It seems that the answer provided by @bogumił-kamiński does not work with recent Julia versions. See this reproducible example run with Julia v1.8.5:
A = DataFrame(ID = [20,40], Name = ["John Doe", "Jane Doe"])
B = DataFrame(ID = [60,80], Job = ["Sailor", "Sommelier"])
C = DataFrame(Year = [1978, 1982], Test = ["Something", "Somewhere"])
for n in unique([names(A); names(B); names(C)]), df in [A,B,C]
n in names(df) || (df[n] = missing)
end
[A; B; C]
Produces the following error:
ERROR: ArgumentError: syntax df[column] is not supported use df[!, column] instead
With recent Julia versions (at least with v1.8.5), we need to replace (df[n] = missing) by (df[:, n] .= missing), that is using the syntax suggested by the error message, and adding a dot operator in before equals for in-place operation:
A = DataFrame(ID = [20,40], Name = ["John Doe", "Jane Doe"])
B = DataFrame(ID = [60,80], Job = ["Sailor", "Sommelier"])
C = DataFrame(Year = [1978, 1982], Test = ["Something", "Somewhere"])
for n in unique([names(A); names(B); names(C)]), df in [A,B,C]
n in names(df) || (df[:, n] .= missing)
end
[A; B; C]
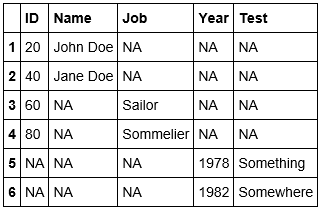
Which produces the following result:
6×5 DataFrame
Row │ ID Name Job Year Test
│ Int64? String? String? Int64? String?
─────┼──────────────────────────────────────────────────
1 │ 20 John Doe missing missing missing
2 │ 40 Jane Doe missing missing missing
3 │ 60 missing Sailor missing missing
4 │ 80 missing Sommelier missing missing
5 │ missing missing missing 1978 Something
6 │ missing missing missing 1982 Somewhere