops=1)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=localhost port=9702 dbname=postgres
-> Limit (cost=73545.19..73545.44 rows=100 width=51) (actual time=2755.849..2755.873 rows=100 loops=1)
-> Sort (cost=73545.19..73911.25 rows=146424 width=51) (actual time=2755.847..2755.858 rows=100 loops=1)
Sort Key: (sum(total)) DESC
Sort Method: top-N heapsort Memory: 35kB
-> GroupAggregate (cost=59173.97..67948.97 rows=146424 width=51) (actual time=2014.260..2670.732 rows=296537 loops=1)
Group Key: search_keyword
-> Sort (cost=59173.97..60196.85 rows=409152 width=55) (actual time=2013.885..2064.775 rows=410618 loops=1)
Sort Key: search_keyword
Sort Method: quicksort Memory: 61381kB
-> Index Scan using date_idx_102913 on rollup_day_102913 a (cost=0.42..21036.35 rows=409152 width=55) (actual time=0.026..183.370 rows=410618 loops=1)
Index Cond: ((created_date >= '2018-01-01'::date) AND (created_date <= '2018-12-31'::date))
Filter: (tenant_id = '12850a62-19ac-477d-9cd7-837f3d716885'::uuid)
Planning Time: 0.135 ms
Execution Time: 2760.667 ms
Planning Time: 0.090 ms
Execution Time: 2635.568 ms
hll_union_aggneeds that much memory. – Adieu