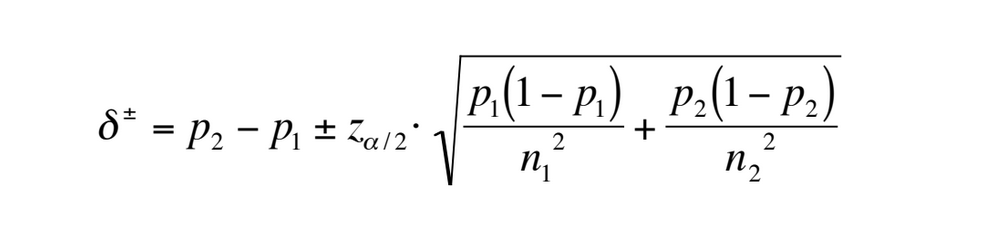I couldn't find a function for this from Statsmodels. However, this website goes over the maths for generating the confidence interval as well as being the source of the below function:
def two_proprotions_confint(success_a, size_a, success_b, size_b, significance = 0.05):
"""
A/B test for two proportions;
given a success a trial size of group A and B compute
its confidence interval;
resulting confidence interval matches R's prop.test function
Parameters
----------
success_a, success_b : int
Number of successes in each group
size_a, size_b : int
Size, or number of observations in each group
significance : float, default 0.05
Often denoted as alpha. Governs the chance of a false positive.
A significance level of 0.05 means that there is a 5% chance of
a false positive. In other words, our confidence level is
1 - 0.05 = 0.95
Returns
-------
prop_diff : float
Difference between the two proportion
confint : 1d ndarray
Confidence interval of the two proportion test
"""
prop_a = success_a / size_a
prop_b = success_b / size_b
var = prop_a * (1 - prop_a) / size_a + prop_b * (1 - prop_b) / size_b
se = np.sqrt(var)
# z critical value
confidence = 1 - significance
z = stats.norm(loc = 0, scale = 1).ppf(confidence + significance / 2)
# standard formula for the confidence interval
# point-estimtate +- z * standard-error
prop_diff = prop_b - prop_a
confint = prop_diff + np.array([-1, 1]) * z * se
return prop_diff, confint