I was watching Systematic Error Handling in C++—Andrei Alexandrescu he claims that Exceptions in C++ are very very slow.
Is this still true for C++98?
I was watching Systematic Error Handling in C++—Andrei Alexandrescu he claims that Exceptions in C++ are very very slow.
Is this still true for C++98?
The main model used today for exceptions (Itanium ABI, VC++ 64 bits) is the Zero-Cost model exceptions.
The idea is that instead of losing time by setting up a guard and explicitly checking for the presence of exceptions everywhere, the compiler generates a side table that maps any point that may throw an exception (Program Counter) to the a list of handlers. When an exception is thrown, this list is consulted to pick the right handler (if any) and stack is unwound.
Compared to the typical if (error) strategy:
if when an exception does occurThe cost, however, is not trivial to measure:
dynamic_cast test for each handler)So, mostly cache misses, and thus not trivial compared to pure CPU code.
Note: for more details, read the TR18015 report, chapter 5.4 Exception Handling (pdf)
So, yes, exceptions are slow on the exceptional path, but they are otherwise quicker than explicit checks (if strategy) in general.
Note: Andrei Alexandrescu seems to question this "quicker". I personally have seen things swing both ways, some programs being faster with exceptions and others being faster with branches, so there indeed seems to be a loss of optimizability in certain conditions.
Does it matter ?
I would claim it does not. A program should be written with readability in mind, not performance (at least, not as a first criterion). Exceptions are to be used when one expects that the caller cannot or will not wish to handle the failure on the spot, and would rather pass it down the call stack. Bonus: in C++11 exceptions can be marshalled between threads using the Standard Library.
This is subtle though, I claim that map::find should not throw but I am fine with map::find returning a checked_ptr which throws if an attempt to dereference it fails because it's null: in the latter case, as in the case of the class that Alexandrescu introduced, the caller chooses between explicit check and relying on exceptions. Empowering the caller without giving him more responsibility is usually a sign of good design.
abort will allow you to measure the binary-size footprint and check that the load-time/i-cache behave similarly. Of course, better not hit any of the abort... –
Sorcerer f(); g(); h(); ... where f, g, h might throw so reordering can't happen, vs. C f(); g(); h();... where they don't throw. What @MatthieuM. is talking about is it is quicker to write in C++ f(); g(); h(); ... than in C++ if (f() == -1) return -1; if (g() == -1) return -1; if (h() == -1) return -1;. The point is, if you are using C++ and enables exception (STL won't work if you don't nowadays), 7% penalty is inevitable. It is quicker to use exception than return code in this case –
Sena std::bad_alloc, std::out_of_range and your custom ClientNotFound), the "matching" catch block may differ on a per-exception basis. Add in the fact that you may put a try around a call to a closed-source 3rd-party library, or a dynamically-linked library, and there is no way you can know at compile-time which exception is going to get thrown. –
Sorcerer throw does the stack lookup, multiple catches can just be put on the stack as though they were nested, the first of the multiple catches is put on the stack last (this would also implicitly do the catch matching we want). On exception throw just walk the stack backwards and find the first catch appropriate for that exception. –
Kamalakamaria Option/Result are clean way to signal the absence of value, or that an error occurred, and the ? operator to "bubble up" errors makes it very clean (and yet explicit) at the call site. Throw in panics for the "should be impossible" cases -- so as to avoid cluttering all result types -- and ergonomics are really good. –
Sorcerer When the question was posted I was on my way to the doctor, with a taxi waiting, so I only had time then for a short comment. But having now commented and upvoted and downvoted I’d better add my own answer. Even if Matthieu’s answer already is pretty good.
Re the claim
“I was watching Systematic Error Handling in C++—Andrei Alexandrescu he claims that Exceptions in C++ are very very slow.”
If that’s literally what Andrei claims, then for once he’s very misleading, if not downright wrong. For a raised/thrown exceptions is always slow compared to other basic operations in the language, regardless of the programming language. Not just in C++ or more so in C++ than in other languages, as the purported claim indicates.
In general, mostly regardless of language, the two basic language features that are orders of magnitude slower than the rest, because they translate to calls of routines that handle complex data structures, are
exception throwing, and
dynamic memory allocation.
Happily in C++ one can often avoid both in time-critical code.
Unfortunately There Ain’t No Such Thing As A Free Lunch, even if the default efficiency of C++ comes pretty close. :-) For the efficiency gained by avoiding exception throwing and dynamic memory allocation is generally achieved by coding at a lower level of abstraction, using C++ as just a “better C”. And lower abstraction means greater “complexity”.
Greater complexity means more time spent on maintenance and little or no benefit from code reuse, which are real monetary costs, even if difficult to estimate or measure. I.e., with C++ one can, if so desired, trade some programmer efficiency for execution efficiency. Whether to do so is largely an engineering and gut-feeling decision, because in practice only the gain, not the cost, can be easily estimated and measured.
Yes, the international C++ standardization committee has published a Technical Report on C++ performance, TR18015.
Mainly it means that a throw can take a Very Long Time™ compared to e.g. an int assignment, due to the search for handler.
As TR18015 discusses in its section 5.4 “Exceptions” there are two principal exception handling implementation strategies,
the approach where each try-block dynamically sets up exception catching, so that a search up the dynamic chain of handlers is performed when an exception is thrown, and
the approach where the compiler generates static look-up tables that are used to determine the handler for a thrown exception.
The first very flexible and general approach is almost forced in 32-bit Windows, while in 64-bit land and in *nix-land the second far more efficient approach is commonly used.
Also as that report discusses, for each approach there are three main areas where exception handling impacts on efficiency:
try-blocks,
regular functions (optimization opportunities), and
throw-expressions.
Mainly, with the dynamic handler approach (32-bit Windows) exception handling has an impact on try blocks, mostly regardless of language (because this is forced by Windows' Structured Exception Handling scheme), while the static table approach has roughly zero cost for try-blocks. Discussing this would take a lot more space and research than is practical for an SO answer. So, see the report for details.
Unfortunately the report, from 2006, is already a little bit dated as of late 2012, and as far as I know there’s not anything comparable that’s newer.
Another important perspective is that the impact of use of exceptions on performance is very different from the isolated efficiency of the supporting language features, because, as the report notes,
“When considering exception handling, it must be contrasted to alternative ways of dealing with errors.”
For example:
Maintenance costs due to different programming styles (correctness)
Redundant call site if failure checking versus centralized try
Caching issues (e.g. shorter code may fit in cache)
The report has a different list of aspects to consider, but anyway the only practical way to obtain hard facts about the execution efficiency is probably to implement the same program using exception and not using exceptions, within a decided cap on development time, and with developers familiar with each way, and then MEASURE.
Correctness almost always trumps efficiency.
Without exceptions, the following can easily happen:
Some code P is meant to obtain a resource or compute some information.
The calling code C should have checked for success/failure, but doesn't.
A non-existent resource or invalid information is used in code following C, causing general mayhem.
The main problem is point (2), where with the usual return code scheme the calling code C is not forced to check.
There are two main approaches that do force such checking:
Where P directly throws an exception when it fails.
Where P returns an object that C has to inspect before using its main value (otherwise an exception or termination).
The second approach was, AFAIK, first described by Barton and Nackman in their book *Scientific and Engineering C++: An Introduction with Advanced Techniques and Examples, where they introduced a class called Fallow for a “possible” function result. A similar class called optional is now offered by the Boost library. And you can easily implement an Optional class yourself, using a std::vector as value carrier for the case of non-POD result.
With the first approach the calling code C has no choice but to use exception handling techniques. With the second approach, however, the calling code C can itself decide whether to do if based checking, or general exception handling. Thus, the second approach supports making the programmer versus execution time efficiency trade-off.
“I want to know is this still true for C++98”
C++98 was the first C++ standard. For exceptions it introduced a standard hierarchy of exception classes (unfortunately rather imperfect). The main impact on performance was the possibility of exception specifications (removed in C++11), which however were never fully implemented by the main Windows C++ compiler Visual C++: Visual C++ accepts the C++98 exception specification syntax, but just ignores exception specifications.
C++03 was just a technical corrigendum of C++98. The only really new in C++03 was value initialization. Which has nothing to do with exceptions.
With the C++11 standard general exception specifications were removed, and replaced with the noexcept keyword.
The C++11 standard also added support for storing and rethrowing exceptions, which is great for propagating C++ exceptions across C language callbacks. This support effectively constrains how the current exception can be stored. However, as far as I know that does not impact on performance, except to the degree that in newer code exception handling may more easily be used on both sides of a C language callback.
for loop. it's true that Python (the only language I know where "ordinary flow control" involves exception) is very slow, but all is relative: throwing an exception involves both allocation and stack unwinding, so cannot be faster than mere allocation. IOW., throw/raise involves much more. –
Costumier longjmp to the handler. –
Cartwright try..finally construct can be implemented without stack unwinding. F#, C# and Java all implement try..finally without using stack unwinding. You just longjmp to the handler (as I already explained). –
Cartwright finally blocks (including implicit ones in with statements) in stack frames up the call stack, on the way up to an exception handler, is a stack unwinding. And it's logically impossible to have stack unwinding without having stack unwinding. You're again talking nonsense, sorry. –
Costumier int may be optimized by Visual C++, while the same function except for return type double may not necessarily be so optimized, and then presumably for reasons of efficiency, which ties in to architecture from 1979 (the x87 math co-processor for handling floating point operations)... :( –
Costumier You can never claim about performance unless you convert the code to the assembly or benchmark it.
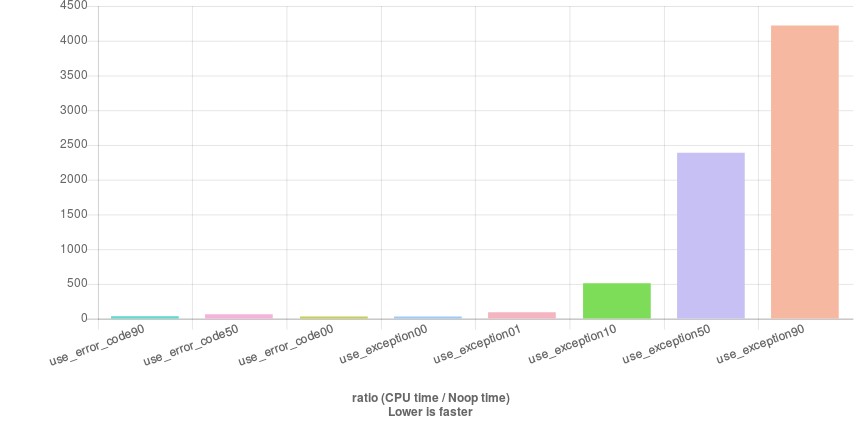
Here is what you see: (quick-bench)
The error code is not sensitive to the percentage of occurrence. Exceptions have a little bit overhead as long as they are never thrown. Once you throw them, the misery starts. In this example, it is thrown for 0%, 1%, 10%, 50% and 90% of the cases. When the exceptions are thrown 90% of the time, the code is 8 times slower than the case where the exceptions are thrown 10% of the time. As you see, the exceptions are really slow. Do not use them if they are thrown frequently. If your application has no real-time requirement, feel free to throw them if they occur very rarely.
You see many contradictory opinions about them. But finally, are exceptions are slow? I don't judge. Just watch the benchmark.
It depends on the compiler.
GCC, for example, was known for having very poor performance when handling exceptions, but this got considerably better in the past few years.
But note that handling exceptions should - as the name says - be the exception rather than the rule in your software design. When you have an application which throws so many exceptions per second that it impacts performance and this is still considered normal operation, then you should rather think about doing things differently.
Exceptions are a great way to make code more readable by getting all that clunky error handling code out of the way, but as soon as they become part of the normal program flow, they become really hard to follow. Remember that a throw is pretty much a goto catch in disguise.
throw new Exception is a Java-ism. one should as a rule never throw pointers. –
Costumier In this simple benchmark I did just now, throwing exceptions is nearly 250x slower than a normal bool return code.
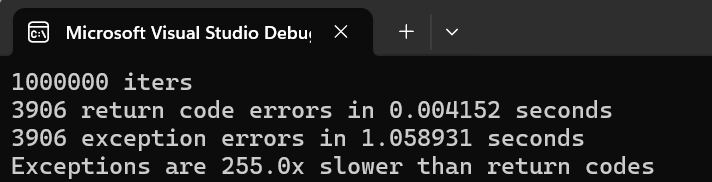
Don't believe me. Try it yourself.
struct StopWatch {
std::chrono::high_resolution_clock::time_point start;
StopWatch() {
reset();
}
void reset() {
start = std::chrono::high_resolution_clock::now();
}
unsigned long long milli() const {
std::chrono::high_resolution_clock::time_point stop = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(stop - start);
return ms.count();
}
double sec() const {
std::chrono::high_resolution_clock::time_point stop = std::chrono::high_resolution_clock::now();
return std::chrono::duration<double>(stop - start).count();
}
};
const static int N = 1000000;
bool increase( char& counter ) {
char prev = counter;
counter++;
return prev < counter; // false if overflow occurred
}
void increase_exc( char& counter ) {
char prev = counter;
counter++;
if( prev > counter ) {
// overflow occurred
throw std::exception( "Overflow" );
}
}
int main() {
StopWatch timer;
char count = 0;
int errors = 0;
for( int i = 0; i < N; i++ ) {
if( !increase( count ) ) {
errors++;
}
}
double retCode = timer.sec();
printf( "%d return code errors in %f seconds\n", errors, retCode );
count = 0;
errors = 0;
timer.reset();
for( int i = 0; i < N; i++ ) {
try {
increase_exc( count );
}
catch( std::exception& exc ) {
errors++;
}
}
double excTime = timer.sec();
printf( "%d exception errors in %f seconds\n", errors, excTime );
printf( "Exceptions are %.1fx slower than return codes", excTime / retCode );
}
Like in silico said its implementation dependent, but in general exceptions are considered slow for any implementation and shouldn't be used in performance intensive code.
EDIT: I'm not saying don't use them at all but for performance intensive code it is best to avoid them.
© 2022 - 2024 — McMap. All rights reserved.