So I implemented a transposition table in a Monte Carlo Tree Search algorithm using UCT. This allows for keeping a cumulative reward value for a game state, no matter where, and how many times, it is encountered throughout the tree. This increases the quality of the information gathered on the particular game state.
Alas, I have noticed that this creates certain problem with the exploitation vs. exploration selection phase of UCT. In short, the UCT score assigned to a state, takes into account the ratio between the number of times the parent state was visited and the number of times the child (whom we are calculating the UCT score for) was visited. As you can see from this diagram,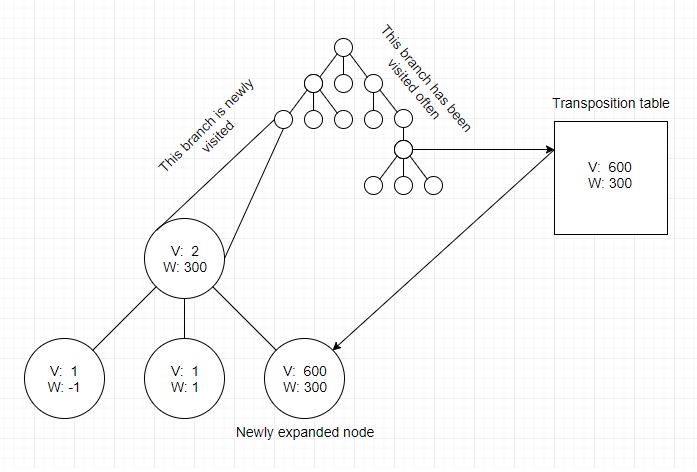 when pulling in a state from the transposition table into a newly created branch of the tree, that ratio is all out of whack, with the child state having been visited a great number of times (from elsewhere in the tree) and the parent state having been visited a much smaller amount of times, which should technically be impossible.
when pulling in a state from the transposition table into a newly created branch of the tree, that ratio is all out of whack, with the child state having been visited a great number of times (from elsewhere in the tree) and the parent state having been visited a much smaller amount of times, which should technically be impossible.
So, using a transposition table and persisting the cumulative reward value of a state helps the exploitation part of the algorithm make better choices, but at the same time it skews the exploitation part of the algorithm in a potentially harmful way. Are you aware of any ways to counteract this unintended problem?