Can somebody tell me why Dijkstra's algorithm for single source shortest path assumes that the edges must be non-negative.
I am talking about only edges not the negative weight cycles.
Can somebody tell me why Dijkstra's algorithm for single source shortest path assumes that the edges must be non-negative.
I am talking about only edges not the negative weight cycles.
Recall that in Dijkstra's algorithm, once a vertex is marked as "closed" (and out of the open set) - the algorithm found the shortest path to it, and will never have to develop this node again - it assumes the path developed to this path is the shortest.
But with negative weights - it might not be true. For example:
A
/ \
/ \
/ \
5 2
/ \
B--(-10)-->C
V={A,B,C} ; E = {(A,C,2), (A,B,5), (B,C,-10)}
Dijkstra from A will first develop C, and will later fail to find A->B->C
EDIT a bit deeper explanation:
Note that this is important, because in each relaxation step, the algorithm assumes the "cost" to the "closed" nodes is indeed minimal, and thus the node that will next be selected is also minimal.
The idea of it is: If we have a vertex in open such that its cost is minimal - by adding any positive number to any vertex - the minimality will never change.
Without the constraint on positive numbers - the above assumption is not true.
Since we do "know" each vertex which was "closed" is minimal - we can safely do the relaxation step - without "looking back". If we do need to "look back" - Bellman-Ford offers a recursive-like (DP) solution of doing so.
A->B will 5 and A->C will 2. Then B->C will -5. So the value of C will be -5 same as bellman-ford. How is this not giving the right answer? –
Woodbury A with value of 0. Then, it will look on the minimal valued node, B is 5 and C is 2. The minimal is C, so it will close C with value 2 and will never look back, when later B is closed, it cannot modify the value of C, since it is already "closed". –
Displayed A -> B -> C? It will first update C's distance to 2, and then B's distance to 5. Assuming that in your graph there are no outgoing edges from C, then we do nothing when visiting C (and its distance is still 2). Then we visit D's adjacent nodes, and the only adjacent node is C, whose new distance is -5. Note that in the Dijkstra's algorithm, we also keep track of the parent from which we reach (and update) the node, and doing it from C, you will get the parent B, and then A, resulting in a correct result. What am I missing? –
Overword the nodes for wbLich the path o{ nrinimum lengti from P is known (set A) and others (sets B,C) . He later specifically satates: Consider all branches z connecting the node just transfeired to set A with nodes R in sets B or C, so he considers relaxing only nodes NOT in A - those who's path is not discovered yet. –
Displayed 
When I refer to Dijkstra’s algorithm in my explanation I will be talking about the Dijkstra's Algorithm as implemented below,

So starting out the values (the distance from the source to the vertex) initially assigned to each vertex are,
We first extract the vertex in Q = [A,B,C] which has smallest value, i.e. A, after which Q = [B, C]. Note A has a directed edge to B and C, also both of them are in Q, therefore we update both of those values,

Now we extract C as (2<5), now Q = [B]. Note that C is connected to nothing, so line16 loop doesn't run.

Finally we extract B, after which  . Note B has a directed edge to C but C isn't present in Q therefore we again don't enter the for loop in
. Note B has a directed edge to C but C isn't present in Q therefore we again don't enter the for loop in line16,

So we end up with the distances as

Note how this is wrong as the shortest distance from A to C is 5 + -10 = -5, when you go  .
.
So for this graph Dijkstra's Algorithm wrongly computes the distance from A to C.
This happens because Dijkstra's Algorithm does not try to find a shorter path to vertices which are already extracted from Q.
What the line16 loop is doing is taking the vertex u and saying "hey looks like we can go to v from source via u, is that (alt or alternative) distance any better than the current dist[v] we got? If so lets update dist[v]"
Note that in line16 they check all neighbors v (i.e. a directed edge exists from u to v), of u which are still in Q. In line14 they remove visited notes from Q. So if x is a visited neighbour of u, the path is not even considered as a possible shorter way from source to v.
In our example above, C was a visited neighbour of B, thus the path was not considered, leaving the current shortest path
unchanged.
This is actually useful if the edge weights are all positive numbers, because then we wouldn't waste our time considering paths that can't be shorter.
So I say that when running this algorithm if x is extracted from Q before y, then its not possible to find a path -  which is shorter. Let me explain this with an example,
which is shorter. Let me explain this with an example,
As y has just been extracted and x had been extracted before itself, then dist[y] > dist[x] because otherwise y would have been extracted before x. (line 13 min distance first)
And as we already assumed that the edge weights are positive, i.e. length(x,y)>0. So the alternative distance (alt) via y is always sure to be greater, i.e. dist[y] + length(x,y)> dist[x]. So the value of dist[x] would not have been updated even if y was considered as a path to x, thus we conclude that it makes sense to only consider neighbors of y which are still in Q (note comment in line16)
But this thing hinges on our assumption of positive edge length, if length(u,v)<0 then depending on how negative that edge is we might replace the dist[x] after the comparison in line18.
So any dist[x] calculation we make will be incorrect if x is removed before all vertices v - such that x is a neighbour of v with negative edge connecting them - is removed.
Because each of those v vertices is the second last vertex on a potential "better" path from source to x, which is discarded by Dijkstra’s algorithm.
So in the example I gave above, the mistake was because C was removed before B was removed. While that C was a neighbour of B with a negative edge!
Just to clarify, B and C are A's neighbours. B has a single neighbour C and C has no neighbours. length(a,b) is the edge length between the vertices a and b.
Dijkstra's algorithm assumes paths can only become 'heavier', so that if you have a path from A to B with a weight of 3, and a path from A to C with a weight of 3, there's no way you can add an edge and get from A to B through C with a weight of less than 3.
This assumption makes the algorithm faster than algorithms that have to take negative weights into account.
Correctness of Dijkstra's algorithm:
We have 2 sets of vertices at any step of the algorithm. Set A consists of the vertices to which we have computed the shortest paths. Set B consists of the remaining vertices.
Inductive Hypothesis: At each step we will assume that all previous iterations are correct.
Inductive Step: When we add a vertex V to the set A and set the distance to be dist[V], we must prove that this distance is optimal. If this is not optimal then there must be some other path to the vertex V that is of shorter length.
Suppose this some other path goes through some vertex X.
Now, since dist[V] <= dist[X] , therefore any other path to V will be atleast dist[V] length, unless the graph has negative edge lengths.
Thus for dijkstra's algorithm to work, the edge weights must be non negative.
Try Dijkstra's algorithm on the following graph, assuming A is the source node and D is the destination, to see what is happening:

Note that you have to follow strictly the algorithm definition and you should not follow your intuition (which tells you the upper path is shorter).
The main insight here is that the algorithm only looks at all directly connected edges and it takes the smallest of these edge. The algorithm does not look ahead. You can modify this behavior , but then it is not the Dijkstra algorithm anymore.
A->B will 1 and A->C will 100. Then B->D will 2. Then C->D will -4900. So the value of D will be -4900 same as bellman-ford. How is this not giving the right answer? –
Woodbury A->B will be 1 and A->C will be 100. Then B is explored and sets B->D to 2. Then D is explored because currently it has the shortest path back to the source? Would I be correct in saying that if B->D was 100, C would've been explored first? I understand all other examples people give except yours. –
Pampa Dijkstra's Algorithm assumes that all edges are positive weighted and this assumption helps the algorithm run faster ( O(E*log(V) ) than others which take into account the possibility of negative edges (e.g bellman ford's algorithm with complexity of O(V^3)).
This algorithm wont give the correct result in the following case (with a -ve edge) where A is the source vertex:

Here, the shortest distance to vertex D from source A should have been 6. But according to Dijkstra's method the shortest distance will be 7 which is incorrect.
Also, Dijkstra's Algorithm may sometimes give correct solution even if there are negative edges. Following is an example of such a case:
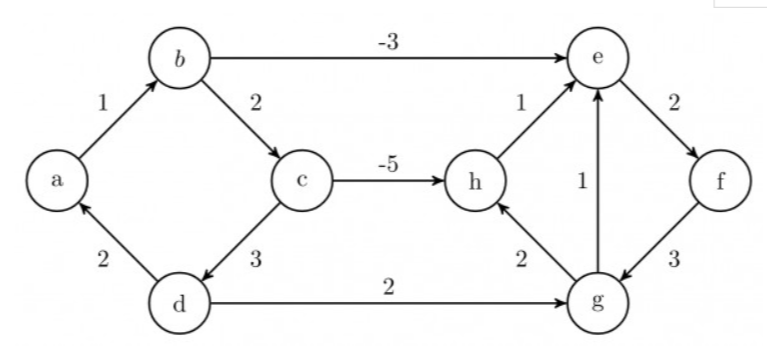
However, It will never detect a negative cycle and always produce a result which will always be incorrect if a negative weight cycle is reachable from the source, as in such a case there exists no shortest path in the graph from the source vertex.
You can use dijkstra's algorithm with negative edges not including negative cycle, but you must allow a vertex can be visited multiple times and that version will lose it's fast time complexity.
In that case practically I've seen it's better to use SPFA algorithm which have normal queue and can handle negative edges.
Recall that in Dijkstra's algorithm, once a vertex is marked as "closed" (and out of the open set) -it assumes that any node originating from it will lead to greater distance so, the algorithm found the shortest path to it, and will never have to develop this node again, but this doesn't hold true in case of negative weights.
Adding few points to the explanation, on top of the previous answers, for the following simple example,

The other answers so far demonstrate pretty well why Dijkstra's algorithm cannot handle negative weights on paths.
But the question itself is maybe based on a wrong understanding of the weight of paths. If negative weights on paths would be allowed in pathfinding algorithms in general, then you would get permanent loops that would not stop.
Consider this:
A <- 5 -> B <- (-1) -> C <- 5 -> D
What is the optimal path between A and D?
Any pathfinding algorithm would have to continuously loop between B and C because doing so would reduce the weight of the total path. So allowing negative weights for a connection would render any pathfindig algorithm moot, maybe except if you limit each connection to be used only once.
So, to explain this in more detail, consider the following paths and weights:
Path | Total weight
ABCD | 9
ABCBCD | 7
ABCBCBCD | 5
ABCBCBCBCD | 3
ABCBCBCBCBCD | 1
ABCBCBCBCBCBCD | -1
...
So, what's the perfect path? Any time the algorithm adds a BC step, it reduces the total weight by 2.
So the optimal path is A (BC) D with the BC part being looped forever.
Since Dijkstra's goal is to find the optimal path (not just any path), it, by definition, cannot work with negative weights, since it cannot find the optimal path.
Dijkstra will actually not loop, since it keeps a list of nodes that it has visited. But it will not find a perfect path, but instead just any path.
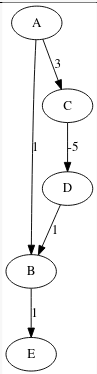
I'll add my 2 cents here: with a SMALL ADAPTATION Dijkstra's CAN WORK with negative weight edges. Consider this graph:

This is Dijkstra's algorithm adapted in python 3.9:
import heapq
# A graph has nodes, nodes have edges, edges are nodes with weights
graph1 = {
'A': {'B': 1, 'C': 10},
'B': {'D': 2},
'C': {'D': -8},
'D': {}
}
def dijkstra_with_negative(graph: dict[str, dict[str, int]], source: str, dest: str):
queue = []
visited = []
dist = {node: float('inf') for node in graph}
previous = {}
# Improvement for negative graph: a heap doesn't need to be used.
# Try instead collections.deque, optimized for append and pop
heapq.heappush(queue, (0, source))
dist[source] = 0
while len(queue) > 0:
(nodeDist, node) = heapq.heappop(queue)
if nodeDist > dist[dest]:
print('For non negative, would exit now with:')
print(get_path(dist, previous, dest))
# break
if node in visited:
#avoid revisits and negative cycles that would result in infinite loop
continue
visited.append(node)
for edge, edgeDist in graph[node].items():
newDist = edgeDist + dist[node]
if newDist < dist[edge]:
dist[edge] = newDist
previous[edge] = node
heapq.heappush(queue, (newDist, edge))
# Check for negative weight cycles
for node in graph:
for edge, edgeDist in graph[node].items():
assert dist[node] + edgeDist >= dist[edge], "Negative weight cycle detected!"
# print path with nodes and distances
print('Final path:')
print(get_path(dist, previous, dest))
def get_path(dist: list, previous: list, node: str) -> list:
path = []
while node is not None:
path.append((node, dist[node]))
node = previous.get(node, None)
path.reverse()
return path
dijkstra_with_negative(graph1, 'A', 'D')
As you can see, the adaptation is very small:
I was just learning this, adding my two cents here because I think the biggest confusion is the difference between implementation detail and the theory. The original algorithm is proof based...so the idea is that you don't look back on something you already deemed shortest. Once it's shortest so far, it's just gone, it doesn't exist anymore to you aside from the fact that the shortest distance is now some number d.
So according to the original THEORY, implementation wise, it would use a heap to keep BOTH the vertex and distance. For example, you have array [(0,S),(inf,A),(inf,B)] as your starting point.
So is a case where you have

remember that you delete the minimum in each iteration, so literally you only have [(3,A),(4,B)] in the first loop, because you popped S. Next you pop A, so the only thing left in your heap is [(4,B)]
Yes you would think, oh, after I expand B, there is an edge to A, I'll just update it. But then you look at the heap, where you keep your distance...it's empty. So it's not because you can't expand B, it's because A can't be updated (you don't look back).
So if you were to use some other structure to keep track of things, then yes, it could handles some negative cases like the one above, but then that wouldn't be the original algorithm's idea because you looked back.
In Unweighted graph
Dijkstra can even work without set or priority queue, even if you just use STACK the algorithm will work but with Stack its time of execution will increase
Dijkstra don't repeat a node once its processed becoz it always tooks the minimum route , which means if you come to that node via any other path it will certainly have greater distance
For ex -
(0)
/
6 5
/
(2) (1)
\ /
4 7
\ /
(9)
here once you get to node 1 via 0 (as its minimum out of 5 and 6)so now there is no way you can get a minimum value for reaching 1 because all other path will add value to 5 and not decrease it
more over with Negative weights it will fall into infinite loop
In Unweighted graph Dijkstra Algo will fall into loop if it has negative weight
In Directed graph Dijkstra Algo will give RIGHT ANSWER except in case of Negative Cycle
Who says Dijkstra never visit a node more than once are 500% wrong also who says Dijkstra can't work with negative weight are wrong
© 2022 - 2024 — McMap. All rights reserved.
{kind=link}