I've been using the PDFBOX version 2.0.0 in a Java project to convert pdfs to text.
several of my pdfs are missing the ToUnicode method, so they come out in Gibberish while I export them.
2016-09-14 10:44:55 WARN org.apache.pdfbox.pdmodel.font.PDSimpleFont(1):322 - No Unicode mapping for 694 (30) in font MPBAAA+F1
in the WARN above, instead of the real character, a gibberish unicode (30) was presented.
I was able to overcome it by editing the additional.txt file in pdfbox, since from trial & error I understood that the code of the character (694 in this case) represents a certain Hebrew letter (צ).
here's a short example of what I've edited inside the file:
-694;05E6 #HexaDecimal value for the letter צ
-695;05E7
-696;05E8
later I've encountered almost the same warning on a different pdf, but instead of gibberish characters I got no characters at all. a more detailed explination of this issue can be seen here - pdf reading via pdfbox in java
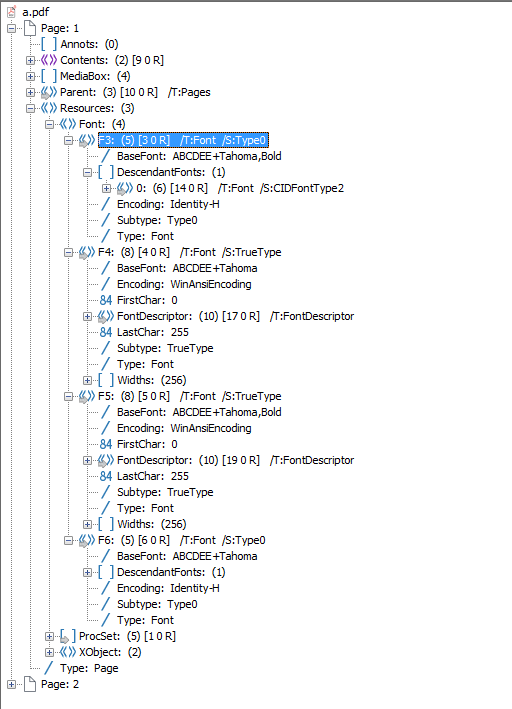
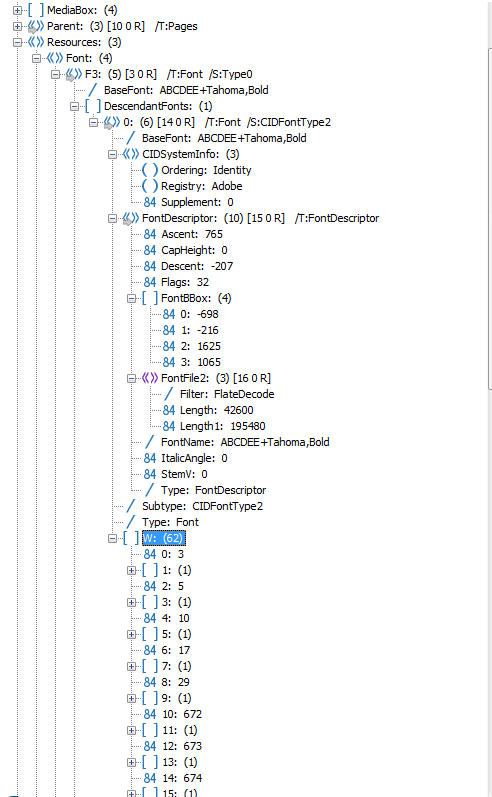
2016-09-14 11:07:10 WARN org.apache.pdfbox.pdmodel.font.PDType0Font(1):431 - No Unicode mapping for CID+694 (694) in font ABCDEE+Tahoma,Bold
As you can see, the warning came from a different class (PDType0Font) rather than the first warning (PDSimpleFont), but the code name (694) is the same in both of them and they are both talking about the same character.
Does there's a different file that I should edit other than additional.txt to point the 694 code (the Hebrew letter צ) to it's correct unicode?
Thanks