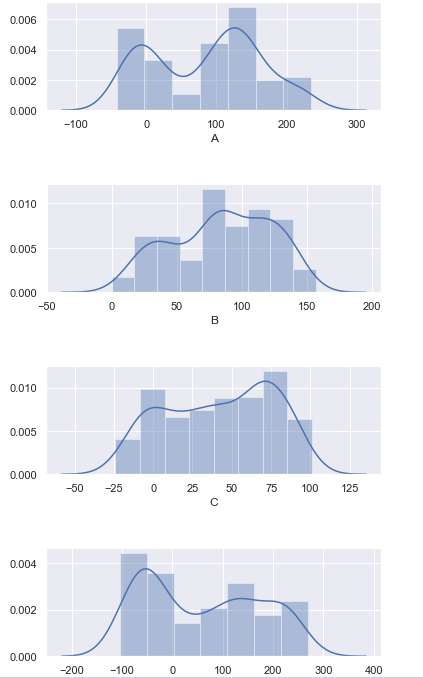
I 'm using Seaborn in a Jupyter notebook to plot histograms like this:
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv('CTG.csv', sep=',')
sns.distplot(df['LBE'])
I have an array of columns with values that I want to plot histogram for and I tried plotting a histogram for each of them:
continous = ['b', 'e', 'LBE', 'LB', 'AC']
for column in continous:
sns.distplot(df[column])
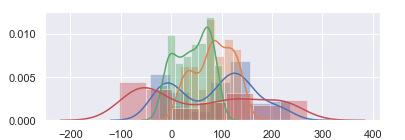
And I get this result - only one plot with (presumably) all histograms:
My desired result is multiple histograms that looks like this (one for each variable):
How can I do this?