I have bucket which is used as destination for a Kinesis Firehose stream.
Firehose automatically creates date-based prefixes on that bucket using the yyyy/mm/dd/HH format.
Then I created a crawler that will search for data into this bucket and configured it as follow:
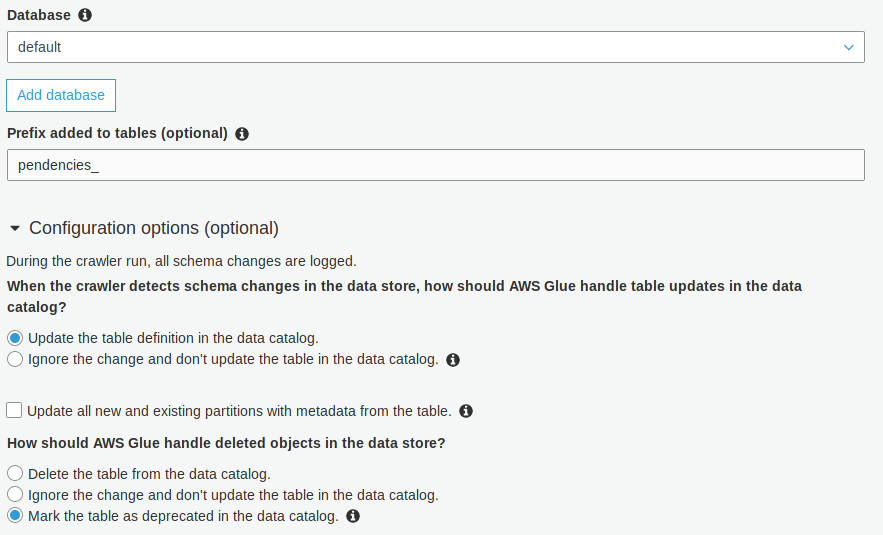
After running the crawler, it creates a table with the following schema:
| # | Column name | Data type | Key |
| --- | ----------- | --------- | ------------- |
| 1 | numberissues | int | |
| 2 | group | string | |
| 3 | createdat | string | |
| 4 | companyunitid | string | |
| 5 | partition_0 | string | Partition (0) |
| 6 | partition_1 | string | Partition (1) |
| 7 | partition_2 | string | Partition (2) |
| 8 | partition_3 | string | Partition (3) |
If I rename the partition-* to their right counterparts year, month, day and hour, the table is ready for me to use.
However, if the crawler runs again, the schema revets the column names to the original partition-*.
I know this would work for Hive partition schemas year=2018/month=04..., but I want to know if it's possible to "hint" Glue about the partition field names.
Another alternative would be trying to change the Firehose prefixing, but I couldn't find anything that suggests this is even possible.