When is it recommended to use Git rebase vs. Git merge?
Do I still need to merge after a successful rebase?
When is it recommended to use Git rebase vs. Git merge?
Do I still need to merge after a successful rebase?
So when do you use either one?
Squashing: All commits are preserved in both cases (for example: "add feature", then "typo", then "oops typo again"...). Commits can be combined into a single commits by squashing. Squashing can be done as part of a merge or rebase operation (--squash flag), in which case it's often called a squash-merge or a squash-rebase.
Pull Requests: Popular git servers (Bitbucket, GitLab, GitHub, etc...) allow to configure how pull requests are merged on a per-repo basis. the UI may show a "Merge" button by convention but the button can do any operations with any flags (keywords: merge, rebase, squash, fast-forward).
init a new repo, add the file and commit. Checkout a new feature branch (checkout -b feature.) Change the text file, commit and repeat so that there are two new commits on the feature branch. Then checkout master and merge feature. In log, I see my initial commit on master, followed by the two that were merged from feature. If you merge --squash feature, feature is merged into master but not committed, so the only new commit on master will be the one you make yourself. –
If foo, added one commit on master and multiple commits on foo then git merge foo. If I view log it shows all of the commits from foo. It contradicts way you said "git will not include all of the individual commits from branch B if merged into M" ... –
Harwin --no-ff. –
Jame It's simple. With rebase you say to use another branch as the new base for your work.
If you have, for example, a branch master, you create a branch to implement a new feature, and say you name it cool-feature, of course, the master branch is the base for your new feature.
Now, at a certain point, you want to add the new feature you implemented in the master branch. You could just switch to master and merge the cool-feature branch:
$ git checkout master
$ git merge cool-feature
But this way a new dummy commit is added. If you want to avoid spaghetti-history you can rebase:
$ git checkout cool-feature
$ git rebase master
And then merge it in master:
$ git checkout master
$ git merge cool-feature
This time, since the topic branch has the same commits of master plus the commits with the new feature, the merge will be just a fast-forward.
but this way a new dummy commit is added, if you want to avoid spaghetti-history - how is it bad? –
Abbacy Sean Schofield puts it in a comment: "Rebase is also nice because once u do eventually merge ur stuff back into master (which is trivial as already described) you have it sitting at the "top" of ur commit history. On bigger projects where features may be written but merged several weeks later, you don't want to just merge them into the master because they get "stuffed" into the master way back in the history. Personally I like being able to do git log and see that recent feature right at the "top." Note the commit dates are preserved - rebase doesn't change that information. " –
Jermyn merge, rebase, fast-forward, etc.) are referring to specific manipulations of a directed acyclic graph. They become easier to reason about with that mental model in mind. –
Pelagi If you have any doubt, use merge.
The only differences between a rebase and a merge are:
So the short answer is to pick rebase or merge based on what you want your history to look like.
There are a few factors you should consider when choosing which operation to use.
If so, don't rebase. Rebase destroys the branch and those developers will have broken/inconsistent repositories unless they use git pull --rebase. This is a good way to upset other developers quickly.
Rebase is a destructive operation. That means, if you do not apply it correctly, you could lose committed work and/or break the consistency of other developer's repositories.
I've worked on teams where the developers all came from a time when companies could afford dedicated staff to deal with branching and merging. Those developers don't know much about Git and don't want to know much. In these teams I wouldn't risk recommending rebasing for any reason.
Some teams use the branch-per-feature model where each branch represents a feature (or bugfix, or sub-feature, etc.) In this model the branch helps identify sets of related commits. For example, one can quickly revert a feature by reverting the merge of that branch (to be fair, this is a rare operation). Or diff a feature by comparing two branches (more common). Rebase would destroy the branch and this would not be straightforward.
I've also worked on teams that used the branch-per-developer model (we've all been there). In this case the branch itself doesn't convey any additional information (the commit already has the author). There would be no harm in rebasing.
Reverting (as in undoing) a rebase is considerably difficult and/or impossible (if the rebase had conflicts) compared to reverting a merge. If you think there is a chance you will want to revert then use merge.
Rebase operations need to be pulled with a corresponding git pull --rebase. If you are working by yourself you may be able to remember which you should use at the appropriate time. If you are working on a team this will be very difficult to coordinate. This is why most rebase workflows recommend using rebase for all merges (and git pull --rebase for all pulls).
Assuming you have the following merge:
B -- C
/ \
A--------D
Some people will state that the merge "destroys" the commit history because if you were to look at the log of only the master branch (A -- D) you would miss the important commit messages contained in B and C.
If this were true we wouldn't have questions like this. Basically, you will see B and C unless you explicitly ask not to see them (using --first-parent). This is very easy to try for yourself.
The two approaches merge differently, but it is not clear that one is always better than the other and it may depend on the developer workflow. For example, if a developer tends to commit regularly (e.g. maybe they commit twice a day as they transition from work to home) then there could be a lot of commits for a given branch. Many of those commits might not look anything like the final product (I tend to refactor my approach once or twice per feature). If someone else was working on a related area of code and they tried to rebase my changes it could be a fairly tedious operation.
If you like to alias rm to rm -rf to "save time" then maybe rebase is for you.
I always think that someday I will come across a scenario where Git rebase is the awesome tool that solves the problem. Much like I think I will come across a scenario where Git reflog is an awesome tool that solves my problem. I have worked with Git for over five years now. It hasn't happened.
Messy histories have never really been a problem for me. I don't ever just read my commit history like an exciting novel. A majority of the time I need a history I am going to use Git blame or Git bisect anyway. In that case, having the merge commit is actually useful to me, because if the merge introduced the issue, that is meaningful information to me.
I feel obligated to mention that I have personally softened on using rebase although my general advice still stands. I have recently been interacting a lot with the Angular 2 Material project. They have used rebase to keep a very clean commit history. This has allowed me to very easily see what commit fixed a given defect and whether or not that commit was included in a release. It serves as a great example of using rebase correctly.
git pull behavior to include the --rebase flag by default. That means that doing rebases on branches used by multiple developers is a little less dangerous. A person pulling your changes might be surprised that there are some conflicts to be resolved during such an operation, but there would be no disaster. –
Thermosetting I just created an FAQ for my team in my own words which answers this question. Let me share:
merge?A commit, that combines all changes of a different branch into the current.
rebase?Re-comitting all commits of the current branch onto a different base commit.
merge and rebase?merge executes only one new commit. rebase typically executes multiple (number of commits in current branch).merge produces a new generated commit (the so called merge-commit). rebase only moves existing commits.merge?Use merge whenever you want to add changes of a branched out branch back into the base branch.
Typically, you do this by clicking the "Merge" button on Pull/Merge Requests, e.g. on GitHub.
rebase?Use rebase whenever you want to add changes of a base branch back to a branched out branch.
Typically, you do this in feature branches whenever there's a change in the main branch.
merge to merge changes from the base branch into a feature branch?The git history will include many unnecessary merge commits. If multiple merges were needed in a feature branch, then the feature branch might even hold more merge commits than actual commits!
This creates a loop which destroys the mental model that Git was designed by which causes troubles in any visualization of the Git history.
Imagine there's a river (e.g. the "Nile"). Water is flowing in one direction (direction of time in Git history). Now and then, imagine there's a branch to that river and suppose most of those branches merge back into the river. That's what the flow of a river might look like naturally. It makes sense.
But then imagine there's a small branch of that river. Then, for some reason, the river merges into the branch and the branch continues from there. The river has now technically disappeared, it's now in the branch. But then, somehow magically, that branch is merged back into the river. Which river you ask? I don't know. The river should actually be in the branch now, but somehow it still continues to exist and I can merge the branch back into the river. So, the river is in the river. Kind of doesn't make sense.
This is exactly what happens when you merge the base branch into a feature branch and then when the feature branch is done, you merge that back into the base branch again. The mental model is broken. And because of that, you end up with a branch visualization that's not very helpful.
merge: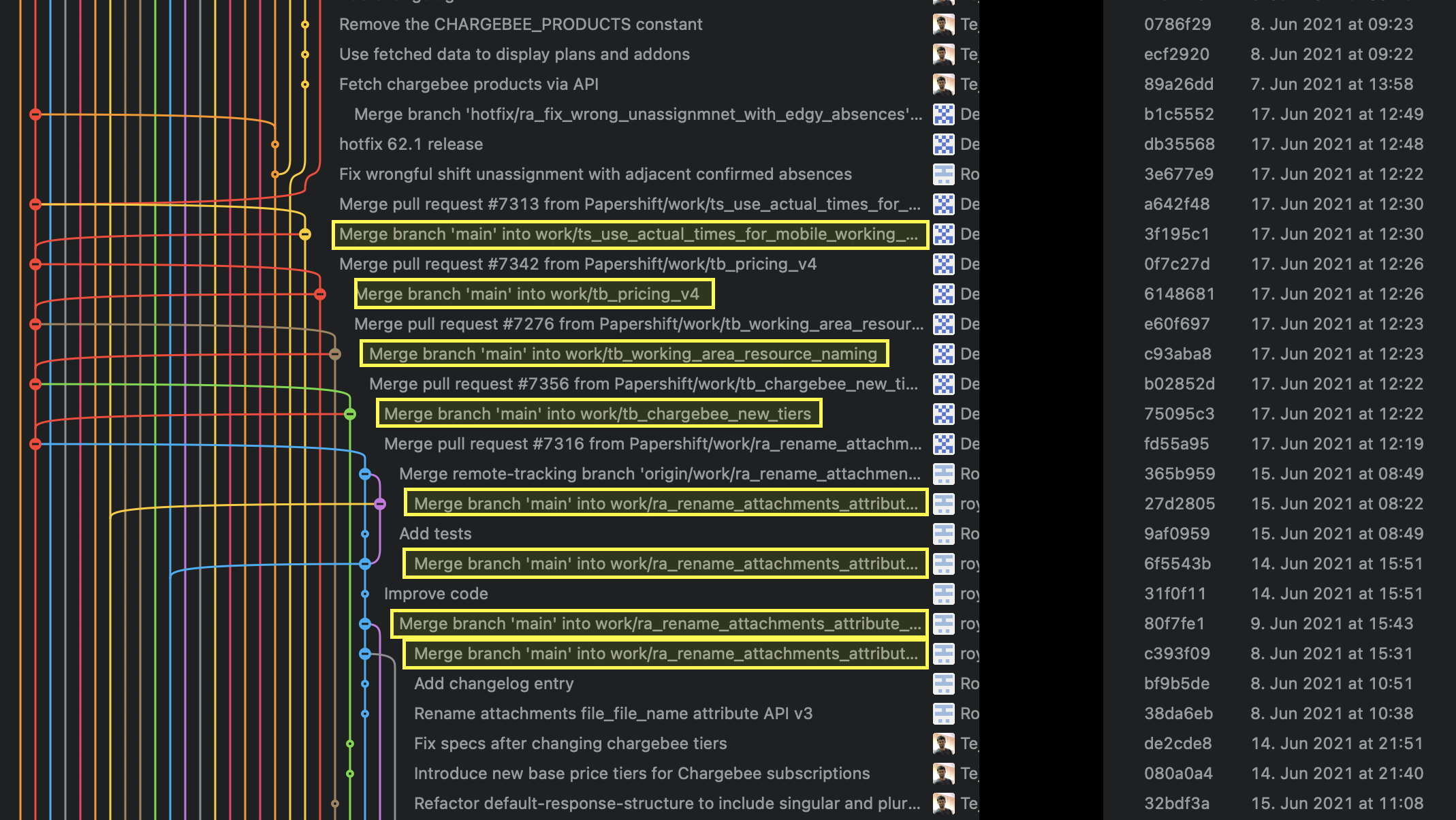
Note the many commits starting with Merge branch 'main' into .... They don't even exist if you rebase (there, you will only have pull request merge commits). Also many visual branch merge loops (main into feature into main).
rebase: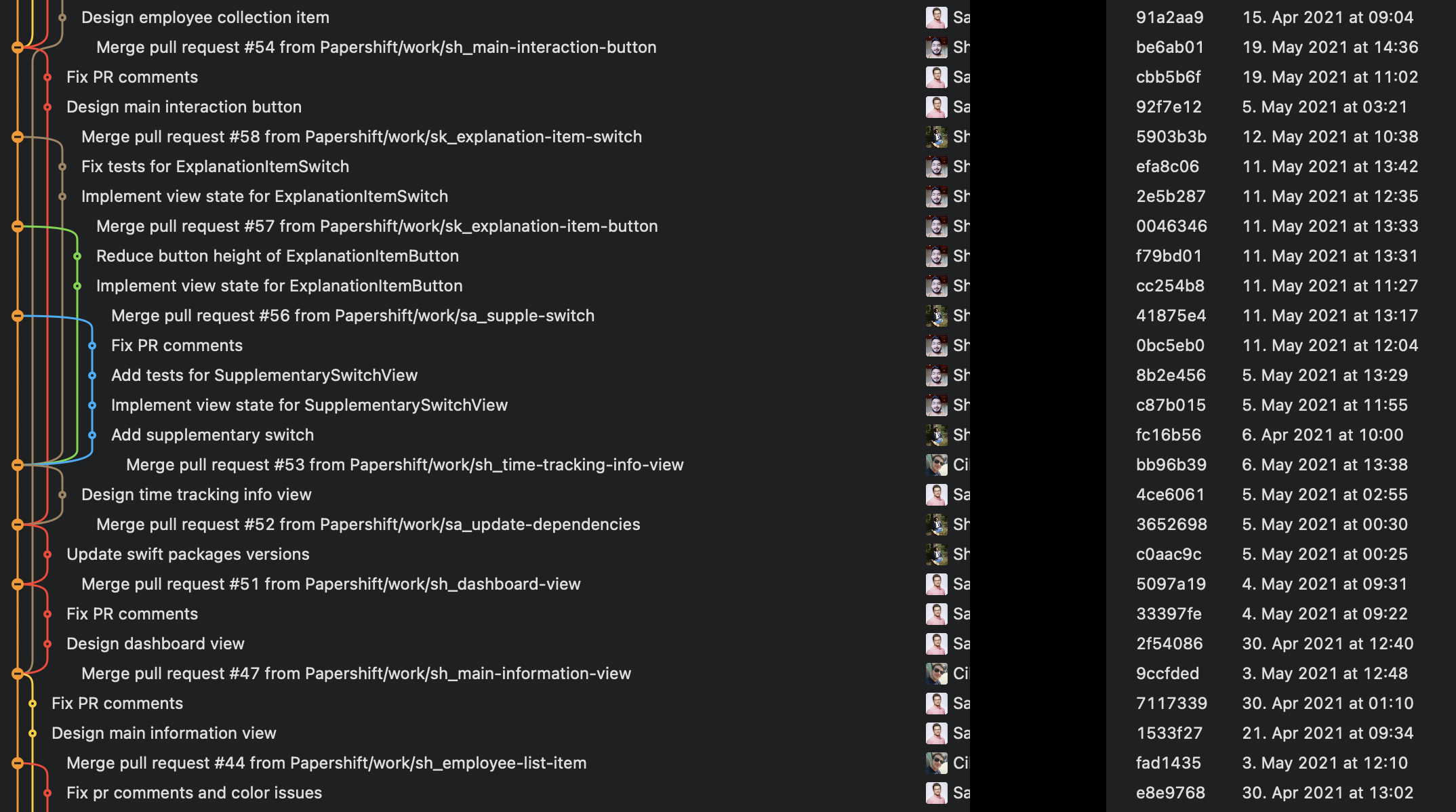
Much cleaner Git history with much less merge commits and no cluttered visual branch merge loops whatsoever.
rebase?Yes:
Because a rebase moves commits (technically re-executes them), the commit date of all moved commits will be the time of the rebase and the git history might look like it lost the initial commit time. So, if the exact date of a commit is needed in all tooling for some reason, then merge is the better option. But typically, a clean git history is much more useful than exact commit dates. And the author-date field will continue to hold the original commit date where needed.
If the rebased branch has multiple commits that change the same line and that line was also changed in the base branch, you might need to solve merge conflicts for that same line multiple times, which you never need to do when merging. So, on average, there's more merge conflicts to solve.
Note that there's a common misconception that a rebase causes more merge conflicts even if the same line was not edited multiple times. That's because multiple commits are executed and so for example 10 conflicts that would have come up in a single merge commit are distributed among these multiple commits. So you get the "there are merge conflicts" message of your Git client more often, but the total number of conflicts is still the same (unless you changed the same line multiple times in your branch).
rebase:To complement my own answer mentioned by TSamper,
a rebase is quite often a good idea to do before a merge, because the idea is that you integrate in your branch Y the work of the branch B upon which you will merge.
But again, before merging, you resolve any conflict in your branch (i.e.: "rebase", as in "replay my work in my branch starting from a recent point from the branch B).
If done correctly, the subsequent merge from your branch to branch B can be fast-forward.
a merge directly impacts the destination branch B, which means the merges better be trivial, otherwise that branch B can be long to get back to a stable state (time for you solve all the conflicts)
the point of merging after a rebase?
In the case that I describe, I rebase B onto my branch, just to have the opportunity to replay my work from a more recent point from B, but while staying into my branch.
In this case, a merge is still needed to bring my "replayed" work onto B.
The other scenario (described in Git Ready for instance), is to bring your work directly in B through a rebase (which does conserve all your nice commits, or even give you the opportunity to re-order them through an interactive rebase).
In that case (where you rebase while being in the B branch), you are right: no further merge is needed:
A Git tree at default when we have not merged nor rebased

we get by rebasing:

That second scenario is all about: how do I get new-feature back into master.
My point, by describing the first rebase scenario, is to remind everyone that a rebase can also be used as a preliminary step to that (that being "get new-feature back into master").
You can use rebase to first bring master "in" the new-feature branch: the rebase will replay new-feature commits from the HEAD master, but still in the new-feature branch, effectively moving your branch starting point from an old master commit to HEAD-master.
That allows you to resolve any conflicts in your branch (meaning, in isolation, while allowing master to continue to evolve in parallel if your conflict resolution stage takes too long).
Then you can switch to master and merge new-feature (or rebase new-feature onto master if you want to preserve commits done in your new-feature branch).
So:
master.git rebase man page details a possible solution in those rare instance. –
Pencel master) rather than merging master and potentially making some fixes to my feature branch before merging it back to master: the history is cleaner. –
Pencel A lot of answers here say that merging turns all your commits into one, and therefore suggest to use rebase to preserve your commits. This is incorrect. And a bad idea if you have pushed your commits already.
Merge does not obliterate your commits. Merge preserves history! (just look at gitk) Rebase rewrites history, which is a Bad Thing after you've pushed it.
Use merge -- not rebase whenever you've already pushed.
Here is Linus' (author of Git) take on it (now hosted on my own blog, as recovered by the Wayback Machine). It's a really good read.
Or you can read my own version of the same idea below.
Rebasing a branch on master:
In contrast, merging a topic branch into master:
master and dev. Nothing wrong with rebasing some random feature branch. Or, rebase locally and then push to a new feature branch which you then use to create the PR. –
Coprophagous TLDR: It depends on what is most important - a tidy history or a true representation of the sequence of development
If a tidy history is the most important, then you would rebase first and then merge your changes, so it is clear exactly what the new code is. If you have already pushed your branch, don't rebase unless you can deal with the consequences.
If true representation of sequence is the most important, you would merge without rebasing.
Merge means: Create a single new commit that merges my changes into the destination. Note: This new commit will have two parents - the latest commit from your string of commits and the latest commit of the other branch you're merging.
Rebase means: Create a whole new series of commits, using my current set of commits as hints. In other words, calculate what my changes would have looked like if I had started making them from the point I'm rebasing on to. After the rebase, therefore, you might need to re-test your changes and during the rebase, you would possibly have a few conflicts.
Given this, why would you rebase? Just to keep the development history clear. Let's say you're working on feature X and when you're done, you merge your changes in. The destination will now have a single commit that would say something along the lines of "Added feature X". Now, instead of merging, if you rebased and then merged, the destination development history would contain all the individual commits in a single logical progression. This makes reviewing changes later on much easier. Imagine how hard you'd find it to review the development history if 50 developers were merging various features all the time.
That said, if you have already pushed the branch you're working on upstream, you should not rebase, but merge instead. For branches that have not been pushed upstream, rebase, test and merge.
Another time you might want to rebase is when you want to get rid of commits from your branch before pushing upstream. For example: Commits that introduce some debugging code early on and other commits further on that clean that code up. The only way to do this is by performing an interactive rebase: git rebase -i <branch/commit/tag>
UPDATE: You also want to use rebase when you're using Git to interface to a version control system that doesn't support non-linear history (Subversion for example). When using the git-svn bridge, it is very important that the changes you merge back into Subversion are a sequential list of changes on top of the most recent changes in trunk. There are only two ways to do that: (1) Manually re-create the changes and (2) Using the rebase command, which is a lot faster.
UPDATE 2: One additional way to think of a rebase is that it enables a sort of mapping from your development style to the style accepted in the repository you're committing to. Let's say you like to commit in small, tiny chunks. You have one commit to fix a typo, one commit to get rid of unused code and so on. By the time you've finished what you need to do, you have a long series of commits. Now let's say the repository you're committing to encourages large commits, so for the work you're doing, one would expect one or maybe two commits. How do you take your string of commits and compress them to what is expected? You would use an interactive rebase and squash your tiny commits into fewer larger chunks. The same is true if the reverse was needed - if your style was a few large commits, but the repository demanded long strings of small commits. You would use a rebase to do that as well. If you had merged instead, you have now grafted your commit style onto the main repository. If there are a lot of developers, you can imagine how hard it would be to follow a history with several different commit styles after some time.
UPDATE 3: Does one still need to merge after a successful rebase? Yes, you do. The reason is that a rebase essentially involves a "shifting" of commits. As I've said above, these commits are calculated, but if you had 14 commits from the point of branching, then assuming nothing goes wrong with your rebase, you will be 14 commits ahead (of the point you're rebasing onto) after the rebase is done. You had a branch before a rebase. You will have a branch of the same length after. You still need to merge before you publish your changes. In other words, rebase as many times as you want (again, only if you have not pushed your changes upstream). Merge only after you rebase.
git merge supports the --no-ff option which forces it to make a merge commit. –
Football While merging is definitely the easiest and most common way to integrate changes, it's not the only one: Rebase is an alternative means of integration.
Understanding Merge a Little Better
When Git performs a merge, it looks for three commits:
Fast-Forward or Merge Commit
In very simple cases, one of the two branches doesn't have any new commits since the branching happened - its latest commit is still the common ancestor.
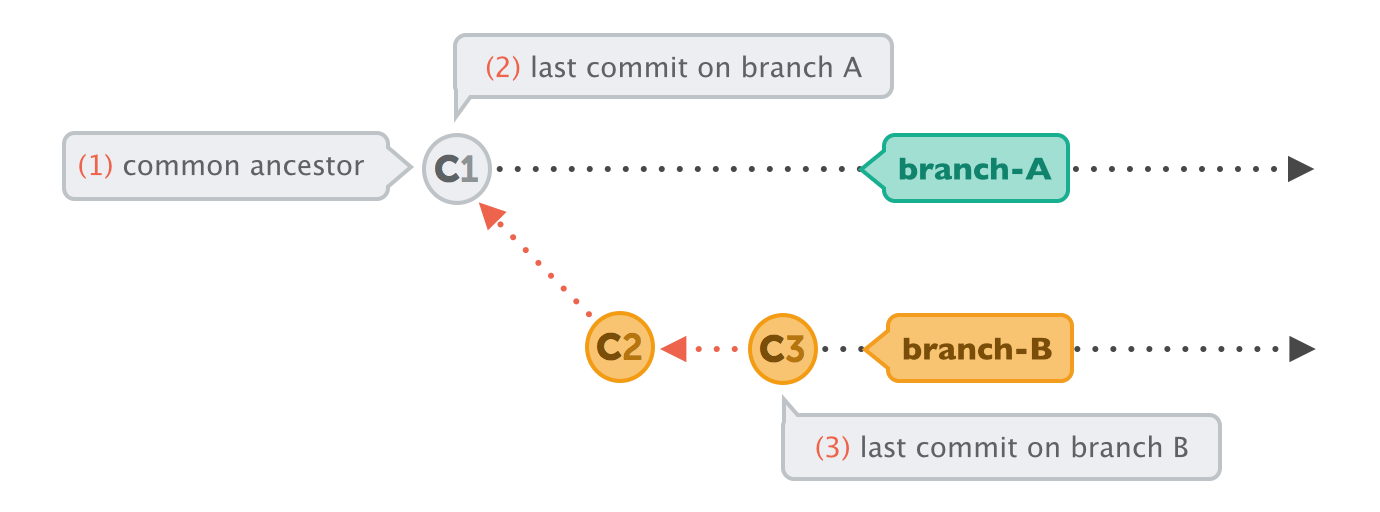
In this case, performing the integration is dead simple: Git can just add all the commits of the other branch on top of the common ancestor commit. In Git, this simplest form of integration is called a "fast-forward" merge. Both branches then share the exact same history.

In a lot of cases, however, both branches moved forward individually.
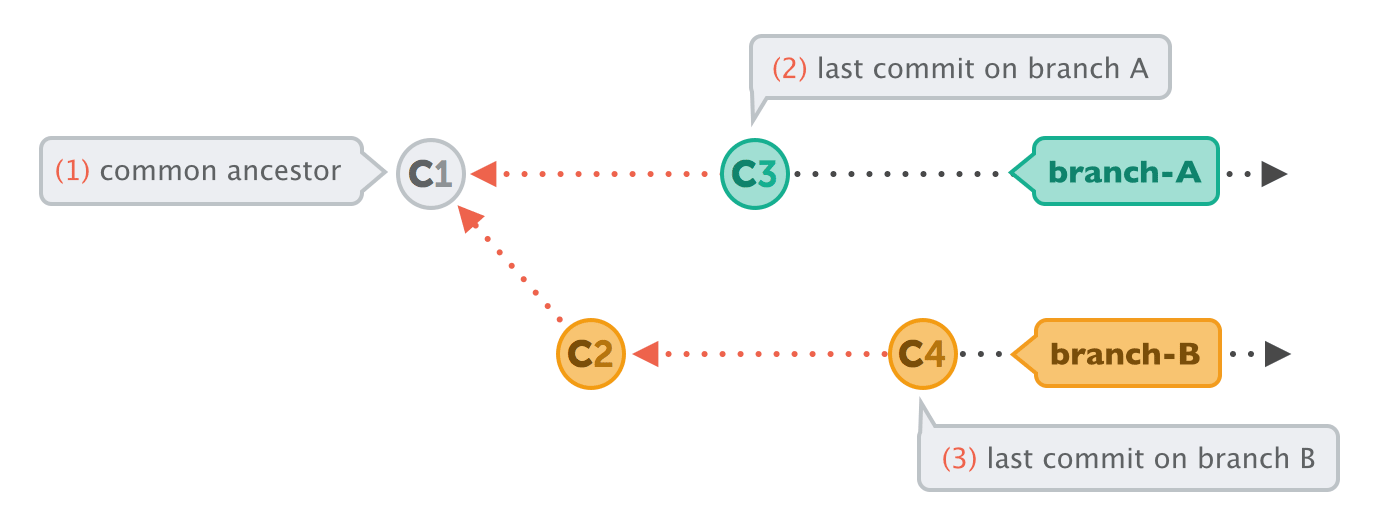
To make an integration, Git will have to create a new commit that contains the differences between them - the merge commit.
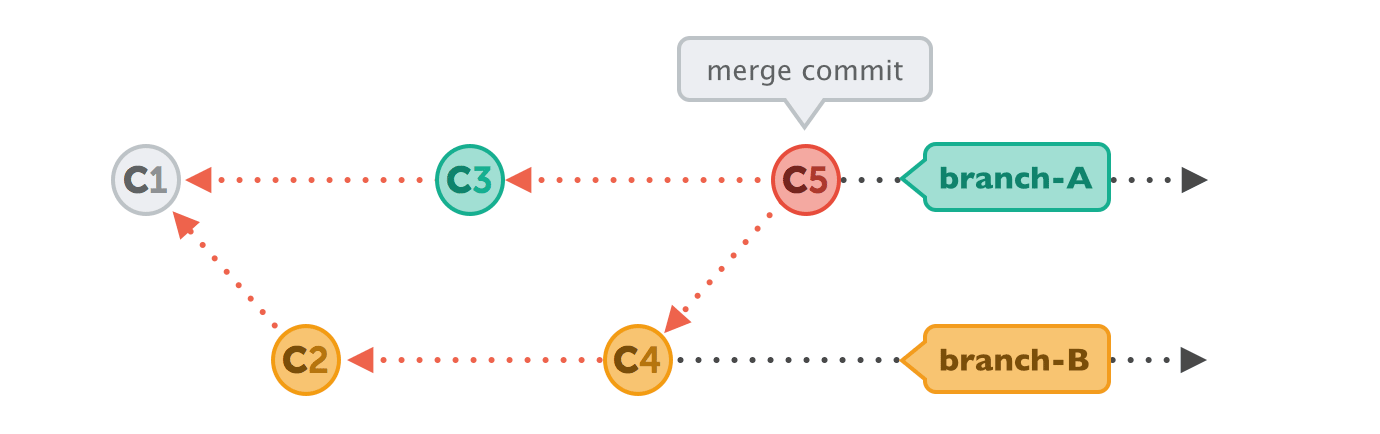
Human Commits & Merge Commits
Normally, a commit is carefully created by a human being. It's a meaningful unit that wraps only related changes and annotates them with a comment.
A merge commit is a bit different: instead of being created by a developer, it gets created automatically by Git. And instead of wrapping a set of related changes, its purpose is to connect two branches, just like a knot. If you want to understand a merge operation later, you need to take a look at the history of both branches and the corresponding commit graph.
Integrating with Rebase
Some people prefer to go without such automatic merge commits. Instead, they want the project's history to look as if it had evolved in a single, straight line. No indication remains that it had been split into multiple branches at some point.
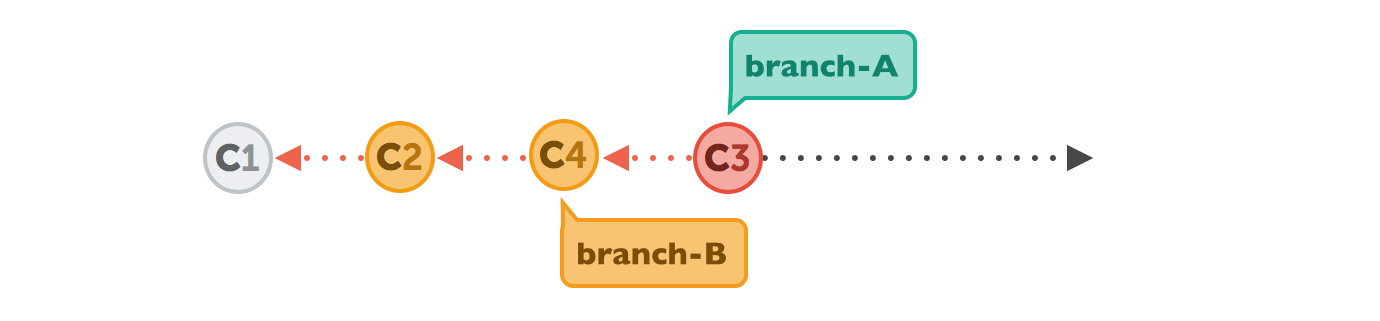
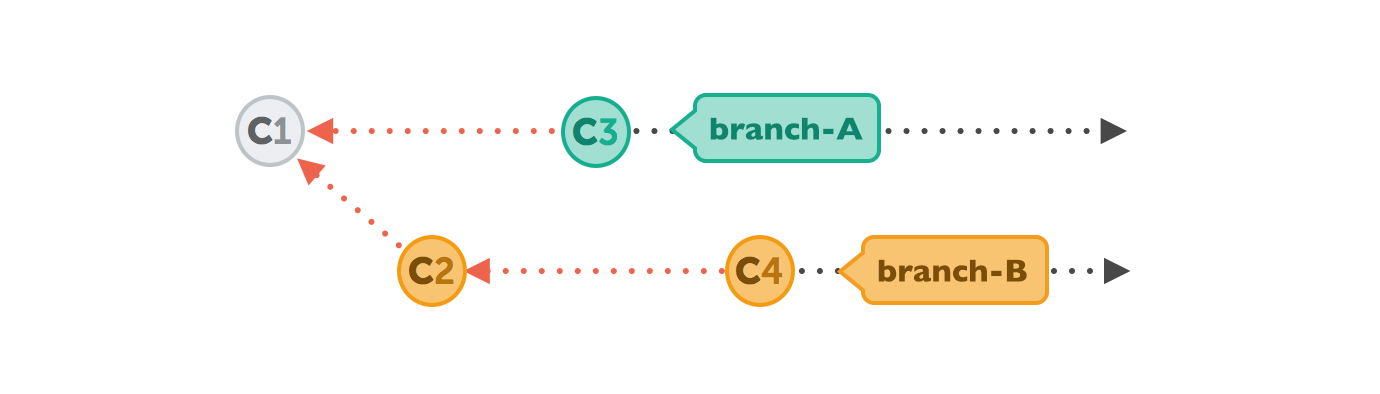
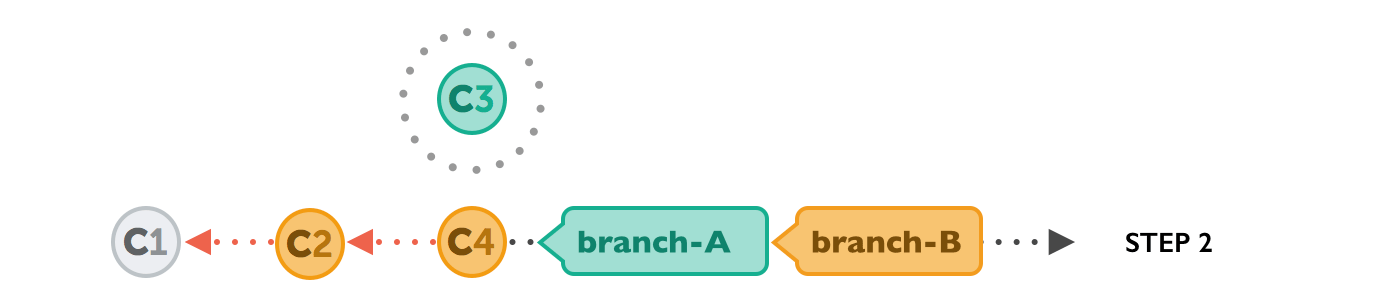
Let's walk through a rebase operation step by step. The scenario is the same as in the previous examples: we want to integrate the changes from branch-B into branch-A, but now by using rebase.
We will do this in three steps
git rebase branch-A // Synchronises the history with branch-Agit checkout branch-A // Change the current branch to branch-Agit merge branch-B // Merge/take the changes from branch-B to branch-AFirst, Git will "undo" all commits on branch-A that happened after the lines began to branch out (after the common ancestor commit). However, of course, it won't discard them: instead you can think of those commits as being "saved away temporarily".
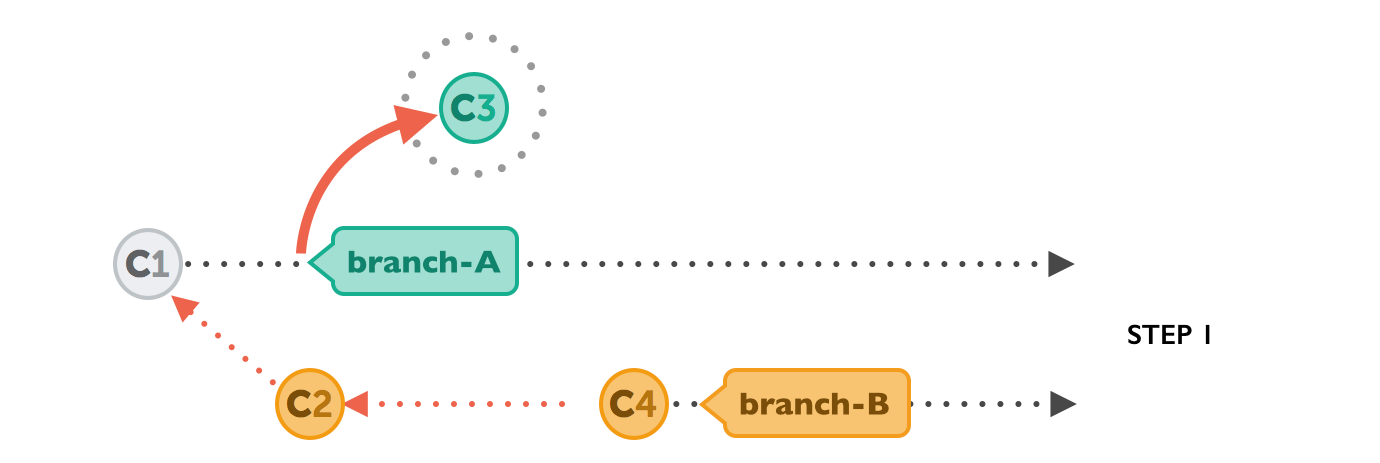
Next, it applies the commits from branch-B that we want to integrate. At this point, both branches look exactly the same.
In the final step, the new commits on branch-A are now reapplied - but on a new position, on top of the integrated commits from branch-B (they are re-based).
The result looks like development had happened in a straight line. Instead of a merge commit that contains all the combined changes, the original commit structure was preserved.
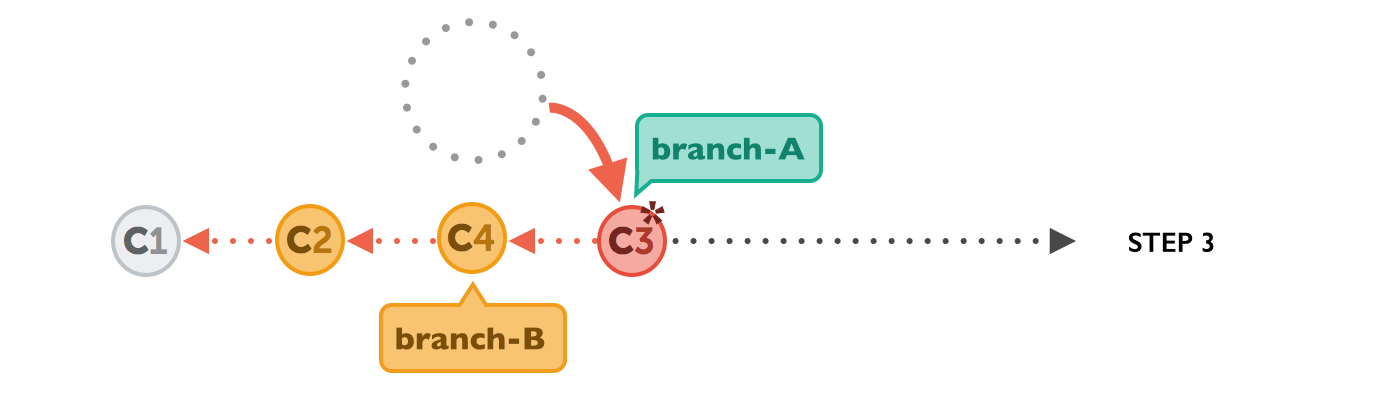
Finally, you get a clean branch branch-A with no unwanted and auto generated commits.
Note: Taken from the awesome post by git-tower. The disadvantages of rebase is also a good read in the same post.
Before merge/rebase:
A <- B <- C [master]
^
\
D <- E [branch]
After git merge master:
A <- B <- C
^ ^
\ \
D <- E <- F
After git rebase master:
A <- B <- C <- D' <- E'
(A, B, C, D, E and F are commits)
This example and much more well illustrated information about Git can be found in Git The Basics Tutorial.
This answer is widely oriented around Git Flow. The tables have been generated with the nice ASCII Table Generator, and the history trees with this wonderful command (aliased as git lg):
git log --graph --abbrev-commit --decorate --date=format:'%Y-%m-%d %H:%M:%S' --format=format:'%C(bold blue)%h%C(reset) - %C(bold cyan)%ad%C(reset) %C(bold green)(%ar)%C(reset)%C(bold yellow)%d%C(reset)%n'' %C(white)%s%C(reset) %C(dim white)- %an%C(reset)'
Tables are in reverse chronological order to be more consistent with the history trees. See also the difference between git merge and git merge --no-ff first (you usually want to use git merge --no-ff as it makes your history look closer to the reality):
git mergeCommands:
Time Branch "develop" Branch "features/foo"
------- ------------------------------ -------------------------------
15:04 git merge features/foo
15:03 git commit -m "Third commit"
15:02 git commit -m "Second commit"
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* 142a74a - YYYY-MM-DD 15:03:00 (XX minutes ago) (HEAD -> develop, features/foo)
| Third commit - Christophe
* 00d848c - YYYY-MM-DD 15:02:00 (XX minutes ago)
| Second commit - Christophe
* 298e9c5 - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git merge --no-ffCommands:
Time Branch "develop" Branch "features/foo"
------- -------------------------------- -------------------------------
15:04 git merge --no-ff features/foo
15:03 git commit -m "Third commit"
15:02 git commit -m "Second commit"
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* 1140d8c - YYYY-MM-DD 15:04:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/foo' - Christophe
| * 69f4a7a - YYYY-MM-DD 15:03:00 (XX minutes ago) (features/foo)
| | Third commit - Christophe
| * 2973183 - YYYY-MM-DD 15:02:00 (XX minutes ago)
|/ Second commit - Christophe
* c173472 - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git merge vs git rebaseFirst point: always merge features into develop, never rebase develop from features. This is a consequence of the Golden Rule of Rebasing:
The golden rule of
git rebaseis to never use it on public branches.
Never rebase anything you've pushed somewhere.
I would personally add: unless it's a feature branch AND you and your team are aware of the consequences.
So the question of git merge vs git rebase applies almost only to the feature branches (in the following examples, --no-ff has always been used when merging). Note that since I'm not sure there's one better solution (a debate exists), I'll only provide how both commands behave. In my case, I prefer using git rebase as it produces a nicer history tree :)
git mergeCommands:
Time Branch "develop" Branch "features/foo" Branch "features/bar"
------- -------------------------------- ------------------------------- --------------------------------
15:10 git merge --no-ff features/bar
15:09 git merge --no-ff features/foo
15:08 git commit -m "Sixth commit"
15:07 git merge --no-ff features/foo
15:06 git commit -m "Fifth commit"
15:05 git commit -m "Fourth commit"
15:04 git commit -m "Third commit"
15:03 git commit -m "Second commit"
15:02 git checkout -b features/bar
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* c0a3b89 - YYYY-MM-DD 15:10:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/bar' - Christophe
| * 37e933e - YYYY-MM-DD 15:08:00 (XX minutes ago) (features/bar)
| | Sixth commit - Christophe
| * eb5e657 - YYYY-MM-DD 15:07:00 (XX minutes ago)
| |\ Merge branch 'features/foo' into features/bar - Christophe
| * | 2e4086f - YYYY-MM-DD 15:06:00 (XX minutes ago)
| | | Fifth commit - Christophe
| * | 31e3a60 - YYYY-MM-DD 15:05:00 (XX minutes ago)
| | | Fourth commit - Christophe
* | | 98b439f - YYYY-MM-DD 15:09:00 (XX minutes ago)
|\ \ \ Merge branch 'features/foo' - Christophe
| |/ /
|/| /
| |/
| * 6579c9c - YYYY-MM-DD 15:04:00 (XX minutes ago) (features/foo)
| | Third commit - Christophe
| * 3f41d96 - YYYY-MM-DD 15:03:00 (XX minutes ago)
|/ Second commit - Christophe
* 14edc68 - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git rebaseCommands:
Time Branch "develop" Branch "features/foo" Branch "features/bar"
------- -------------------------------- ------------------------------- -------------------------------
15:10 git merge --no-ff features/bar
15:09 git merge --no-ff features/foo
15:08 git commit -m "Sixth commit"
15:07 git rebase features/foo
15:06 git commit -m "Fifth commit"
15:05 git commit -m "Fourth commit"
15:04 git commit -m "Third commit"
15:03 git commit -m "Second commit"
15:02 git checkout -b features/bar
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* 7a99663 - YYYY-MM-DD 15:10:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/bar' - Christophe
| * 708347a - YYYY-MM-DD 15:08:00 (XX minutes ago) (features/bar)
| | Sixth commit - Christophe
| * 949ae73 - YYYY-MM-DD 15:06:00 (XX minutes ago)
| | Fifth commit - Christophe
| * 108b4c7 - YYYY-MM-DD 15:05:00 (XX minutes ago)
| | Fourth commit - Christophe
* | 189de99 - YYYY-MM-DD 15:09:00 (XX minutes ago)
|\ \ Merge branch 'features/foo' - Christophe
| |/
| * 26835a0 - YYYY-MM-DD 15:04:00 (XX minutes ago) (features/foo)
| | Third commit - Christophe
| * a61dd08 - YYYY-MM-DD 15:03:00 (XX minutes ago)
|/ Second commit - Christophe
* ae6f5fc - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
develop to a feature branchgit mergeCommands:
Time Branch "develop" Branch "features/foo" Branch "features/bar"
------- -------------------------------- ------------------------------- -------------------------------
15:10 git merge --no-ff features/bar
15:09 git commit -m "Sixth commit"
15:08 git merge --no-ff develop
15:07 git merge --no-ff features/foo
15:06 git commit -m "Fifth commit"
15:05 git commit -m "Fourth commit"
15:04 git commit -m "Third commit"
15:03 git commit -m "Second commit"
15:02 git checkout -b features/bar
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* 9e6311a - YYYY-MM-DD 15:10:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/bar' - Christophe
| * 3ce9128 - YYYY-MM-DD 15:09:00 (XX minutes ago) (features/bar)
| | Sixth commit - Christophe
| * d0cd244 - YYYY-MM-DD 15:08:00 (XX minutes ago)
| |\ Merge branch 'develop' into features/bar - Christophe
| |/
|/|
* | 5bd5f70 - YYYY-MM-DD 15:07:00 (XX minutes ago)
|\ \ Merge branch 'features/foo' - Christophe
| * | 4ef3853 - YYYY-MM-DD 15:04:00 (XX minutes ago) (features/foo)
| | | Third commit - Christophe
| * | 3227253 - YYYY-MM-DD 15:03:00 (XX minutes ago)
|/ / Second commit - Christophe
| * b5543a2 - YYYY-MM-DD 15:06:00 (XX minutes ago)
| | Fifth commit - Christophe
| * 5e84b79 - YYYY-MM-DD 15:05:00 (XX minutes ago)
|/ Fourth commit - Christophe
* 2da6d8d - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git rebaseCommands:
Time Branch "develop" Branch "features/foo" Branch "features/bar"
------- -------------------------------- ------------------------------- -------------------------------
15:10 git merge --no-ff features/bar
15:09 git commit -m "Sixth commit"
15:08 git rebase develop
15:07 git merge --no-ff features/foo
15:06 git commit -m "Fifth commit"
15:05 git commit -m "Fourth commit"
15:04 git commit -m "Third commit"
15:03 git commit -m "Second commit"
15:02 git checkout -b features/bar
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* b0f6752 - YYYY-MM-DD 15:10:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/bar' - Christophe
| * 621ad5b - YYYY-MM-DD 15:09:00 (XX minutes ago) (features/bar)
| | Sixth commit - Christophe
| * 9cb1a16 - YYYY-MM-DD 15:06:00 (XX minutes ago)
| | Fifth commit - Christophe
| * b8ddd19 - YYYY-MM-DD 15:05:00 (XX minutes ago)
|/ Fourth commit - Christophe
* 856433e - YYYY-MM-DD 15:07:00 (XX minutes ago)
|\ Merge branch 'features/foo' - Christophe
| * 694ac81 - YYYY-MM-DD 15:04:00 (XX minutes ago) (features/foo)
| | Third commit - Christophe
| * 5fd94d3 - YYYY-MM-DD 15:03:00 (XX minutes ago)
|/ Second commit - Christophe
* d01d589 - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git cherry-pickWhen you just need one specific commit, git cherry-pick is a nice solution (the -x option appends a line that says "(cherry picked from commit...)" to the original commit message body, so it's usually a good idea to use it - git log <commit_sha1> to see it):
Commands:
Time Branch "develop" Branch "features/foo" Branch "features/bar"
------- -------------------------------- ------------------------------- -----------------------------------------
15:10 git merge --no-ff features/bar
15:09 git merge --no-ff features/foo
15:08 git commit -m "Sixth commit"
15:07 git cherry-pick -x <second_commit_sha1>
15:06 git commit -m "Fifth commit"
15:05 git commit -m "Fourth commit"
15:04 git commit -m "Third commit"
15:03 git commit -m "Second commit"
15:02 git checkout -b features/bar
15:01 git checkout -b features/foo
15:00 git commit -m "First commit"
Result:
* 50839cd - YYYY-MM-DD 15:10:00 (XX minutes ago) (HEAD -> develop)
|\ Merge branch 'features/bar' - Christophe
| * 0cda99f - YYYY-MM-DD 15:08:00 (XX minutes ago) (features/bar)
| | Sixth commit - Christophe
| * f7d6c47 - YYYY-MM-DD 15:03:00 (XX minutes ago)
| | Second commit - Christophe
| * dd7d05a - YYYY-MM-DD 15:06:00 (XX minutes ago)
| | Fifth commit - Christophe
| * d0d759b - YYYY-MM-DD 15:05:00 (XX minutes ago)
| | Fourth commit - Christophe
* | 1a397c5 - YYYY-MM-DD 15:09:00 (XX minutes ago)
|\ \ Merge branch 'features/foo' - Christophe
| |/
|/|
| * 0600a72 - YYYY-MM-DD 15:04:00 (XX minutes ago) (features/foo)
| | Third commit - Christophe
| * f4c127a - YYYY-MM-DD 15:03:00 (XX minutes ago)
|/ Second commit - Christophe
* 0cf894c - YYYY-MM-DD 15:00:00 (XX minutes ago)
First commit - Christophe
git pull --rebaseI am not sure I can explain it better than Derek Gourlay... Basically, use git pull --rebase instead of git pull :) What's missing in the article though, is that you can enable it by default:
git config --global pull.rebase true
git rerereAgain, nicely explained here. But put simply, if you enable it, you won't have to resolve the same conflict multiple times anymore.
This sentence gets it:
In general, the way to get the best of both worlds is to rebase local changes you’ve made, but haven’t shared yet, before you push them in order to clean up your story, but never rebase anything you’ve pushed somewhere.
The Pro Git book has a really good explanation on the rebasing page.
Basically a merge will take two commit trees and combine them.
A rebase will go to the common ancestor of the two commits and incrementally apply the changes on top of each other. This makes for a 'cleaner' and more linear history.
But when you rebase, you abandon previous commits and create new ones. So you should never rebase a repository that is public. The other people working on the repository will hate you.
For that reason alone I almost exclusively merge. 99% of the time my branches don’t differ that much, so if there are conflicts it's only in one or two places.
Git Merge vs Rebase
Both of them solve the same problem - concatenate branches. Rebase is more advanced technic which solves the main problem of Merge - spaghetti history. Project history becomes cleaner(linear and without extra merge commit) with Rebase. Bigger possibility generates bigger responsibility:
Merge workflow
1. create a new local branch - feature from origin/main
2. development
3. merge origin/main into local feature
4. resolve conflicts
5. push local feature into origin/feature
6. create merge request and merging(Create a merge commit)
7. remove local and remote feature branch


decf562 - 3. merge origin/main into local feature
196556f - 6. create merge request and merging
One more example where merge request creates a merge commit:
- rebase local feature2 branch
- you don't have conflicts. If you have some conflicts you can use merge request(Create a merge commit) instead
- create merge request and rebasing(Rebase and merge)



Rebase workflow
1. create a new local branch - feature from origin/main
2. development
3. rebase feature branch onto(on top of) origin/main branch. It means that you checkout feature and make rebase origin/main
4. resolve conflicts
5. push local feature into origin/feature
6. create merge request and rebasing(Rebase and merge)
7. remove local and remote feature branch



One more example where merge request creates a merge commit:
- rebase local feature2 branch
- resolve conflicts
- create merge request and merging(Create a merge commit)



Thanks
rebase. –
Monoceros Git rebase is used to make the branching paths in history cleaner and repository structure linear.
It is also used to keep the branches created by you private, as after rebasing and pushing the changes to the server, if you delete your branch, there will be no evidence of branch you have worked on. So your branch is now your local concern.
After doing rebase we also get rid of an extra commit which we used to see if we do a normal merge.
And yes, one still needs to do merge after a successful rebase as the rebase command just puts your work on top of the branch you mentioned during rebase, say master, and makes the first commit of your branch as a direct descendant of the master branch. This means we can now do a fast forward merge to bring changes from this branch to the master branch.
Some practical examples, somewhat connected to large scale development where Gerrit is used for review and delivery integration:
I merge when I uplift my feature branch to a fresh remote master. This gives minimal uplift work and it's easy to follow the history of the feature development in for example gitk.
git fetch
git checkout origin/my_feature
git merge origin/master
git commit
git push origin HEAD:refs/for/my_feature
I merge when I prepare a delivery commit.
git fetch
git checkout origin/master
git merge --squash origin/my_feature
git commit
git push origin HEAD:refs/for/master
I rebase when my delivery commit fails integration for whatever reason, and I need to update it towards a fresh remote master.
git fetch
git fetch <gerrit link>
git checkout FETCH_HEAD
git rebase origin/master
git push origin HEAD:refs/for/master
When do I use git rebase? Almost never, because it rewrites history. git merge is almost always the preferable choice, because it respects what actually happened in your project.
Rebase is useful when you are working on a branch and have merged some other work in between - the merges will create changes which will make your diff polluted and thus harder to read.
If you rebase your branch, then your commits will be applied on top of the branch you are rebasing to, which makes it easier to review and the diff output is cleaner.
Infographics always help :)
Assume the following history exists and the current branch is "master":
A---B---C topic
/
D---E---F---G master
Then "git merge topic" will replay the changes made on the topic branch since it
diverged from master (i.e., E) until its current commit (C) on top of master, and
record the result in a new commit along with the names of the two parent commits
and a log message from the user describing the changes.
A---B---C topic
/ \
D---E---F---G---H master
Assume the following history exists and the current branch is "topic":
A---B---C topic
/
D---E---F---G master
From this point, the result of either of the following commands:
git rebase master
git rebase master topic
would be:
A'--B'--C' topic
/
D---E---F---G master
NOTE: The latter form is just a short-hand of git checkout topic followed by git
rebase master. When rebase exits topic will remain the checked-out branch.
So we can basically conclude that merging is a safe option that preserves the entire history of your repository, while rebasing creates a linear history by moving your feature branch onto the tip of main.
Credit: help page git merge --help and git rebase --help
git merge --no-ff to see after release branch merged, who wrote this line. It allows me to revert the whole feature with 1 commit.git rebase with squashing to have clear small git commits history. In case of conflicts, after resolving, I use git push --force-with-leaseLet's say you create a new "new_feature" branch. Then, someone else merged their code to the main before you. so you want that updated main branch in your codebase because you do not want to diverge from the master branch for a super long time without getting those new changes. as you make more work on your branch, someone else or even more than 5 different engineers merged their code. then you need to get those commits onto your "new_feature" branch. and then you merge again. Imagine you had a feature that would take a week but other engineers had small tasks so they keep merging their code. you might end up having dozens of merge commits that do not add anything to your code. finally, when you finish your task and merged your work onto the "main", you will have a bunch of non-informative merge commits as part of the history. this is what rebase solves.
If we rebased instead of merging, we rewrite the history, we are creating new commits based upon the original "new_feature" branch commits. as the name says we are setting up a new base for our "new_feature" branch. you will not have "merge commits" anymore. whatever branch you are working on will contain all of the commits from the master and from your feature. With "rebase" we get a much cleaner project. this makes it easier for someone to review your commits. In open source projects, there are thousands of contributors and maybe millions of work all the time, using rebase will make it easier to read the history of features.
Because rebase rewrite the commits, you do not want to rebase commits that other people already have. Imagine you pushed up some branch to Github and your coworkers have that work in their machine, so all the commits, if all of a sudden you rebase those commits, you will end up having some commits that they do not have or they will have some commits that you do not have.
you should rebase the commits that you have on your machine and other people do not have.
© 2022 - 2024 — McMap. All rights reserved.