I mistakenly added files to Git using the command:
git add myfile.txt
I have not yet run git commit. How do I undo this so that these changes will not be included in the commit?
I mistakenly added files to Git using the command:
git add myfile.txt
I have not yet run git commit. How do I undo this so that these changes will not be included in the commit?
git reset <file>
That will remove the file from the current index (the "about to be committed" list) without changing anything else.
git reset
In old versions of Git, the above commands are equivalent to git reset HEAD <file> and git reset HEAD respectively, and will fail if HEAD is undefined (because you haven't yet made any commits in your repository) or ambiguous (because you created a branch called HEAD, which is a stupid thing that you shouldn't do). This was changed in Git 1.8.2, though, so in modern versions of Git you can use the commands above even prior to making your first commit:
"git reset" (without options or parameters) used to error out when you do not have any commits in your history, but it now gives you an empty index (to match non-existent commit you are not even on).
Documentation: git reset
git add overwrote a previous staged uncommited version, we can't recover it. I tried to clarify this in my answer below. –
Coloratura git reset HEAD *.ext where ext is the files of the given extension you want to unadd. For me it was *.bmp & *.zip –
Bruise git rm --cached) it means you are preparing to make a commit that deletes that file. git reset HEAD <filename> on the other hand will copy the file from HEAD to the index, so that the next commit won't show any changes being made to that file. –
Pani git reset -p just like git add -p. This is awesome! –
Koppel -p most definitely is awesome, and it's used in a lot of git commands (not just reset and add). But to answer @WeDoTDD.com and @Johnny, git reset by itself just clears whether Git "knows about" the changes; it doesn't clear the changes themselves. To do that you need to do git checkout someFile.txt (for individual files) or git reset --hard (to wipe everything clean). There's no going back from either of these commands though, so be very careful when using them. –
Bosson git add you want to recover (61/3AF3... -> object id 613AF3...), then git cat-file -p <object-id> (might be worth it to recover several hours of work but also a lesson to commit more often...) –
Irredeemable git add is via git fsck --unreachable that will list all unreachable obj, which you can then inspect by git show SHA-1_ID or git fsck --lost-found that will >Write dangling objects into .git/lost-found/commit/ or .git/lost-found/other/, depending on type. See also git fsck --help –
Flaxman "git restore --staged <file>..." to unstage. See https://mcmap.net/q/12671/-why-there-are-two-ways-to-unstage-a-file-in-git –
Triphammer git reset */commonlib/styles/*.scss to locate all such files and it worked. –
Lush git reset <file> seemed to also delete the file from my file system as well, which is obviously not what you want. –
Related You want:
git rm --cached <added_file_to_undo>
Reasoning:
When I was new to this, I first tried
git reset .
(to undo my entire initial add), only to get this (not so) helpful message:
fatal: Failed to resolve 'HEAD' as a valid ref.
It turns out that this is because the HEAD ref (branch?) doesn't exist until after the first commit. That is, you'll run into the same beginner's problem as me if your workflow, like mine, was something like:
git initgit add .git status
... lots of crap scrolls by ...
=> Damn, I didn't want to add all of that.
google "undo git add"
=> find Stack Overflow - yay
git reset .
=> fatal: Failed to resolve 'HEAD' as a valid ref.
It further turns out that there's a bug logged against the unhelpfulness of this in the mailing list.
And that the correct solution was right there in the Git status output (which, yes, I glossed over as 'crap)
... # Changes to be committed: # (use "git rm --cached <file>..." to unstage) ...
And the solution indeed is to use git rm --cached FILE.
Note the warnings elsewhere here - git rm deletes your local working copy of the file, but not if you use --cached. Here's the result of git help rm:
--cached Use this option to unstage and remove paths only from the index. Working tree files, whether modified or not, will be left.
I proceed to use
git rm --cached .
to remove everything and start again. Didn't work though, because while add . is recursive, turns out rm needs -r to recurse. Sigh.
git rm -r --cached .
Okay, now I'm back to where I started. Next time I'm going to use -n to do a dry run and see what will be added:
git add -n .
I zipped up everything to a safe place before trusting git help rm about the --cached not destroying anything (and what if I misspelled it).
rm -rf .git, git init because I didn't trust git rm --cached to keep my working copy. It says a little for how git is still overly complex in some places. git unstage should just be a stock standard command, I don't care if I can add it as an alias. –
Desquamate git rm -r --cached . works fine –
Linneman git reset, try git reset * instead of git reset . - it un-stages all you previously staged files. –
Yolandoyolane git add -p –
Jollification git reset HEAD <File>... –
Vogul git stash/git stash pop to avoid zipping/backing up everything –
Kasten git add command added new files, but not changes to existing files. –
Punishment .git directory and initialising again is the best way. For cases in a well-used repo where you just accidentally added a single file, git rm --cached <file> seems best although I get a scary delete mode 100644 file after my commit. –
Koerlin git status output of git version 1.8.1.4 the correct way to unstage new files is: git reset HEAD <file>... –
Trula git reset to undo all added files or git reset <file> to undo a specific added file. git rm --cached may work on the surface but what actually happens is it removes it from the tracking history as well which is not what you would want to do, unless, you added that file to a gitignore file where that file shouldn't have been tracked in the first place then in that case it would be ok. –
Mush git rm --cached –
Mush git rm --cache <filename>, if the files already in index, but you don't want them to be in this commit, use git reset <filename> –
Silversmith git reset works if you accidentally stage all of your project files before adding your .gitignore. At least it worked for me. I suppose it's harder if you have already pushed to remote. –
Photoactinic If you type:
git status
Git will tell you what is staged, etc., including instructions on how to unstage:
use "git reset HEAD <file>..." to unstage
I find Git does a pretty good job of nudging me to do the right thing in situations like this.
Note: Recent Git versions (1.8.4.x) have changed this message:
(use "git rm --cached <file>..." to unstage)
added file was already being tracked (the add only saved a new version to the cache - here it will show your message). Elsewhere, if the file was not previously staged, it will display use "git rm --cached <file>..." to unstage –
Coloratura git reset HEAD <file> one is the only one that will work in case you want to unstage a file delete –
Sim git reset HEAD to unstage. –
Desmund git restore --staged <file>. See my answer below for an update. –
Vitek To clarify: git add moves changes from the current working directory to the staging area (index).
This process is called staging. So the most natural command to stage the changes (changed files) is the obvious one:
git stage
git add is just an easier-to-type alias for git stage
Pity there is no git unstage nor git unadd commands. The relevant one is harder to guess or remember, but it is pretty obvious:
git reset HEAD --
We can easily create an alias for this:
git config --global alias.unadd 'reset HEAD --'
git config --global alias.unstage 'reset HEAD --'
And finally, we have new commands:
git add file1
git stage file2
git unadd file2
git unstage file1
Personally I use even shorter aliases:
git a # For staging
git u # For unstaging
git stage is the alias for git add, which is the historic command, both on Git and other SCM. It has been added in december 2008 with commit 11920d28da in the "Git's git repository", if I can say. –
Lycanthrope git restore --staged path/fo/file for this purpose. –
Campman stage and unstage only to modify the cache/index/staging area which would be called "staging area" in all documentation and user interface. –
Campman stage / unstage) and on the background, the git impossible-to-learn commands are executed. And other users can still use the older commands ;) Something similar happens with JavaScript and Typescript –
Islamize git with custom aliases + git gui and gitk. For example, I do have git stage and git unstage. –
Campman An addition to the accepted answer, if your mistakenly-added file was huge, you'll probably notice that, even after removing it from the index with 'git reset', it still seems to occupy space in the .git directory.
This is nothing to be worried about; the file is indeed still in the repository, but only as a "loose object". It will not be copied to other repositories (via clone, push), and the space will be eventually reclaimed - though perhaps not very soon. If you are anxious, you can run:
git gc --prune=now
Update (what follows is my attempt to clear some confusion that can arise from the most upvoted answers):
So, which is the real undo of git add?
git reset HEAD <file> ?
or
git rm --cached <file>?
Strictly speaking, and if I'm not mistaken: none.
git add cannot be undone - safely, in general.
Let's recall first what git add <file> actually does:
If <file> was not previously tracked, git add adds it to the cache, with its current content.
If <file> was already tracked, git add saves the current content (snapshot, version) to the cache. In Git, this action is still called add, (not mere update it), because two different versions (snapshots) of a file are regarded as two different items: hence, we are indeed adding a new item to the cache, to be eventually committed later.
In light of this, the question is slightly ambiguous:
I mistakenly added files using the command...
The OP's scenario seems to be the first one (untracked file), we want the "undo" to remove the file (not just the current contents) from the tracked items. If this is the case, then it's ok to run git rm --cached <file>.
And we could also run git reset HEAD <file>. This is in general preferable, because it works in both scenarios: it also does the undo when we wrongly added a version of an already tracked item.
But there are two caveats.
First: There is (as pointed out in the answer) only one scenario in which git reset HEAD doesn't work, but git rm --cached does: a new repository (no commits). But, really, this a practically irrelevant case.
Second: Be aware that git reset HEAD can't magically recover the previously cached file contents, it just resynchronises it from the HEAD. If our misguided git add overwrote a previous staged uncommitted version, we can't recover it. That's why, strictly speaking, we cannot undo [*].
Example:
$ git init
$ echo "version 1" > file.txt
$ git add file.txt # First add of file.txt
$ git commit -m 'first commit'
$ echo "version 2" > file.txt
$ git add file.txt # Stage (don't commit) "version 2" of file.txt
$ git diff --cached file.txt
-version 1
+version 2
$ echo "version 3" > file.txt
$ git diff file.txt
-version 2
+version 3
$ git add file.txt # Oops we didn't mean this
$ git reset HEAD file.txt # Undo?
$ git diff --cached file.txt # No dif, of course. stage == HEAD
$ git diff file.txt # We have irrevocably lost "version 2"
-version 1
+version 3
Of course, this is not very critical if we just follow the usual lazy workflow of doing 'git add' only for adding new files (case 1), and we update new contents via the commit, git commit -a command.
* (Edit: the above is practically correct, but still there can be some slightly hackish/convoluted ways for recovering changes that were staged, but not committed and then overwritten - see the comments by Johannes Matokic and iolsmit)
git cat-file could be used to recover its content. –
Selina git add is via git fsck --unreachable that will list all unreachable obj, which you can then inspect by git show SHA-1_ID or git fsck --lost-found that will >Write dangling objects into .git/lost-found/commit/ or .git/lost-found/other/, depending on type. See also git fsck --help –
Flaxman git add overwrite a change that was staged but not committed? If I created a file a.txt and it had '1' as it's content, how can git add make it have '2' or sth else as it's content? Just looking for an explanation –
Lansquenet echo 1 > a.txt followed by git add a.txt - do not commit yet - echo 2 > a.txt followed by git add a.txt; now commit e.g. git commit -m "create unreachable blob" and run git fsck --unreachable –
Flaxman Undo a file which has already been added is quite easy using Git. For resetting myfile.txt, which have already been added, use:
git reset HEAD myfile.txt
Explanation:
After you staged unwanted file(s), to undo, you can do git reset. Head is head of your file in the local and the last parameter is the name of your file.
I have created the steps in the image below in more details for you, including all steps which may happen in these cases:

Git has commands for every action imaginable, but it needs extensive knowledge to get things right and because of that it is counter-intuitive at best...
What you did before:
git add ., or git add <file>.What you want:
Remove the file from the index, but keep it versioned and left with uncommitted changes in working copy:
git reset HEAD <file>
Reset the file to the last state from HEAD, undoing changes and removing them from the index:
# Think `svn revert <file>` IIRC.
git reset HEAD <file>
git checkout <file>
# If you have a `<branch>` named like `<file>`, use:
git checkout -- <file>
This is needed since git reset --hard HEAD won't work with single files.
Remove <file> from index and versioning, keeping the un-versioned file with changes in working copy:
git rm --cached <file>
Remove <file> from working copy and versioning completely:
git rm <file>
reset head undoes your current changes, but the file is still being monitored by git. rm --cached takes the file out of versioning, so git no longer checks it for changes (and also removes eventually indexed present changes, told to git by the prior add), but the changed file will be kept in your working copy, that is in you file folder on the HDD. –
Woodpecker git reset HEAD <file> is temporary - the command will be applied to the next commit only, but git rm --cached <file> will unstage untill it gets added again with git add <file>. Also, git rm --cached <file> means if you push that branch to the remote, anyone pulling the branch will get the file ACTUALLY deleted from their folder. –
Vergievergil git checkout -- <file> thanx ! –
Tiebout git rm --cached . -r
will "un-add" everything you've added from your current directory recursively
git reset HEAD <file> would say fatal: Failed to resolve 'HEAD' as a valid ref. –
Mccants Run
git gui
and remove all the files manually or by selecting all of them and clicking on the unstage from commit button.
git-gui...." :) –
Bonnett git: 'gui' is not a git command. See 'git --help'. –
Bekelja The question is not clearly posed. The reason is that git add has two meanings:
git rm --cached file.git reset HEAD file.If in doubt, use
git reset HEAD file
Because it does the expected thing in both cases.
Warning: if you do git rm --cached file on a file that was modified (a file that existed before in the repository), then the file will be removed on git commit! It will still exist in your file system, but if anybody else pulls your commit, the file will be deleted from their work tree.
git status will tell you if the file was a new file or modified:
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: my_new_file.txt
modified: my_modified_file.txt
git rm --cached somefile. I hope this answer makes its way up the page to a prominent position where it can protect newbies from being misled by all the false claims. –
Serotherapy As per many of the other answers, you can use git reset
BUT:
I found this great little post that actually adds the Git command (well, an alias) for git unadd: see git unadd for details or..
Simply,
git config --global alias.unadd "reset HEAD"
Now you can
git unadd foo.txt bar.txt
Alternatively / directly:
git reset HEAD foo.txt bar.txt
git add before commit? You just git unadd. This is the real answer 💯 –
Chokecherry git reset filename.txt
will remove a file named filename.txt from the current index (also called the “staging area”, which is where changes “about to be committed” are saved), without changing anything else (the working directory is not overwritten).
man git "Reset, restore and revert", supposedly explains these 3 similar overlapping commands (proliferation of commands indicates poor command structure in the first place), says git reset "changes commit history" yet here it doesn't? It also says git restore "does not update your branch". If nothing is changed what on earth is the command doing? What does "branch" actually mean? And here in your comment what does "anything else" mean? Sometimes people use an assumed context and following the advice can hurt. –
Schild As pointed out by others in related questions (see here, here, here, here, here, here, and here), you can now unstage a single file with:
git restore --staged <file>
and unstage all files (from the root of the repo) with:
git restore --staged .
git restore was introduced in July 2019 and released in version 2.23.
With the --staged flag, it restores the content of the index (what is asked here).
When running git status with staged uncommitted file(s), this is now what Git suggests to use to unstage file(s) (instead of git reset HEAD <file> as it used to prior to v2.23).
git restore --staged . differs from git reset .? –
Antre If you're on your initial commit and you can't use git reset, just declare "Git bankruptcy" and delete the .git folder and start over
git add -A && git rm --cached EXCLUDEFILE && git commit -m 'awesome commit' (This also works when there's no previous commits, re Failed to resolve 'HEAD' problem) –
Syreetasyria You can unstage or undo using the git command or GUI Git.
Single file
git reset File.txt
Multiple files
git reset File1.txt File2.txt File3.txt
Suppose you have added Home.js, ListItem.js, Update.js by mistake,
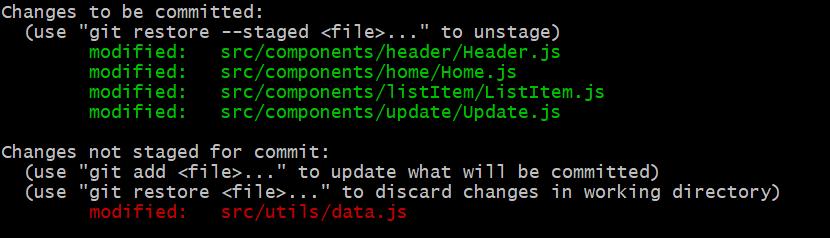
and want to undo/reset =>
git reset src/components/home/Home.js src/components/listItem/ListItem.js src/components/update/Update.js
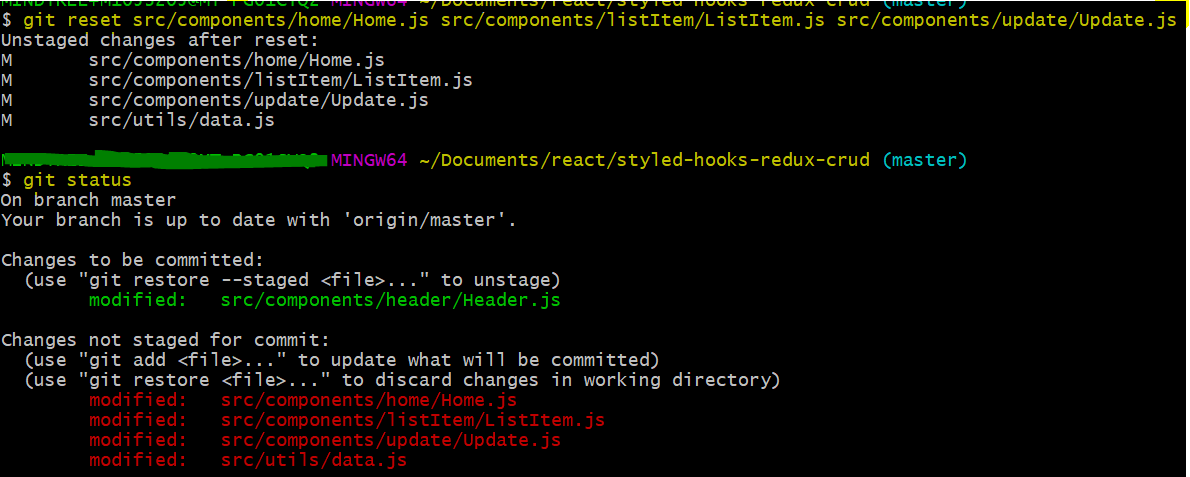
The same example using Git GUI
git gui
Opens a window. Uncheck your files from Staged changes (will commit)
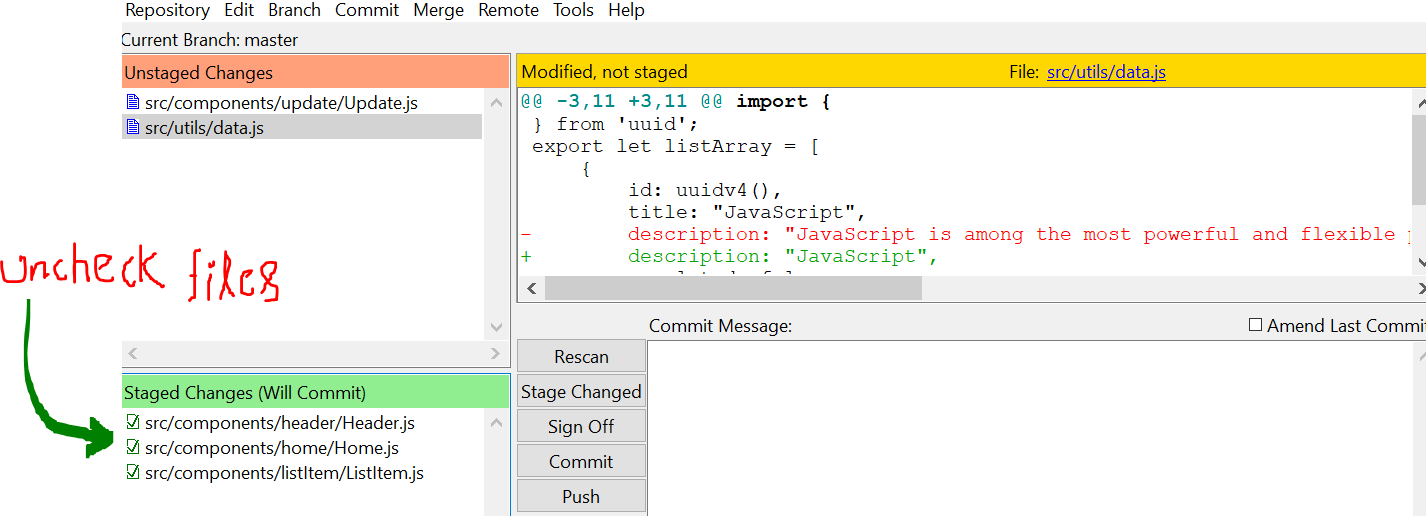
git restore --staged <file>... rather than the solution you are giving XD –
Myall Use git add -i to remove just-added files from your upcoming commit. Example:
Adding the file you didn't want:
$ git add foo
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: foo
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
# [...]#
Going into interactive add to undo your add (the commands typed at git here are "r" (revert), "1" (first entry in the list revert shows), 'return' to drop out of revert mode, and "q" (quit):
$ git add -i
staged unstaged path
1: +1/-0 nothing foo
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> r
staged unstaged path
1: +1/-0 nothing [f]oo
Revert>> 1
staged unstaged path
* 1: +1/-0 nothing [f]oo
Revert>>
note: foo is untracked now.
reverted one path
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> q
Bye.
$
That's it! Here's your proof, showing that "foo" is back on the untracked list:
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
# [...]
# foo
nothing added to commit but untracked files present (use "git add" to track)
$
Here's a way to avoid this vexing problem when you start a new project:
git init.Git makes it really hard to do git reset if you don't have any commits. If you create a tiny initial commit just for the sake of having one, after that you can git add -A and git reset as many times as you want in order to get everything right.
Another advantage of this method is that if you run into line-ending troubles later and need to refresh all your files, it's easy:
autocrlf value... This won't work in every project, depending the settings. –
Woodpecker git reset somefile and git reset both work prior to making the first commit, now. This has been the case since several Git releases back. –
Serotherapy Note that if you fail to specify a revision then you have to include a separator. Example from my console:
git reset <path_to_file>
fatal: ambiguous argument '<path_to_file>': unknown revision or path not in the working tree.
Use '--' to separate paths from revisions
git reset -- <path_to_file>
Unstaged changes after reset:
M <path_to_file>
(Git version 1.7.5.4)
git reset <path> and it works just fine without a separator. I'm also using git 1.9.0. Maybe it doesn't work in older versions? –
Henotheism Maybe Git has evolved since you posted your question.
$> git --version
git version 1.6.2.1
Now, you can try:
git reset HEAD .
This should be what you are looking for.
To remove new files from the staging area (and only in case of a new file), as suggested above:
git rm --cached FILE
Use rm --cached only for new files accidentally added.
--cached is a really important part here. –
Margerymarget To reset every file in a particular folder (and its subfolders), you can use the following command:
git reset *
git status to see anything remaining and reset it manually i.e. git reset file. –
Abominable Use the * command to handle multiple files at a time:
git reset HEAD *.prj
git reset HEAD *.bmp
git reset HEAD *gdb*
etc.
.* or .*.prj –
Agio * is not a command. It's a wildcard. –
Antre Just type git reset it will revert back and it is like you never typed git add . since your last commit. Make sure you have committed before.
Suppose I create a new file, newFile.txt:
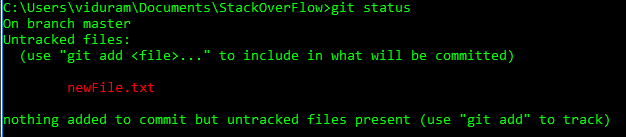
Suppose I add the file accidentally, git add newFile.txt:
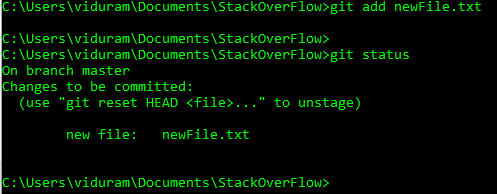
Now I want to undo this add, before commit, git reset newFile.txt:
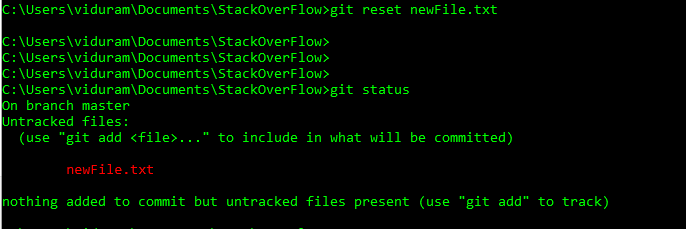
For a specific file:
- git reset my_file.txt
- git checkout my_file.txt
For all added files:
- git reset .
- git checkout .
Note: checkout changes the code in the files and moves to the last updated (committed) state. reset doesn't change the codes; it just resets the header.
git reset <file> and git checkout <file>. –
Adjectival To undo git add, use:
git reset filename
There is also interactive mode:
git add -i
Choose option 3 to un add files. In my case I often want to add more than one file, and with interactive mode you can use numbers like this to add files. This will take all but 4: 1, 2, 3, and 5
To choose a sequence, just type 1-5 to take all from 1 to 5.
git add myfile.txt # This will add your file into the to-be-committed list
Quite opposite to this command is,
git reset HEAD myfile.txt # This will undo it.
so, you will be in the previous state. Specified will be again in untracked list (previous state).
It will reset your head with that specified file. so, if your head doesn't have it means, it will simply reset it.
This command will unstash your changes:
git reset HEAD filename.txt
You can also use
git add -p
to add parts of files.
git reset filename.txt
Will remove a file named filename.txt from the current index, the "about to be committed" area, without changing anything else.
In Sourcetree you can do this easily via the GUI. You can check which command Sourcetree uses to unstage a file.
I created a new file and added it to Git. Then I unstaged it using the Sourcetree GUI. This is the result:
Unstaging files [08/12/15 10:43] git -c diff.mnemonicprefix=false -c core.quotepath=false -c credential.helper=sourcetree reset -q -- path/to/file/filename.java
Sourcetree uses reset to unstage new files.
If you want to revert the last commit but still want to keep the changes locally that were made in the commit, use this command:
git reset HEAD~1 --mixed
One of the most intuitive solutions is using Sourcetree.
You can just drag and drop files from staged and unstaged
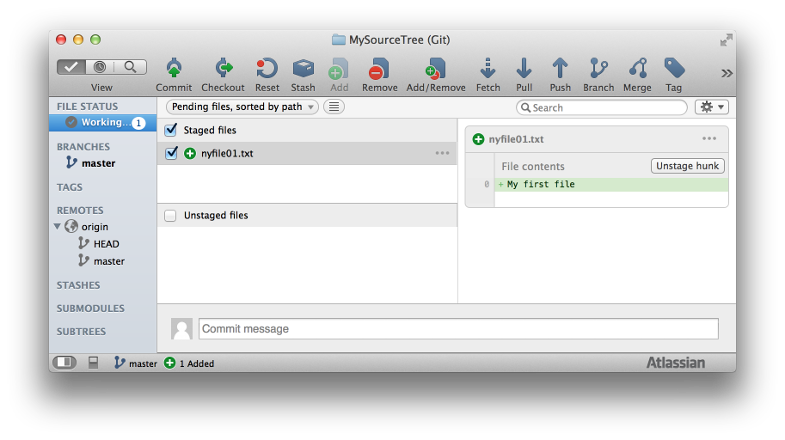
I would use git restore --staged . or git restore --staged <filename>
You can also use git rm --cached, however, the git rm command should be ideally used for already tracked files.
The first time I had this problem, I found this post here and from the first answer I learned that I should just do git reset <filename>. It worked fine.
Eventually, I happened to have a few subfolders inside my main git folder. I found it easy to just do git add . to add all files inside the subfolders and then git reset the few files that I did not want to add.
Nowadays I have lots of files and subfolders. It is tedious to git reset one-by-one but still easier to just git add . first, then reset the few heavy/unwanted but useful files and folders.
I've found the following method (which is not recorded here or here) relatively easy. I hope it will be helpful:
Let's say that you have the following situation:
Folder/SubFolder1/file1.txt
Folder/SubFolder2/fig1.png
Folder/SubFolderX/fig.svg
Folder/SubFolder3/<manyfiles>
Folder/SubFolder4/<file1.py, file2.py, ..., file60.py, ...>
You want to add all folders and files but not fig1.png, and not SubFolderX, and not file60.py and the list keeps growing ...
First, make/create a bash shell script and give it a name. Say, git_add.sh:
Then add all the paths to all folders and files you want to git reset preceded by git reset -- . You can easily copy-paste the paths into the script git_add.sh as your list of files grows. The git_add.sh script should look like this:
#!/bin/bash
git add .
git reset -- Folder/SubFolder2/fig1.png
git reset -- Folder/SubFolderX
git reset -- Folder/SubFolder4/file60.py
#!/bin/bash is important. Then do source git_add.sh to run it. After that, you can do git commit -m "some comment", and then git push -u origin master if you have already set up Bitbucket/Github.
Disclaimer: I've only tested this in Linux.
If you have lots of files and folders that you always retain in your local git repository but you don't want git to track changes when you do git add ., say video and data files, you must learn how to use .gitignore. Maybe from here.
source the file, it does not need to be executable. –
Genevieve .gitignore file to prevent the files and directories that should not be added from being added? –
Genevieve You can using this command after git version 2.23 :
git restore --staged <filename>
Or, you can using this command:
git reset HEAD <filename>
The git reset command helps you to modify either the staging area or the staging area and working tree. Git's ability to craft commits exactly like you want means that you sometimes need to undo changes to the changes you staged with git add.
You can do that by calling git reset HEAD <file to change>. You have two options to get rid of changes completely. git checkout HEAD <file(s) or path(s)> is a quick way to undo changes to your staging area and working tree.
Be careful with this command, however, because it removes all changes to your working tree. Git doesn't know about those changes since they've never been committed. There's no way to get those changes back once you run this command.
Another command at your disposal is git reset --hard. It is equally destructive to your working tree - any uncommitted changes or staged changes are lost after running it. Running git reset -hard HEAD does the same thing as git checkout HEAD. It just does not require a file or path to work.
You can use --soft with git reset. It resets the repository to the commit you specify and stages all of those changes. Any changes you have already staged are not affected, nor are the changes in your working tree.
Finally, you can use --mixed to reset the working tree without staging any changes. This also unstages any changes that are staged.
Adding new information. My git version is 2.32.1, and the recommended way of achieving this is now
git restore --staged <file>...
This is recommended via the output of
git status
© 2022 - 2024 — McMap. All rights reserved.
HEADorheadcan now use@in place ofHEADinstead. See this answer (last section) to learn why you can do that. – Henotheismgit reset <file_name>. For more info be sure to take a look at this article. – Griffeygit rm --cached <file>unstages and untracks (marked for removal on next commit) a given file, whilegit reset HEAD <file>just unstages the file – Chaffingit restore --staged .– Outstand