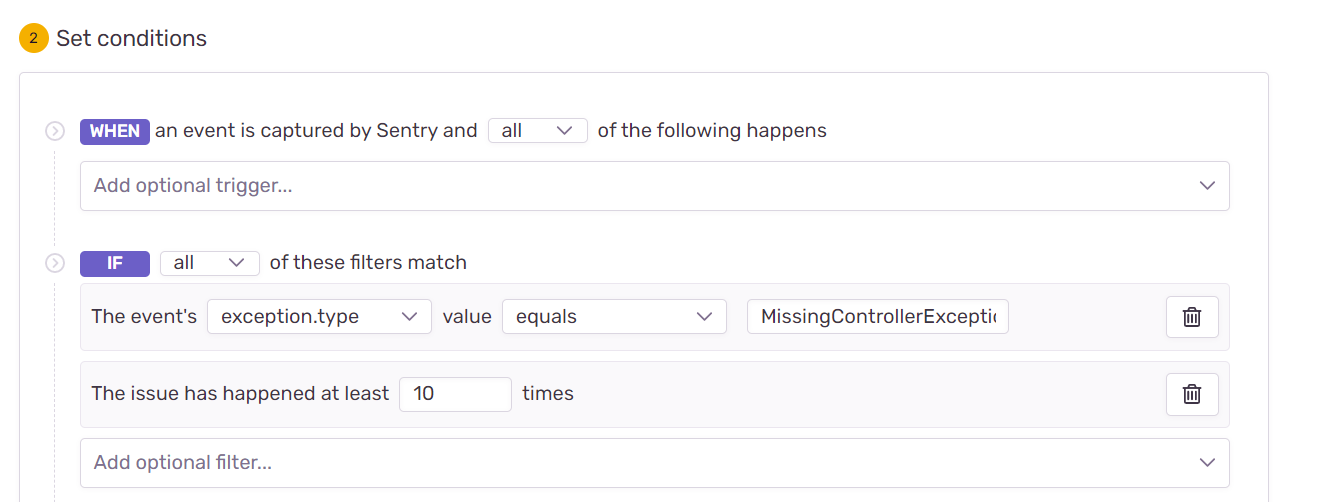
I have a Rails 5 application using raven-ruby to send exceptions to Sentry which then sends alerts to our Slack.
Raven.configure do |config|
config.dsn = ENV['SENTRY_DSN']
config.environments = %w[ production development ]
config.excluded_exceptions += []
config.async = lambda { |event|
SentryWorker.perform_async(event.to_hash)
}
end
class SentryWorker < ApplicationWorker
sidekiq_options queue: :default
def perform(event)
Raven.send_event(event)
end
end
It's normal for our Sidekiq jobs to throw exceptions and be retried. These are mostly intermittent API errors and timeouts which clear up on their own in a few minutes. Sentry is dutifully sending these false alarms to our Slack.
I've already added the retry_count to the jobs. How can I prevent Sentry from sending exceptions with a retry_count < N to Slack while still alerting for other exceptions? An example that should not be alerted will have extra context like this:
sidekiq: {
context: Job raised exception,
job: {
args: [{...}],
class: SomeWorker,
created_at: 1540590745.3296254,
enqueued_at: 1540607026.4979043,
error_class: HTTP::TimeoutError,
error_message: Timed out after using the allocated 13 seconds,
failed_at: 1540590758.4266324,
jid: b4c7a68c45b7aebcf7c2f577,
queue: default,
retried_at: 1540600397.5804272,
retry: True,
retry_count: 2
},
}
What are the pros and cons of not sending them to Sentry at all vs sending them to Sentry but not being alerted?