The man page says that log shows the commit logs and reflog manages reflog information. What exactly is reflog information and what does it have that the log doesn't? The log seems far more detailed.
What's the difference between git reflog and log?
Asked Answered
git log shows the current HEAD and its ancestry. That is, it prints the commit HEAD points to, then its parent, its parent, and so on. It traverses back through the repo's ancestry, by recursively looking up each commit's parent.
(In practice, some commits have more than one parent. To see a more representative log, use a command like git log --oneline --graph --decorate.)
git reflog doesn't traverse HEAD's ancestry at all. The reflog is an ordered list of the commits that HEAD has pointed to: it's undo history for your repo. The reflog isn't part of the repo itself (it's stored separately to the commits themselves) and isn't included in pushes, fetches or clones; it's purely local.
Aside: understanding the reflog means you can't really lose data from your repo once it's been committed. If you accidentally reset to an older commit, or rebase wrongly, or any other operation that visually "removes" commits, you can use the reflog to see where you were before and git reset --hard back to that ref to restore your previous state. Remember, refs imply not just the commit but the entire history behind it.
A word of caution: you sometimes CAN lose data because reflog entries do not persist eternally - they are purged upon certain conditions. See this answer and the docs for git-reflog and git-gc. Generally, if the destructive operation was not more than 2 weeks ago, you most probably are safe. –
Asmara
@Asmara I have two local folders for the same repo, can I merge the reflogs for the two folders? –
Frau
@Tmx, I don't quite understand your case - what do you mean by two local folder for the same repo? If you have two clones of the same repo, which are up to date, and you want to "merge" their edit history, the
.git/logs/refs/<branch> entries have the format <old_rev> <new_rev> [...] <timestamp> [...]. You could try concatenating and sorting by timestamp. However, some lines' new_rev may not match the next one's old_rev, in which case I suspect the reflog will be invalid. You could then try inserting fake entries to "fix" the sequence, but it seems too much hassle to me. –
Asmara git logshows the commit log accessible from the refs (heads, tags, remotes)git reflogis a record of all commits that are or were referenced in your repo at any time.
That is why git reflog (a local recording which is pruned after 90 days by default) is used when you do a "destructive" operation (like deleting a branch), in order to get back the SHA1 that was referenced by that branch.
See git config:
gc.reflogexpire
gc.<pattern>.reflogexpire
git reflogexpire removes reflog entries older than this time; defaults to 90 days.
With "<pattern>" (e.g. "refs/stash") in the middle the setting applies only to the refs that match the<pattern>.

git reflog is often reference as "your safety net"
In case of trouble, the general advice, when git log doesn't show you what you are looking for, is:

Again, reflog is a local recording of your SHA1.
As opposed to git log: if you push your repo to an upstream repo, you will see the same git log, but not necessarily the same git reflog.
Here's the explanation of reflog from the Pro Git book:
One of the things Git does in the background while you’re working away is keep a reflog — a log of where your HEAD and branch references have been for the last few months.
You can see your reflog by using
git reflog:$ git reflog 734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive. 1c002dd... HEAD@{2}: commit: added some blame and merge stuff 1c36188... HEAD@{3}: rebase -i (squash): updating HEAD 95df984... HEAD@{4}: commit: # This is a combination of two commits. 1c36188... HEAD@{5}: rebase -i (squash): updating HEAD 7e05da5... HEAD@{6}: rebase -i (pick): updating HEADEvery time your branch tip is updated for any reason, Git stores that information for you in this temporary history. And you can specify older commits with this data, as well.
The reflog command can also be used to delete entries or expire entries from the reflog that are too old. From the official Linux Kernel Git documentation for reflog:
The subcommand
expireis used to prune older reflog entries.To delete single entries from the reflog, use the subcommand
deleteand specify the exact entry (e.g.git reflog delete master@{2}).
But doesn't the
git log provide you with the same information? Sorry if it seems obvious, I'm very new to GIT and would like to get some basics right before my first OMG. –
Complexioned Git log is a record of your commits. The reflog, as the Pro Git book states, is a record of your references (basically, your branch pointers and your
HEAD pointer), and which commits they have been pointing at. Does that make sense? On a side note, log can also show you reflog information, but you have to pass a special option flag as an argument to it, --walk-reflogs. –
Protean Also, since you're a Git beginner, I highly recommend you read the Pro Git book, it's how I learned most of what I learned about Git. I recommend chapters 1-3 and 6-6.5. I also highly recommend that you learn how to rebase both interactively and non-interactively. –
Protean
For future reference, git reflog has the newest change first. –
Canaday
I was curious about this as well and just want to elaborate and summarize a bit:
git logshows a history of all your commits for the branch you're on. Checkout a different branch and you'll see a different commit history. If you want to see you commit history for all branches, typegit log --all.git reflogshows a record of your references as Cupcake said. There is an entry each time a commit or a checkout it done. Try switching back and forth between two branches a few times usinggit checkoutand rungit reflogafter each checkout. You'll see the top entry being updated each time as a "checkout" entry. You do not see these types of entries ingit log.
References: http://www.lornajane.net/posts/2014/git-log-all-branches
I like to think of the difference between git log and reflog as being the difference between a private record and a public record.
Private vs public
With the git reflog, it keeps track of everything you've done locally. Did you commit? Reflog tracks it. Did you do a hard reset? Reflog tracks it. Did you amend a commit? Reflog tracks it. Everything you've done locally, there's an entry for it in the reflog.
This isn't true for the log. If you amend a commit, the log only shows the new commit. If you do a reset and skip back a few commits in your history, those commits you skipped over won't show up in the log. When you push your changes to another developer or to GitHub or something like that, only the content tracked in the log will appear. To another developer, it will look like the resets never happened or the amends never happened.
The log is polished. The reflog is lapidary.
So yeah, I like the 'private vs public' analogy. Or maybe a better log vs reflog analogy is 'polished vs lapidary.' The reflog shows all your trials and errors. The log just shows a clean and polished version of your work history.
Take a look at this image to emphasize the point. A number of amends and resets have occurred since the repository was initialized. The reflog shows all of it. Yet the log command makes it look as though there has only ever been one commit against the repo:
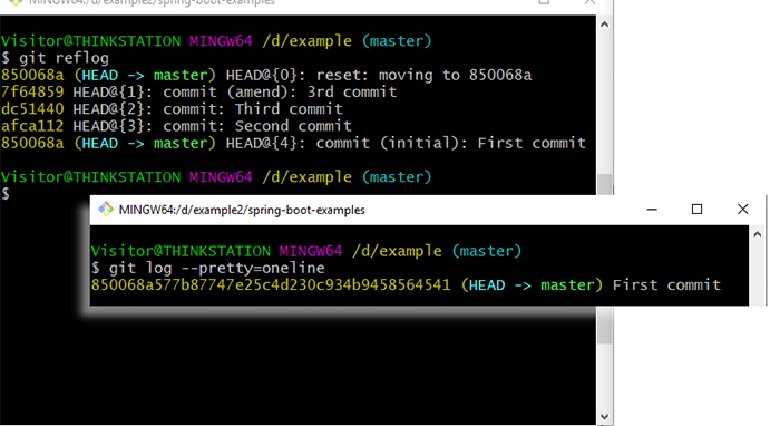
Back to the 'safety net' idea
Also, since the reflog keeps track of things you amended and commits you reset, it allows you to go back and find those commits because it'll give you the commit ids. Assuming your repository hasn't been purged of old commits, that allows you to resurrect items no longer visible in the log. That's how the reflog sometimes ends up saving someone's skin when they need to get back something they thought they inadvertently lost.
I found this answer the easiest to understand! thank you. –
Trover
McGoogle says: lap·i·dar·y /ˈlapəˌderē/ adjective -- relating to stone and gems and the work involved in engraving, cutting, or polishing. TL;DR: Un- or in the process of being polished. –
Precedency
git log will start from current HEAD, that is point to some branch (like master) or directly to commit object (sha code), and will actually scan the object files inside .git/objects directory commit after commit using the parent field that exist inside each commit object.
Experiment: point the HEAD directly to some commit: git checkout a721d (create new repo and populate it with commits and branches. replace a721d with some of your commit code) and delete the branches rm .git/refs/heads/*
Now git log --oneline will show only HEAD and its commits ancestors.
git reflog on the other hand is using direct log that is created inside .git/logs
Experiment: rm -rf .git/logs and git reflog is empty.
Anyway, even if you lose all tags and all branches and all logs inside logs folder, the commits objects are inside .git/objects directory so you can reconstruct the tree if you find all dangling commits: git fsck
Actually, reflog is an alias for
git log -g --abbrev-commit --pretty=oneline
so the answer should be: it is a specific case.
In
git log, -g is the short form for --walk-reflogs. So, that does not explain anything. –
Actinometer © 2022 - 2024 — McMap. All rights reserved.