This issue is very similar to the one discussed in this answer, and the appearance of the sample document there does also remind of the document here.
Just like in the case of the document in that other question, the ToUnicode map of the Devanagari script font used in the document here maps multiple completely different glyphs to identical Unicode code points. Thus, text extraction based on this mapping is bound to fail, and most text extractors rely on these information, especially in the absence of an font Encoding entry like here.
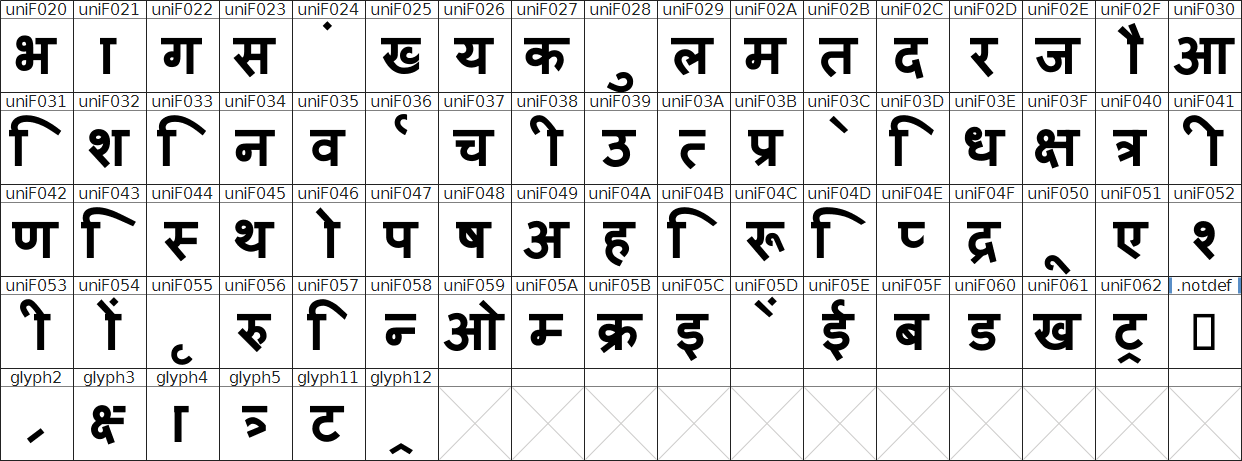
Some text extractors can use the mapping of glyph to Unicode contained in the embedded font program (if present). But checking this mapping in the Devanagari script font program used in the document here, it turns out that it associates most glyphs with U+f020 through U+f062 named "uniF020" etc.
![Compact UnicodeBmp]()
These Unicode code points are located in the Unicode Private Use Area, i.e. they do not have a standardized meaning but applications may use them as they like.
Thus, text extractors using the Unicode mapping contained in the font program wouldn't deliver immediately intelligible text either.
There is one fact, though, which can help you to mostly automatize text extraction from this document nonetheless: The same PDF object is referenced for the Devanagari script font on multiple pages, so on all pages referencing the same PDF object the same original character identifier or the same font program private use Unicode code point refer to the same visual symbol. In case of your document I counted only 5 copies of the font.
Thus, if you find a text extractor which either returns the character identifier (ignoring all toUnicode maps) or returns the private use area Unicode code points from the font program, you can use its output and merely replace each entry according to a few maps.
I had not yet have use for such a text extractor, so I don't know any in the python context. But who knows, probably pdfminer or any other similar package can be told (by some option) to ignore the misleading ToUnicode map and then be used as outlined above.