I don't know of any builtin functions in Python to do this.
I can give you a list of possible functions in the Python ecosystem you can use. This is in no way a complete list of functions, and there are probably quite a few methods out there that I am not aware of.
If the data is ordered, but you don't know which data point is the first and which data point is last:
- Use the directed Hausdorff distance
If the data is ordered, and you know the first and last points are correct:
- Discrete Fréchet distance *
- Dynamic Time Warping (DTW) *
- Partial Curve Mapping (PCM) **
- A Curve-Length distance metric (uses arc length distance from beginning to end) **
- Area between two curves **
* Generally mathematical method used in a variety of machine learning tasks
** Methods I've used to identify unique material hysteresis responses
First let's assume we have two of the exact same random X Y data. Note that all of these methods will return a zero. You can install the similaritymeasures from pip if you do not have it.
import numpy as np
from scipy.spatial.distance import directed_hausdorff
import similaritymeasures
import matplotlib.pyplot as plt
# Generate random experimental data
np.random.seed(121)
x = np.random.random(100)
y = np.random.random(100)
P = np.array([x, y]).T
# Generate an exact copy of P, Q, which we will use to compare
Q = P.copy()
dh, ind1, ind2 = directed_hausdorff(P, Q)
df = similaritymeasures.frechet_dist(P, Q)
dtw, d = similaritymeasures.dtw(P, Q)
pcm = similaritymeasures.pcm(P, Q)
area = similaritymeasures.area_between_two_curves(P, Q)
cl = similaritymeasures.curve_length_measure(P, Q)
# all methods will return 0.0 when P and Q are the same
print(dh, df, dtw, pcm, cl, area)
The printed output is
0.0, 0.0, 0.0, 0.0, 0.0, 0.0
This is because the curves P and Q are exactly the same!
Now let's assume P and Q are different.
# Generate random experimental data
np.random.seed(121)
x = np.random.random(100)
y = np.random.random(100)
P = np.array([x, y]).T
# Generate random Q
x = np.random.random(100)
y = np.random.random(100)
Q = np.array([x, y]).T
dh, ind1, ind2 = directed_hausdorff(P, Q)
df = similaritymeasures.frechet_dist(P, Q)
dtw, d = similaritymeasures.dtw(P, Q)
pcm = similaritymeasures.pcm(P, Q)
area = similaritymeasures.area_between_two_curves(P, Q)
cl = similaritymeasures.curve_length_measure(P, Q)
# all methods will return 0.0 when P and Q are the same
print(dh, df, dtw, pcm, cl, area)
The printed output is
0.107, 0.743, 37.69, 21.5, 6.86, 11.8
which quantify how different P is from Q according to each method.
You now have many methods to compare the two curves. I would start with DTW, since this has been used in many time series applications which look like the data you have uploaded.
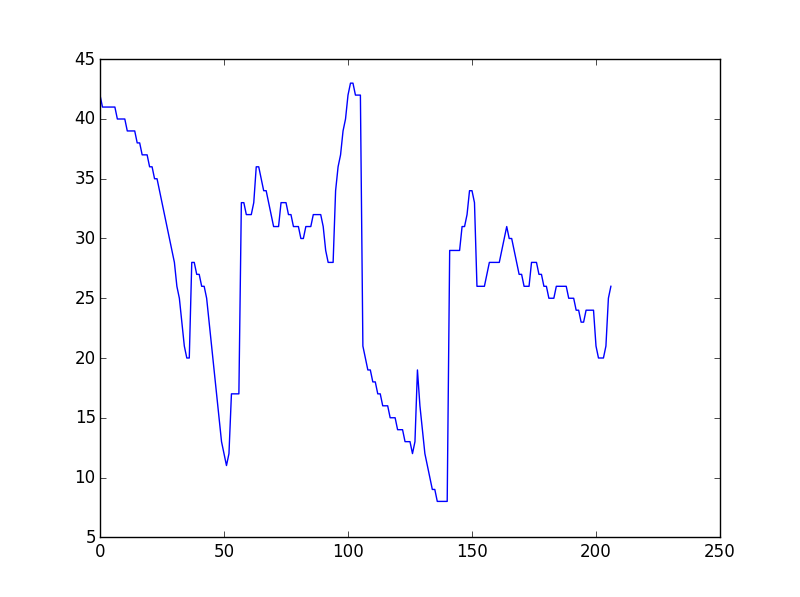
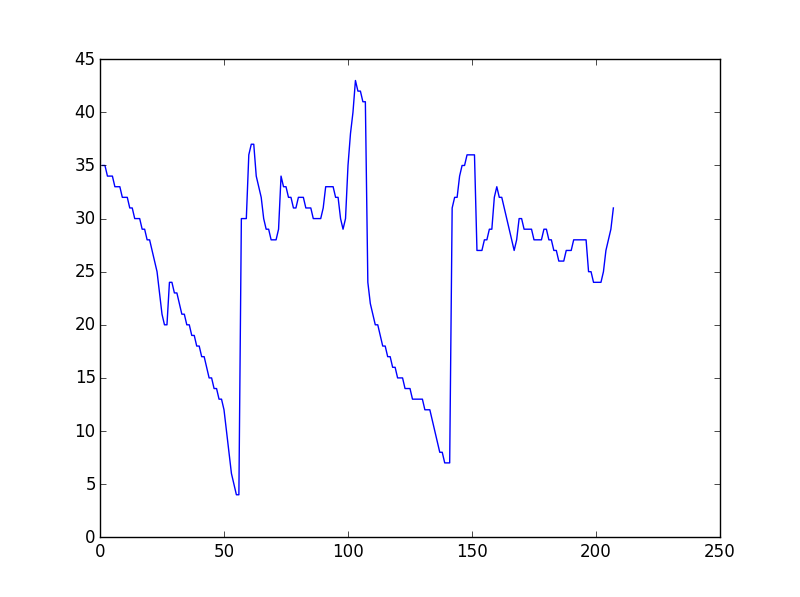
We can visualize what P and Q look like with the following code.
plt.figure()
plt.plot(P[:, 0], P[:, 1])
plt.plot(Q[:, 0], Q[:, 1])
plt.show()
![Two random paths in the XY space]()