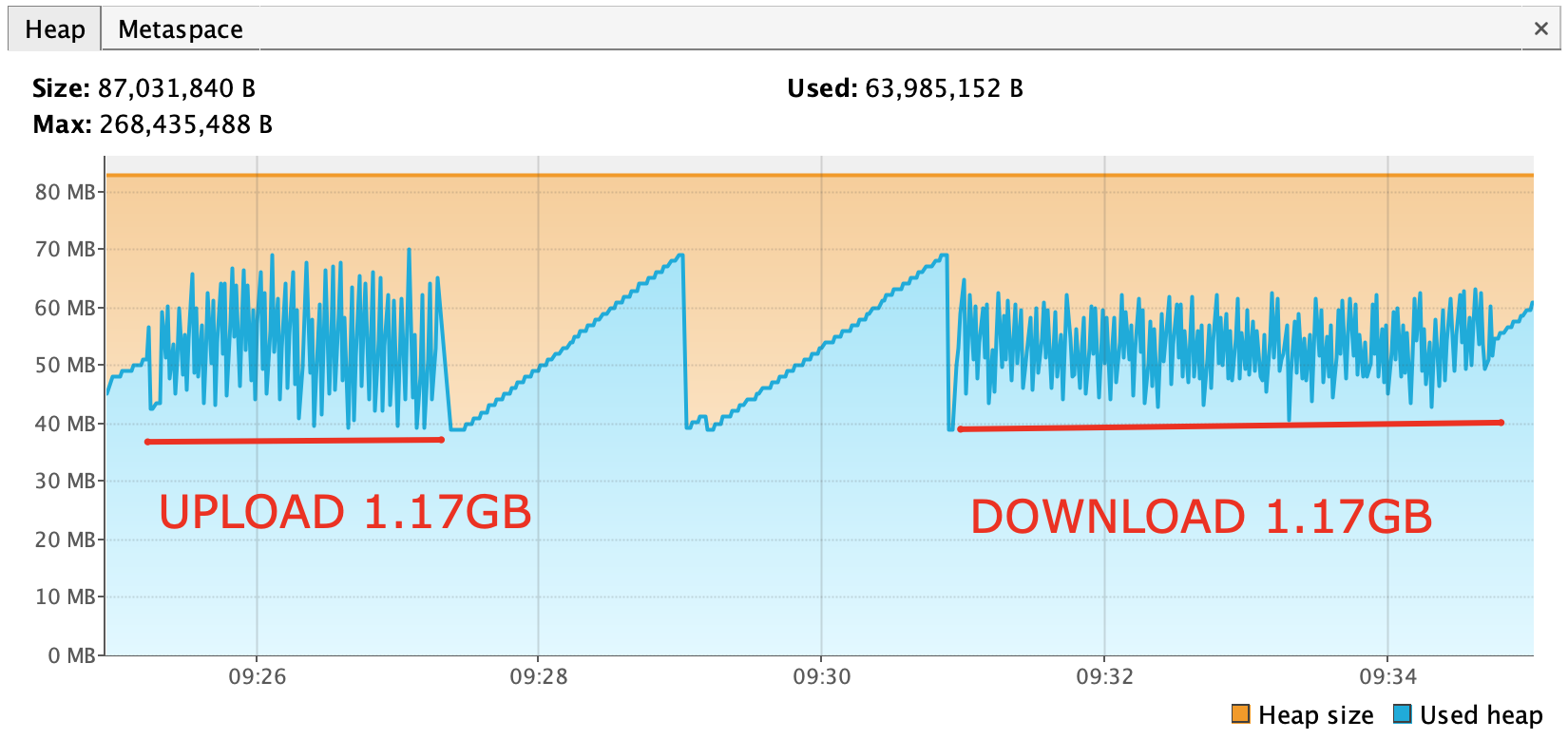
We are developing document microservice that needs to use Azure as a storage for file content. Azure Block Blob seemed like a reasonable choice. Document service has heap limited to 512MB (-Xmx512m).
I was not successful getting streaming file upload with limited heap to work using azure-storage-blob:12.10.0-beta.1 (also tested on 12.9.0).
Following approaches were attempted:
- Copy-paste from the documentation using
BlockBlobClient
BlockBlobClient blockBlobClient = blobContainerClient.getBlobClient("file").getBlockBlobClient();
File file = new File("file");
try (InputStream dataStream = new FileInputStream(file)) {
blockBlobClient.upload(dataStream, file.length(), true /* overwrite file */);
}
Result: java.io.IOException: mark/reset not supported - SDK tries to use mark/reset even though file input stream reports this feature as not supported.
- Adding
BufferedInputStreamto mitigate mark/reset issue (per advice):
BlockBlobClient blockBlobClient = blobContainerClient.getBlobClient("file").getBlockBlobClient();
File file = new File("file");
try (InputStream dataStream = new BufferedInputStream(new FileInputStream(file))) {
blockBlobClient.upload(dataStream, file.length(), true /* overwrite file */);
}
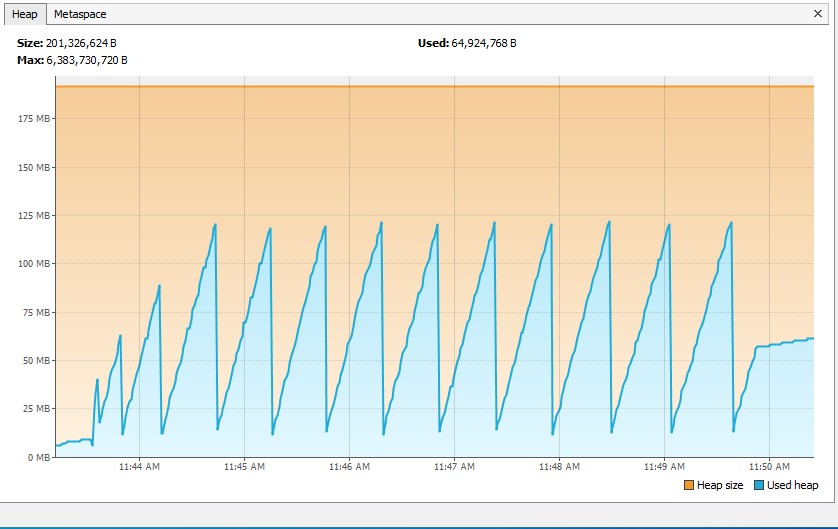
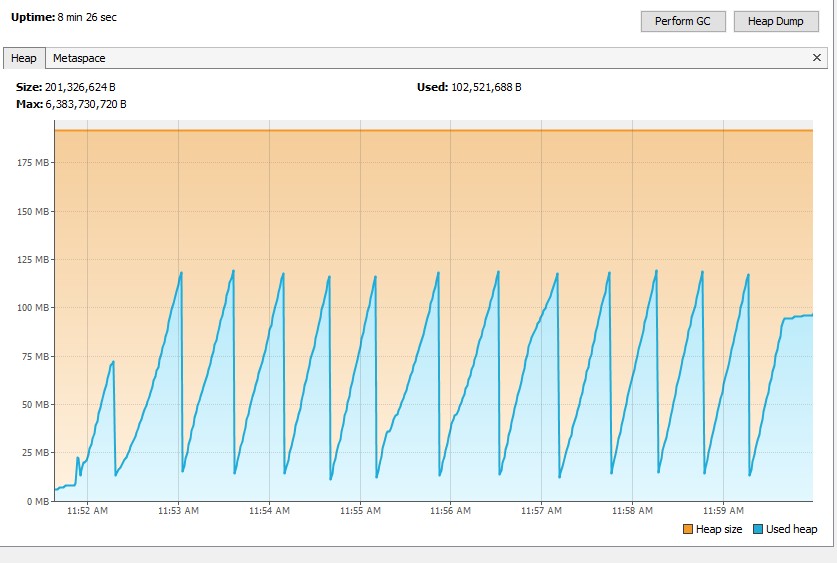
Result: java.lang.OutOfMemoryError: Java heap space. I assume that SDK attempted to load all 1.17GB of file content into memory.
- Replacing
BlockBlobClientwithBlobClientand removing heap size limitation (-Xmx512m):
BlobClient blobClient = blobContainerClient.getBlobClient("file");
File file = new File("file");
try (InputStream dataStream = new FileInputStream(file)) {
blobClient.upload(dataStream, file.length(), true /* overwrite file */);
}
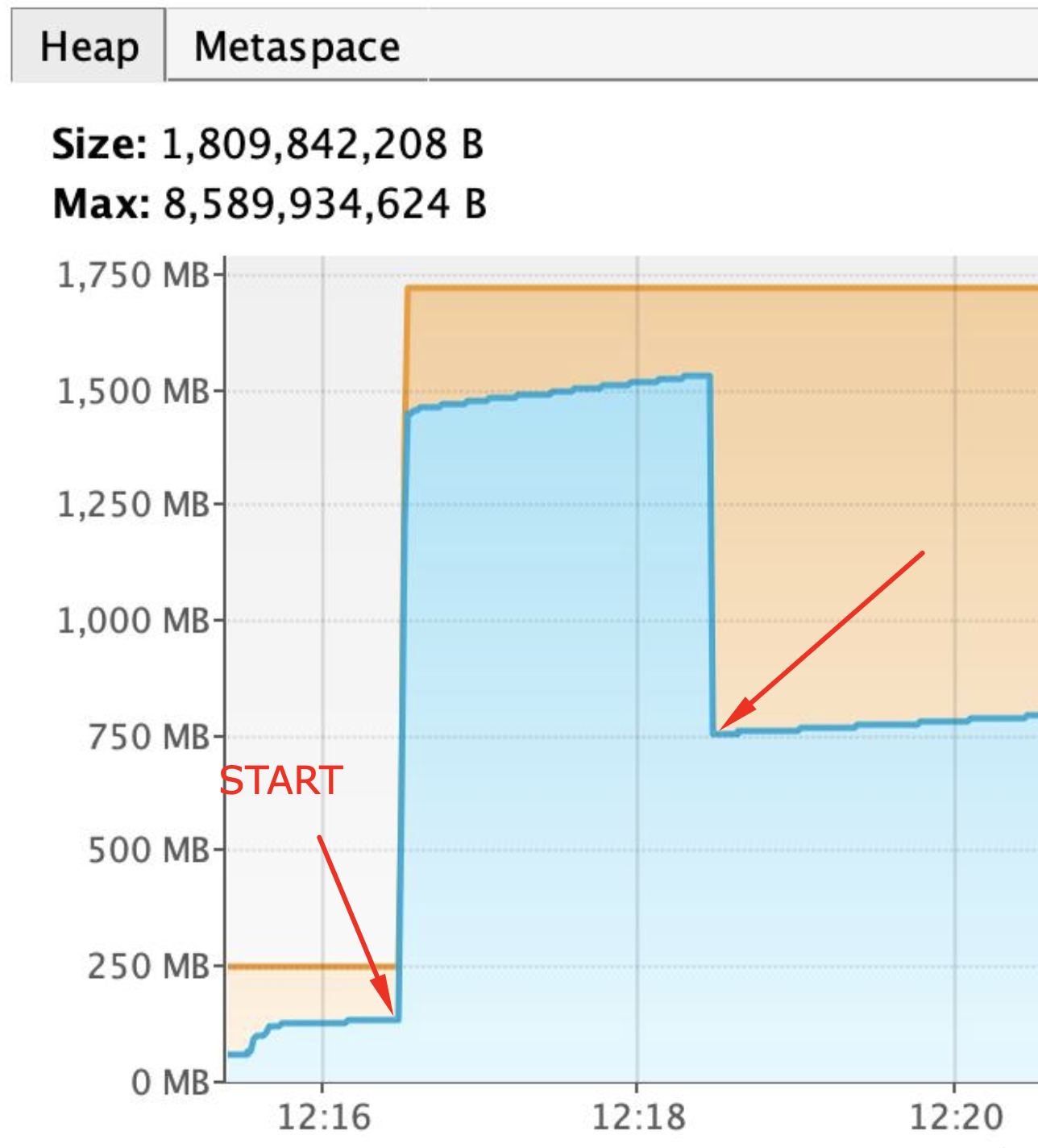
Result: 1.5GB of heap memory used, all file content is loaded into memory + some buffering on the side of Reactor
- Switch to streaming via
BlobOutputStream:
long blockSize = DataSize.ofMegabytes(4L).toBytes();
BlockBlobClient blockBlobClient = blobContainerClient.getBlobClient("file").getBlockBlobClient();
// create / erase blob
blockBlobClient.commitBlockList(List.of(), true);
BlockBlobOutputStreamOptions options = (new BlockBlobOutputStreamOptions()).setParallelTransferOptions(
(new ParallelTransferOptions()).setBlockSizeLong(blockSize).setMaxConcurrency(1).setMaxSingleUploadSizeLong(blockSize));
try (InputStream is = new FileInputStream("file")) {
try (OutputStream os = blockBlobClient.getBlobOutputStream(options)) {
IOUtils.copy(is, os); // uses 8KB buffer
}
}
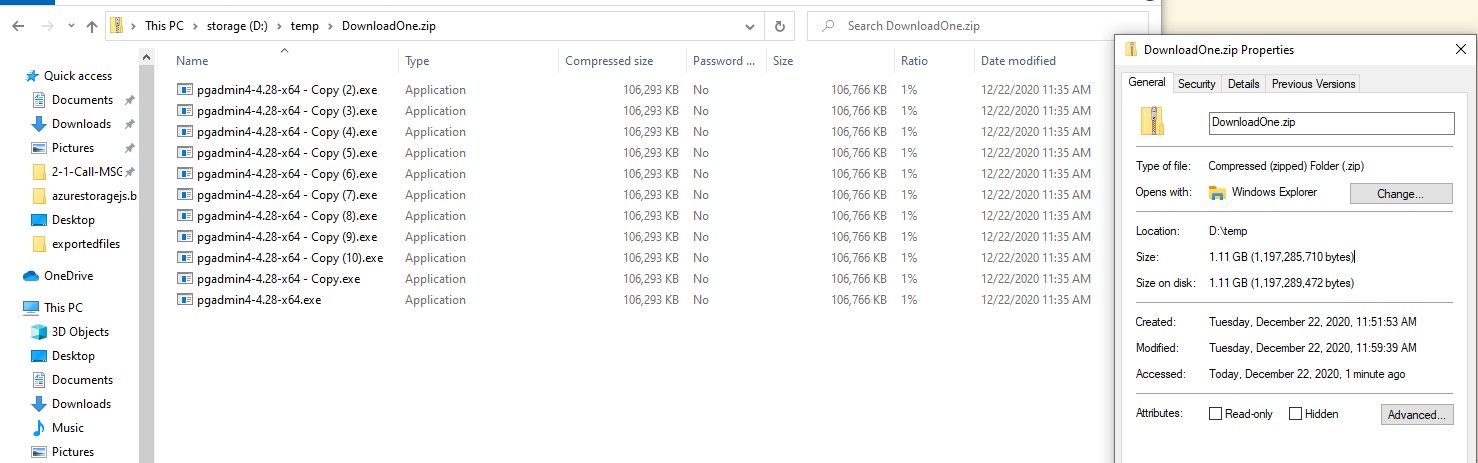
Result: file is corrupted during upload. Azure web portal shows 1.09GB instead of expected 1.17GB. Manual download of the file from Azure web portal confirms that file content was corrupted during upload. Memory footprint decreased significantly, but file corruption is a showstopper.
Problem: cannot come up with a working upload / download solution with small memory footprint
Any help would be greatly appreciated!
{kind=link}
{kind=link}
log.info("EXPECTED SIZE: {}; ACTUAL SIZE: {}", image.length(), blockBlobClient.getProperties().getBlobSize());Created this query in GitHub for sanity check: github.com/Azure/azure-sdk-for-java/issues/18295 – Prohibition