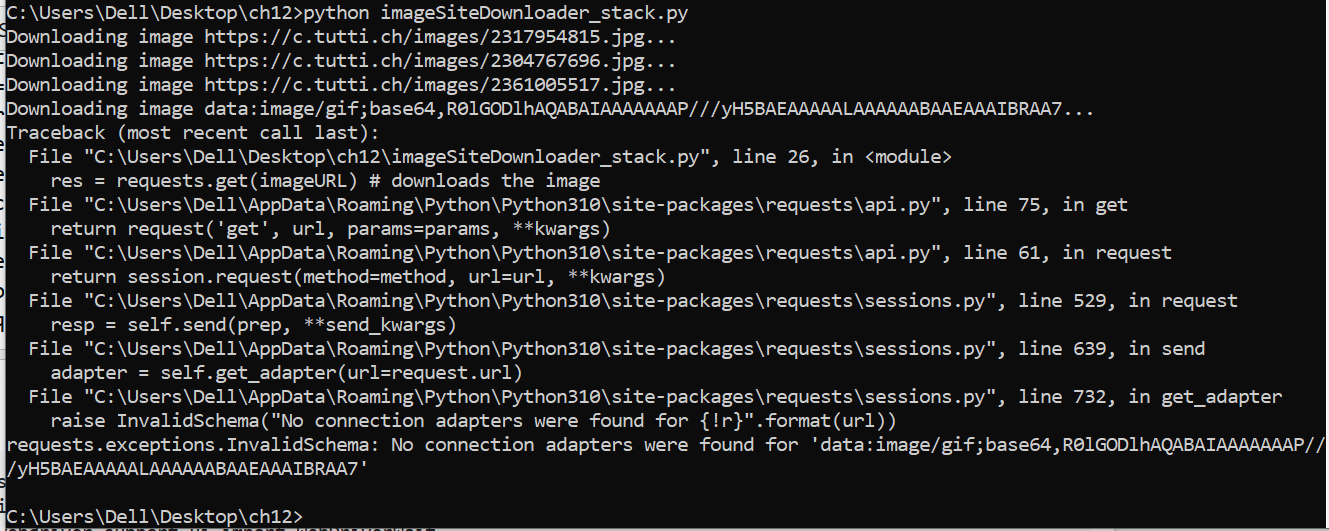
The program crashes, as you attempt to download a file (image) using a base64 encoded string (which is not a valid image URL). The reason these base64 strings show up in your images list is that each image (in <img> tags) appears to initially be a base64 string, and once it is loaded, the src value changes to a valid image url (you can check that by opening the DevTools in your browser while accessing your website at https://...ganze-schweiz?q=Gartenstuhl, and searching for "base64" in the Elements section of the DevTools. By moving to the next image in the search findings - using the arrow buttons - you'll notice the behaviour described above). This is also the reason (as shown in your cmd window snippet, and as tested it myself as well) that only 3 to 5 images are found and downloaded. That is because these 5 images are the ones appearing at the top of the page, and are succesfully loaded and given a valid image URL, when the page is accessed; whereas, the remaining <img> tags still include a base64 string.
So, the first step is - once the "search results" operation is completed- to slowly scroll down the page, in order for every image in the page to be loaded and given a valid URL. You can achieve that by using the method described here. You can adjust the speed as you wish, as long as it allows items/images to load properly.
The second step is to ensure that only valid URLs are passed to requests.get() method. Although every base64 string will be replaced by a valid URL due to the above fix, there might still be invalid image URLs in the list; in fact, there seems to be one (which is not related to the items) starting with https://bat.bing.com/action/0?t..... Thus, it is prudent to check that the requested URLs are valid image URLs, before attempting downloading them. You can do that by using str.endswith() method, looking for strings ending with specific suffixes (extensions), such as ".png" and ".jpg". If a string in the images list does end with any of the above extensions, you can then proceed downloading the image. Working example is given below (please note, the below will download the images appearing in the first page of search results. If you require downloading further image results, you can extend the program to navigate to the next page and then repeat the same steps as below).
Update 1
The code below has been updated, so that one can obtain further results by navigating to the following pages and downloading the images. You can set the number of "next pages" from which you would like to get results by adjusting the next_pages_no variable.
import requests, os
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
suffixes = (".png", ".jpg")
next_pages_no = 3
browser = webdriver.Firefox() # Opens Firefox webbrowser
#browser = webdriver.Chrome() # Opens Chrome webbrowser
wait = WebDriverWait(browser, 10)
os.makedirs('tuttiBilder', exist_ok=True)
def scroll_down_page(speed=40):
current_scroll_position, new_height= 0, 1
while current_scroll_position <= new_height:
current_scroll_position += speed
browser.execute_script("window.scrollTo(0, {});".format(current_scroll_position))
new_height = browser.execute_script("return document.body.scrollHeight")
def save_images(images):
for im in images:
imageURL = im.get_attribute('src') # gets the URL of the image
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL, stream=True) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(1024): # writes to the image file
imageFile.write(chunk)
imageFile.close()
def get_first_page_results():
browser.get('https://www.tutti.ch/')
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))).click() # accepts cookies terms
wait.until(EC.presence_of_element_located((By.XPATH, '//form//*[name()="input"][@data-automation="li-text-input-search"]'))).send_keys('Gartenstuhl') # enters search keyword
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button[id*='1-val-searchLabel']"))).click() # clicks submit button
scroll_down_page() # scroll down the page slowly for the images to load
images = browser.find_elements(By.TAG_NAME, 'img') # stores every img element in a list
save_images(images)
def get_next_page_results():
wait.until(EC.visibility_of_element_located((By.XPATH, '//button//*[name()="svg"][@data-testid="NavigateNextIcon"]'))).click()
scroll_down_page() # scroll down the page slowly for the images to load
images = browser.find_elements(By.TAG_NAME, 'img') # stores every img element in a list
save_images(images)
get_first_page_results()
for _ in range(next_pages_no):
get_next_page_results()
print('Done.')
browser.quit()
Update 2
As per your request, here is an alternative approach to the problem, using Python requests to download the HTML content of a given URL, as well as BeautifulSoup library to parse the content, in order to get the image URLs. As it appears in the HTML content, both base64 strings and actual image URLs are included (base64 strings occur exactly in the same number as image URLs). Thus, you can use the same approach as above to check for their suffixes, before proceeding downloading them. Complete working example below (adjust the page range in the for loop as you wish).
import requests
from bs4 import BeautifulSoup as bs
import os
suffixes = (".png", ".jpg")
os.makedirs('tuttiBilder', exist_ok=True)
def save_images(imageURLS):
for imageURL in imageURLS:
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL, stream=True) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(1024): # writes to the image file
imageFile.write(chunk)
imageFile.close()
def get_results(page_no, search_term):
response = requests.get('https://www.tutti.ch/de/li/ganze-schweiz?o=' + str(page_no) + '&q=' + search_term)
soup = bs(response.content, 'html.parser')
images = soup.findAll("img")
imageURLS = [image['src'] for image in images]
save_images(imageURLS)
for i in range(1, 4): # get results from page 1 to page 3
get_results(i, "Gartenstuhl")
Update 3
To clear things up, the base64 strings are all the same i.e., R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7. You can check this by saving the received HTML content in a file (to do this, please add the code below in the get_results() method of the second solution), opening it with a text editor and searching for "base64".
with open("page.html", 'wb') as f:
f.write(response.content)
If you enter the above base64 string into a "base64-to-image" converter online, then download and open the image with a graphics editor (such as Paint), you will see that it is a 1px image (usually called a "tracking pixel"). This "tracking pixel" is used in Web beacon technique to check that a user has accessed some content - in your case, a product in the list.
The base64 string is not an invalid URL that somehow turns into a valid one. It is an encoded image string, which can be decoded to recover the image. Thus, in the first solution using Selenium, when scrolling down on the page, those base64 strings are not converted into valid image URLs, but rather, tell the website that you have accessed some content, and then the website removes/hides them; that is the reason they do not show up in the results. The images (and hence, the image URLs) appear as soon as you scroll down to a product, as a common technique, called "Image Lazy Loading" is used (which is used to improve performance, user experience, etc.). Lazy-loading instructs the browser to defer loading of images that are off-screen until the user scrolls near them. In the second solution, since requests.get() is used to retrieve the HTML content, the base64 strings are still in the HTML document; one per each product. Again, those base64 strings are all the same, and are 1px images used for the purpose mentioned earlier. So, you don't need them in your results and should be ignored. Both solutions above download all the product images present in the webpage. You can check that by looking into the tuttiBilder folder, after running the programs. If you still, however, want to save those base64 images (which is worthless, as they are all the same and not useful), replace the save_images() method in the second solution (i.e., using BeautifulSoup) with the one below. Make sure to import the extra libraries (as shown below). The below will save all the base64 images, along with products' images, in the same tuttiBilder folder, assigning them unique identifiers as filenames (as they don't carry a filename).
import re
import base64
import uuid
def save_images(imageURLS):
for imageURL in imageURLS:
if imageURL.endswith(suffixes):
print('Downloading image %s...' % (imageURL))
res = requests.get(imageURL, stream=True) # downloads the image
res.raise_for_status()
imageFile = open(os.path.join('tuttiBilder', os.path.basename(imageURL)), 'wb') # creates an image file
for chunk in res.iter_content(1024): # writes to the image file
imageFile.write(chunk)
imageFile.close()
elif imageURL.startswith("data:image/"):
base64string = re.sub(r"^.*?/.*?,", "", imageURL)
image_as_bytes = str.encode(base64string) # convert string to bytes
recovered_img = base64.b64decode(image_as_bytes) # decode base64string
filename = os.path.join('tuttiBilder', str(uuid.uuid4()) + ".png")
with open(filename, "wb") as f:
f.write(recovered_img)