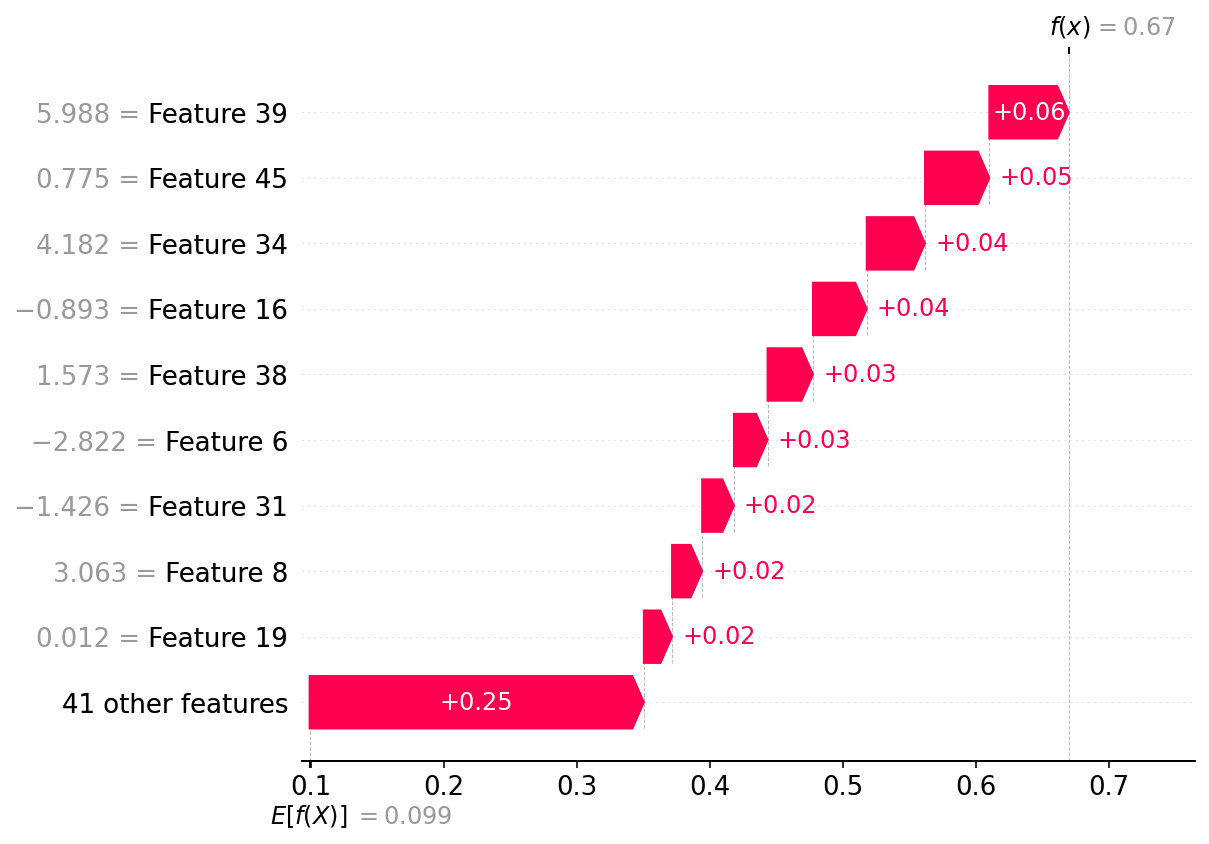
For the code given below, if I just use the command shap.plots.waterfall(shap_values[6]) I get the error
'numpy.ndarray' object has no attribute 'base_values'
I have to firstly run these two commands:
explainer2 = shap.Explainer(clf.best_estimator_.predict, X_train)
shap_values = explainer2(X_train)
and then run the waterfall command to get the correct plot. Below is an example of where the error occurs:
from sklearn.datasets import make_classification
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import pickle
import joblib
import warnings
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
f, (ax1,ax2) = plt.subplots(nrows=1, ncols=2,figsize=(20,8))
# Generate noisy Data
X_train,y_train = make_classification(n_samples=1000,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
X_test,y_test = make_classification(n_samples=500,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
model = RandomForestClassifier()
parameter_space = {
'n_estimators': [10,50,100],
'criterion': ['gini', 'entropy'],
'max_depth': np.linspace(10,50,11),
}
clf = GridSearchCV(model, parameter_space, cv = 5, scoring = "accuracy", verbose = True) # model
my_model = clf.fit(X_train,y_train)
print(f'Best Parameters: {clf.best_params_}')
# save the model to disk
filename = f'Testt-RF.sav'
pickle.dump(clf, open(filename, 'wb'))
explainer = Explainer(clf.best_estimator_)
shap_values_tr1 = explainer.shap_values(X_train)
shap.plots.waterfall(shap_values[6])
Can you tell me the correct procedure to generate the shap.plots.waterfall for the train data?
Thanks!