I am trying to use SpaCy for entity context recognition in the world of ontologies. I'm a novice at using SpaCy and just playing around for starters.
I am using the ENVO Ontology as my 'patterns' list for creating a dictionary for entity recognition. In simple terms the data is an ID (CURIE) and the name of the entity it corresponds to along with its category.
Screenshot of my sample data:
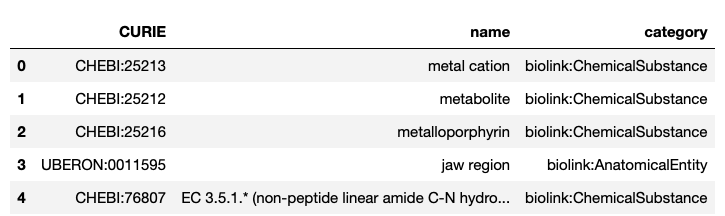
The following is the workflow of my initial code:
- Creating patterns and terms
# Set terms and patterns
terms = {}
patterns = []
for curie, name, category in envoTerms.to_records(index=False):
if name is not None:
terms[name.lower()] = {'id': curie, 'category': category}
patterns.append(nlp(name))
- Setup a custom pipeline
@Language.component('envo_extractor')
def envo_extractor(doc):
matches = matcher(doc)
spans = [Span(doc, start, end, label = 'ENVO') for matchId, start, end in matches]
doc.ents = spans
for i, span in enumerate(spans):
span._.set("has_envo_ids", True)
for token in span:
token._.set("is_envo_term", True)
token._.set("envo_id", terms[span.text.lower()]["id"])
token._.set("category", terms[span.text.lower()]["category"])
return doc
# Setter function for doc level
def has_envo_ids(self, tokens):
return any([t._.get("is_envo_term") for t in tokens])
##EDIT: #################################################################
def resolve_substrings(matcher, doc, i, matches):
# Get the current match and create tuple of entity label, start and end.
# Append entity to the doc's entity. (Don't overwrite doc.ents!)
match_id, start, end = matches[i]
entity = Span(doc, start, end, label="ENVO")
doc.ents += (entity,)
print(entity.text)
#########################################################################
- Implement the custom pipeline
nlp = spacy.load("en_core_web_sm")
matcher = PhraseMatcher(nlp.vocab)
#### EDIT: Added 'on_match' rule ################################
matcher.add("ENVO", None, *patterns, on_match=resolve_substrings)
nlp.add_pipe('envo_extractor', after='ner')
and the pipeline looks like this
[('tok2vec', <spacy.pipeline.tok2vec.Tok2Vec at 0x7fac00c03bd0>),
('tagger', <spacy.pipeline.tagger.Tagger at 0x7fac0303fcc0>),
('parser', <spacy.pipeline.dep_parser.DependencyParser at 0x7fac02fe7460>),
('ner', <spacy.pipeline.ner.EntityRecognizer at 0x7fac02f234c0>),
('envo_extractor', <function __main__.envo_extractor(doc)>),
('attribute_ruler',
<spacy.pipeline.attributeruler.AttributeRuler at 0x7fac0304a940>),
('lemmatizer',
<spacy.lang.en.lemmatizer.EnglishLemmatizer at 0x7fac03068c40>)]
- Set extensions
# Set extensions to tokens, spans and docs
Token.set_extension('is_envo_term', default=False, force=True)
Token.set_extension("envo_id", default=False, force=True)
Token.set_extension("category", default=False, force=True)
Doc.set_extension("has_envo_ids", getter=has_envo_ids, force=True)
Doc.set_extension("envo_ids", default=[], force=True)
Span.set_extension("has_envo_ids", getter=has_envo_ids, force=True)
Now when I run the text 'tissue culture', it throws me an error:
nlp('tissue culture')
ValueError: [E1010] Unable to set entity information for token 0 which is included in more than one span in entities, blocked, missing or outside.
I know why the error occurred. It is because there are 2 entries for the 'tissue culture' phrase in the ENVO database as shown below:

Ideally I'd expect the appropriate CURIE to be tagged depending on the phrase that was present in the text. How do I address this error?
My SpaCy Info:
============================== Info about spaCy ==============================
spaCy version 3.0.5
Location *irrelevant*
Platform macOS-10.15.7-x86_64-i386-64bit
Python version 3.9.2
Pipelines en_core_web_sm (3.0.0)