1 Context
Noting the relational-database tag.
First we need to understand the whole context in which this problem exists, which includes the various available methods; the capabilities of each; and the limitations (if any). Following that, it is easy to understand the solution. And there is just one correct solution in the Relational paradigm.
1.1 Pre-Relational
There were perfectly good DBMS for 20 years before the Codd produced his Relational Model (1970). Further, it took more than 10 years for the vendors to produce genuine RDBMS (1981). In those days, computers and software were expensive, and they were proprietary.
- the initial access was by Key (Improved ISAM in Hierarchic DBMS; Hashed in Network DBMS)
- the relations were implemented as pointers
which resulted in maintenance headaches, and export/import demanded a program
- in Hierarchic DBMS it was a genuine Tree (Directed Acyclic Graph)
- in the Network DBMS one had more flexibility, one could implement a Tree or a Network.
While the Keys were logical, the pointers were of course physical. The systems were limited due specifically to that.
For the love of Science (Logic; Sanity), one did not implement circular references (Cyclic Graphs). In other words, only true hierarchies (Directed Acyclic Graphs; Trees), as they exist in the real world or logical in the man-made world, were implemented.
1.2 Relational Model
The first to be based or founded in Logic, with a mathematical definition, which gave it licence to be called a Model. It changed the DBMS world. The main differences that are relevant to this question are:
- due to the mathematical definition
- it is therefore 100% Logical (ie. it is one level of abstraction removed from, the physical SQL implementation)
- there is nothing that cannot be defined
since the world has gone mad, I have to add the qualifier: anything in the natural universe and anything man-made that is logical, can be defined. Anything that is not logical is insanity
- the relations are implemented as Keys
which eliminated the maintenance headaches, and afforded effortless import/export
1.3 Anti-Relational
Dr E F Codd was an engineer, he worked for IBM, along with scientists. Likewise the other DBMS vendors had scientists and engineers.
Academia dislike Codd's work and IDEF1X because they are completely isolated from the industry and the DBMS vendors. They use and write about things that only academics have concocted. Both then, and all the way through to now:
they deny the reality of SQL compliant platforms and foster a “SQL" which is not compliant and not even a language;
they suppress IDEF1X, and instead foster ERD which is hopeless for modelling, and cannot handle Relational Keys (composite) and cannot be used for modelling of any kind
they disagree with Codd and practitioners such as me because we are not academics, we are realists
they suppress the Logical Relational Model, and promote a 1960’s (pre-DBMS) physical Record filing system, incorrectly marketed as “relational”. These are characterised by RecordIDs (physical records, not logical rows).
- Note that such RFS are primitive, very limited. They are placed in an SQL container for ease of access (DML) and convenience (backups; etc). Such limitations is falsely attributed to SQL, but they are in fact due to the primitive RFS.
RecordIDs do not provide row uniqueness, which is demanded in the RM, in order to prevent duplicate data. (They do provide RecordID uniqueness, which is quite irrelevant, and worse, you may think you have prevented data duplication when you have not- Further,
RecordIDs are always one additional non-data field, and one additional index more than the Relational equivalent.
- And they force more
JOINs, due to failing the Access Path Independence Rule in the RM.
For discussion, refer to:
Creating a Relational table with 2 different auto_increment, §1 & 2 only.
Thus they make unreasonable claims, due to ignorance of the RM, such as “the RM can’t do this or that”, which is true for their “RM”, but quite false for Codd’s RM.
1.4 SQL vs "SQL"
Likewise Codd defined a single data sub-language, and the major vendors (excluding Oracle) implemented it. That is the true SQL, which was made an ANSI->ISO/IEC Standard. There is a famous paper Codd’s Twelve Rules for compliance with his data sub-language, which the major vendors comply with, and the freeware do not even approach.
The freeware and Oracle are not SQL compliant, their use of the term SQL is unjustified. The implementation in Postgres and Oracle is not even a language.
Therefore, again due to being unaware of the RM and SQL; their isolation from the industry; and their fixation on their private “RM” and “SQL”, they make untrue claims such as “SQL can’t do this or that”, which is true for their “SQL”, and their “RM”, but hysterically false for the true RM and SQL.
This has lead to 95% of the databases in the world being labelled “relational” but they are not at all Relational, they provide none of the features and benefits of the Relational Model. Of course, it does not work as expected. So there is a movement away from Relational (actually “relational”), into all sorts of non-Relational “databases”.
The latest kid on the block is “graph databases”, which are not databases at all (no integrity, no standards), but they do provide a feature or function that “relational” or “SQL” supposedly cannot provide. Meanwhile, in reality, in Codd’s Relational Model and genuine SQL, there is nothing that cannot be defined, and data hierarchies (DAGs; Graphs; Trees) are effortless and straight-forward to design and implement.
Notably, one problem IBM specifically tasked Codd to solve was a specific problem in their HDBMS concerning the famous Bill of Materials problem, which he did solve and brilliantly. That is, dat hierarchies of various kinds are fully supported in the RM, and ordinary [genuine] SQL can be used to navigate them.
1.5 Developer as Modeller
Three issues are typical.
First, understand the above context, such that you appreciate that you have been bombarded by anti-Relational nonsense that cannot handle various logical data structures (eg. graphs) as “relational”, and that Relational and SQL handle all those structures quite well.
- Thus I will provide the rather simple solution to your question, in Relational terms, and which is easy to use via genuine SQL. You need understand that the notion that graph databases can do anything that the RM cannot do, or that it is superior in any way, is false.
The second issue is the common developer mindset, they focus on their GUI; the skin, and their need of the data. (I know what I need, and what the GUI looks like) which is easy because they are recommended by the academics to think in terms of an Excel spreadsheet (the horrible RecordIDs). Rather than what the data is, precisely.
- That cripples the modelling exercise. Genuine Data Modelling (Relational or not), is a science, one has to model the data, and only the data, with no consideration of use (use cases).
- Whereas usage changes with every release, and changes massively when unplanned usage it added
- Whereas the structure of data does not change (if modelled correctly, reflecting the real world from which the data is drawn).
Third, probably the most important, is the fact that the science and methods for analysing and modelling data is very different to that of analysing; designing; and modelling process. Unfortunately developers these days are enthralled with OO/ORM, due to the totally false notion that everything in the universe can be perceived and understood through the lens of an Object.
- They treat the “database” as a storage slave, the only purpose of which is to provide persistence for their magical Objects, never mind the refactoring and CRUD.
- The “database” is logically within the app, it can be accessed only through the app, and the great benefits, such as permanence; open access; etc, of Open Architecture are lost; unknown.
2 Solution • Relational Model
2.1 Questions
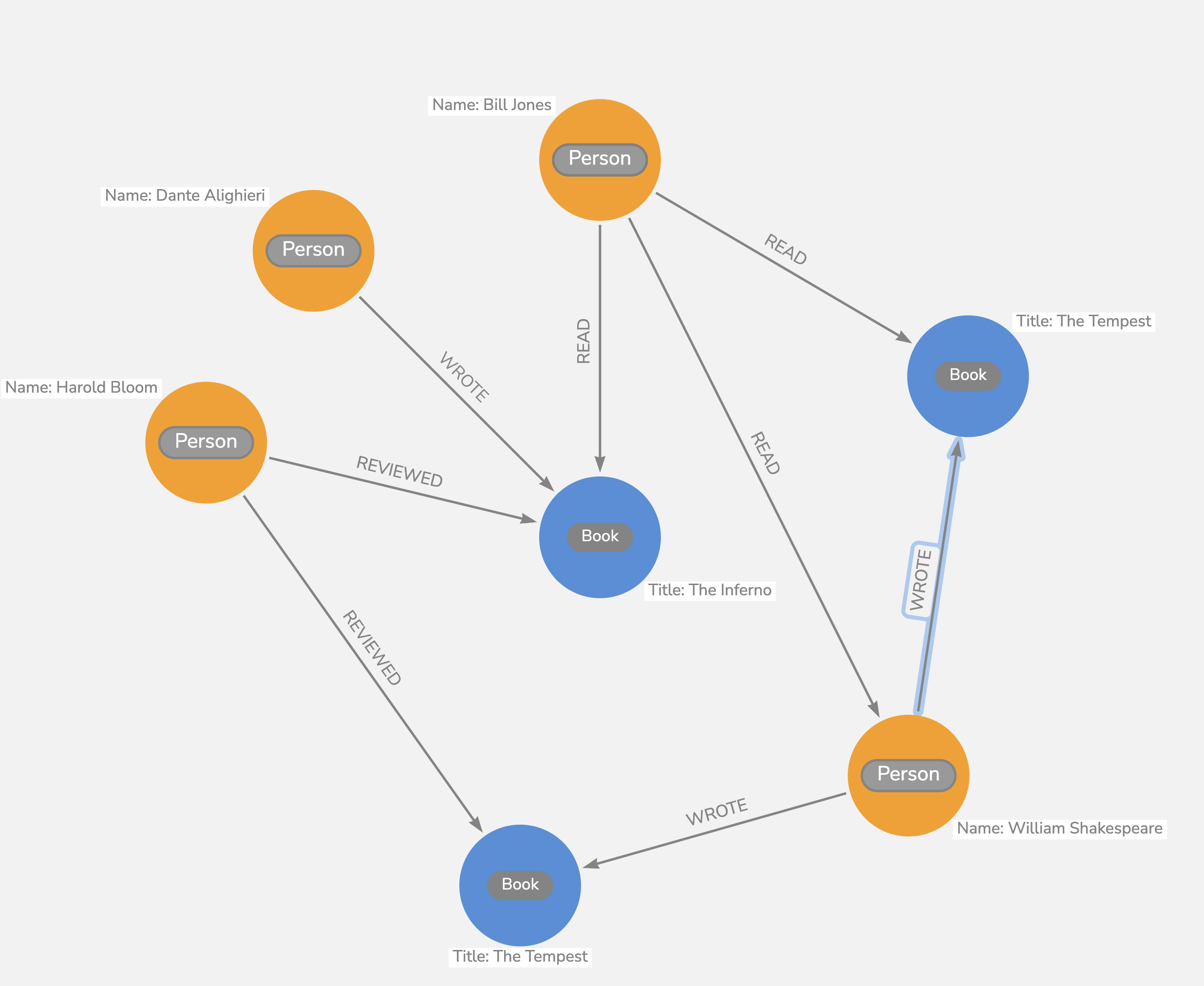
Now that we have the context and explanations above, we can consider the diagram you have provided. Note that is is a picture, not a model of any kind, and it concentrates on, it depicts, some example data, and some possible relations between that sample data. A good-looking diagram as well.
- But it is merely the output (use case) in full detail, in graphical rendition. It is not a graph (DAG; Tree). One might be forgiven if, due to the visual, one obtains the notion that it contains circular references (which the data actually does not). Again, too much focus on the use case, at the expense of understanding the data and modelling it (and modelling it Relationally instead of as a 1960’s Record Filing System).
If this were to be modeled in a relational database, what might the schema look like?
Thus I would ask you to release all notions re:
- physical
RecordIDs (beware of the anti-Relational ideas incorrectly posed as “relational”),
- use case mindset (what you need, as opposed to what the data is independent of what you need),
- graphs and graph “databases”, including that terminology, especially the excellent diagram of a few data samples (the graphic report of the data)
- any OO/ORM mindset you may have
such that you can understand ordinary Relational terminology and concepts, affectively. Stated otherwise, any attachment to the above will dumb-down the data model and thus the database.
This is pure Relational. It can be implemented, and will work effortlessly, in any genuine SQL platform (which excludes the freeware platforms and Oracle). Any and all reports will be supplied via a single SELECT. The sequence follows your questions.
If this were to be modeled in a relational database, what might the schema look like? My thought was breaking out every relationship and node out, something like:
Yes. Overlooking the minor errors, that is what Normalisation looks like.
We can remove the graph-centric names, because the database is intended to reflect reality, not the fact that just one of the many possible uses is to produce a graph from it. It can be used to provide any report from the data, not only a graph.
2.2 Relational Data Model • Initial
A first iteration of Relational data modelling, given in IDEF1X.
![Relational Data Model • Initial]()
Or, should all nodes be a single table?
No. That would be a flat file, completely un-Normalised. A monstrosity to implement; maintain; and SELECT from. It would have no Declarative Referential Integrity, and therefore it would not qualify as a database, let alone Relational database.
If we were to add Movies as another node, how would we show that an Review edge may go from a Person->Book OR a Person->Movie.
Forget about "edge", which is merely one of many types of possible displays, and focus on the data and the relations, which supports any type of display.
Each of those (Person; Book; Movie) would be a separate, discrete Fact ("node"), and each of the arrows a separate, discrete relation, with a clear VerbPhrase.
You have added the Movie entity, that requires substantial additional modelling. The ordinary pre-Relational (60’s and 70’s) and Relational (80’s) method employed to define an Item that is either a Book or a Movie, is a Subtype cluster.
It seems maybe a more generic way to do it might be: ...
Your attributes are incomplete. When you add the relevant attributes, you will end up with two un-Normalised files, with nullable fields. The polar opposite of a database, the usual nightmare to maintain and use.
Moving from the species to the genus is not a black-or-white decision, holding it as "always good" is a gross error. The Relational Model, and specifically correct Subtyping, implements both genus (Basetype) and species (Subtype), and thus affords unlimited use.
Are there any disadvantages of using this later approach instead?
Yes. There is always terrible disadvantages for going against Science, or the Standards that cover a subject. To enumerate a few:
- Declarative Referential Integrity (
FOREIGN KEY) is not possible, therefore the data has no integrity
- Massively complex SQL, for both the Transactions that are used to maintain the data, and the reports for extracting and displaying the data
- The “database” users will transform into assassins, due to the “database” being logically inaccessible
- A complete replacement of the “database”, and app code, is guaranteed.
2.3 Relational Data Model • Progressed
Try this, the second iteration in our modelling exercise. I have implemented the following rules (feel free to change them or add more, and I will update the data model):
- The Subtype cluster is Non-Exclusive, meaning that an
Item is either a Book, or a Movie, or both
- A
%Reviewer must first be a Reader/Viewer
( BookTitle, Sequence ) TINYINT is made unique via the Alternate Key, ie. two Authors are prevented from having the same Sequence for a given BookTitle
- Alternately, a
CONSTRAINT to ensure an incremental Sequence can be added, in which case the AK can be removed
![Relational Data Model • Progressed]()