I am bit surprised that the default (native) implementation of the hashCode() method appears ~50x slower than a simple override of the method for the following benchmark.
Consider a basic Book class that does not override hashCode():
public class Book {
private int id;
private String title;
private String author;
private Double price;
public Book(int id, String title, String author, Double price) {
this.id = id;
this.title = title;
this.author = author;
this.price = price;
}
}
Consider, alternatively, an otherwise identical Book class, BookWithHash, that overrides the hashCode() method using the default implementation from Intellij:
public class BookWithHash {
private int id;
private String title;
private String author;
private Double price;
public BookWithHash(int id, String title, String author, Double price) {
this.id = id;
this.title = title;
this.author = author;
this.price = price;
}
@Override
public boolean equals(final Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
final BookWithHash that = (BookWithHash) o;
if (id != that.id) return false;
if (title != null ? !title.equals(that.title) : that.title != null) return false;
if (author != null ? !author.equals(that.author) : that.author != null) return false;
return price != null ? price.equals(that.price) : that.price == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (title != null ? title.hashCode() : 0);
result = 31 * result + (author != null ? author.hashCode() : 0);
result = 31 * result + (price != null ? price.hashCode() : 0);
return result;
}
}
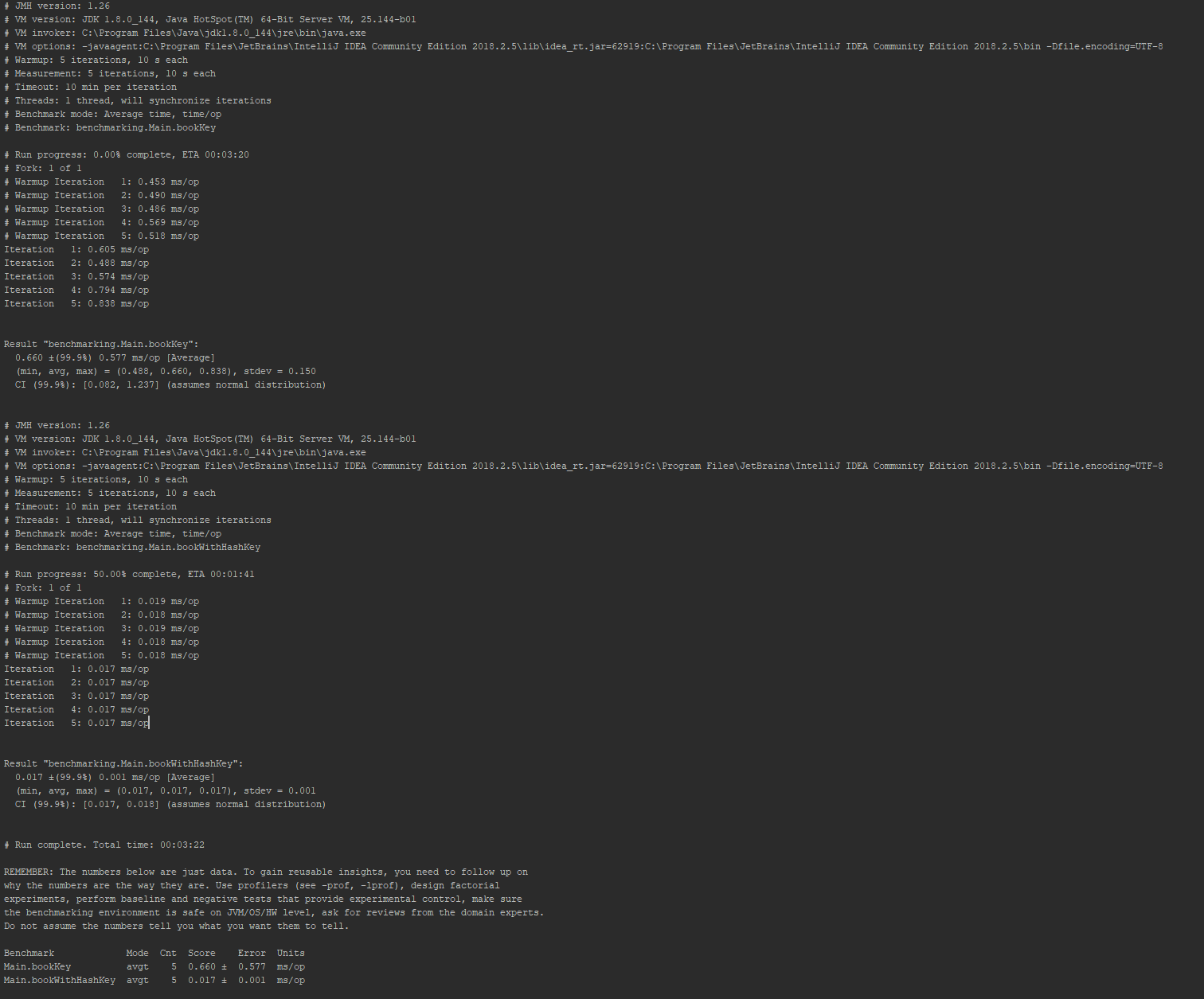
Then, the results of the following JMH benchmark suggests to me that the default hashCode() method from the Object class is almost 50x slower than the (seemingly more complex) implementation of hashCode() in the BookWithHash class:
public class Main {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder().include(Main.class.getSimpleName()).forks(1).build();
new Runner(opt).run();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public long bookWithHashKey() {
long sum = 0L;
for (int i = 0; i < 10_000; i++) {
sum += (new BookWithHash(i, "Jane Eyre", "Charlotte Bronte", 14.99)).hashCode();
}
return sum;
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public long bookKey() {
long sum = 0L;
for (int i = 0; i < 10_000; i++) {
sum += (new Book(i, "Jane Eyre", "Charlotte Bronte", 14.99)).hashCode();
}
return sum;
}
}
Indeed, the summarized results suggest that calling hashCode() on the BookWithHash class is an order of magnitude faster than calling hashCode() on the Book class (see below for full JMH output):

The reason I am surprised by this is that I understand the default Object.hashCode() implementation to (usually) be a hash of the initial memory address for the object, which (for the memory lookup at least) I would expect to be exceedingly fast at the microarchitecure level. These results seem to suggest to me that the hashing of the memory location is the bottleneck in Object.hashCode(), when compared to the simple override as given above. I would appreciate others' insights into my understanding and what could be causing this surprising behavior.
Full JMH output:
public int hashCode() { return 0;}in the nohash version, they both took about the same amount of time. – Poche