Goal
Aiming to have a CloudWatch Alert triggered when a message from an SQS queue to a lambda function exceeds the maximum retries.
Problem
I presumed that this would be easy and the NumberOfMessagesReceived metric would reflect this. Those familiar with this will know that this is not the case.
Solutions
The 'Limbo' Solution
My quick and easy solution for this problem was the introduce a "Limbo" which acts as the first DLQ and within seconds pushes the message to the final/actual DLQ. In the metrics this results in a spike in the "Limbo" queue's visible messages metric. So having an alert threshold of "> 0" means that every time that queue receives a message an alert can be issued.
However the powers above me are not happy with having a "Limbo" queue for every time we want this functionality.
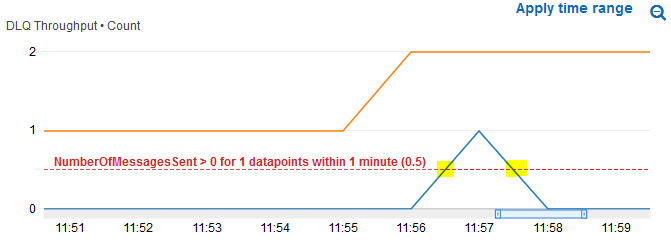
As far as I have been able to figure out there are some alternative methods but these seem worse than the Limbo Solution.
New Lambda Function
The first is to have a new lambda function that uses a SQS DLQ as a source and generates the alert.
Lambda Runtime Interception
Second is to have the have logic inside the existing lambdas (that process SQS messages) read the amount of times a message has gone been retried and on the final time generate the alert. This kind of removes the advantage of using a queue and a re-drive policy in the first place, and is an over engineered solution.
Metric Maths
The last alternative I can think of is to is to use some Metric Maths to look at the DLQ and calculate if there was been an increase in the last X minutes.
These all seem like strange and overly complex solutions to what (I am convinced) must have a simple implementation. How do I create an alert every time a DLQ receives a message?