I have a dataframe which I am writing to excel using xlsxwriter and I want there to be autofilter applied to all columns where the header is not blank in my spreadsheet without having to specify a range (e.g. A1:D1). Is there any way to do this?
Is there a way to add autofilter to all columns using xlsxwriter without specifying a column range?
Asked Answered
You will need to specify the range in some way but you can do it programatically based on the shape() of the data frame.
For example:
import xlsxwriter
import pandas as pd
df = pd.DataFrame({'A' : [1, 2, 3, 4, 5, 6, 7, 8],
'B' : [1, 2, 3, 4, 5, 6, 7, 8],
'C' : [1, 2, 3, 4, 5, 6, 7, 8],
'D' : [1, 2, 3, 4, 5, 6, 7, 8]})
writer = pd.ExcelWriter('test.xlsx', engine = 'xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='Sheet1')
# Get the xlsxwriter objects from the dataframe writer object.
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Apply the autofilter based on the dimensions of the dataframe.
worksheet.autofilter(0, 0, df.shape[0], df.shape[1])
workbook.close()
writer.save()
Output:
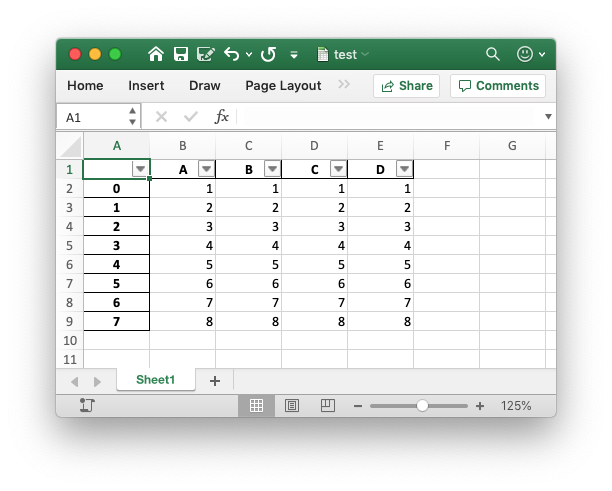
Thank you for the prompt response! This is working for me, but, there is one exception. I am also getting a filter on an extra column after my dataframe ends. Is there a way to remove that? For now I am using worksheet.autofilter(0, 0, df.shape[0], df.shape[1]-1) which works. –
Southern
I presume you use "index = False" option in df.to_excel() call. In that case you have found the right way to do the autofilter with your "-1" correction. Cell 'A1' in Row-column notation is (0, 0): xlsxwriter.readthedocs.io/working_with_cell_notation.html and thus the correction is needed. –
Spikelet
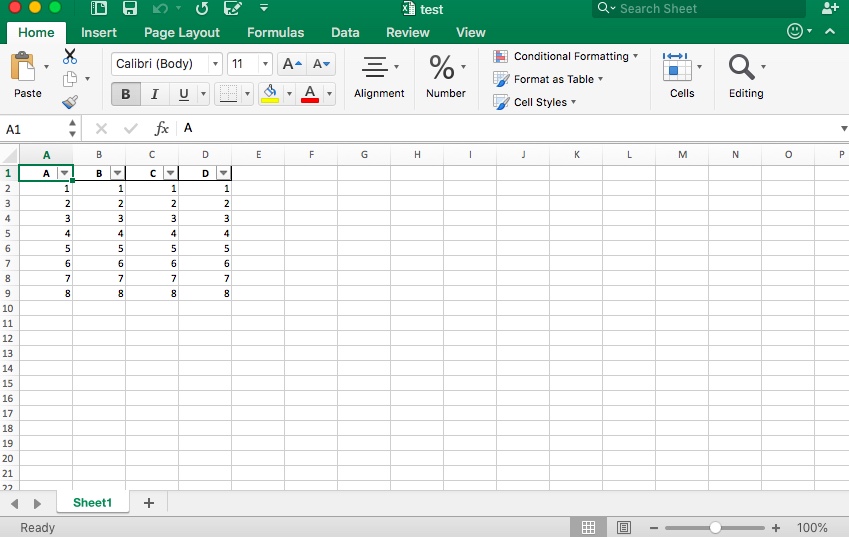
In to_excel() function set index=False
import xlsxwriter
import pandas as pd
df = pd.DataFrame({'A' : [1, 2, 3, 4, 5, 6, 7, 8],
'B' : [1, 2, 3, 4, 5, 6, 7, 8],
'C' : [1, 2, 3, 4, 5, 6, 7, 8],
'D' : [1, 2, 3, 4, 5, 6, 7, 8]})
writer = pd.ExcelWriter('test.xlsx', engine = 'xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='Sheet1', index=False)
# Get the xlsxwriter objects from the dataframe writer object.
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Apply the autofilter based on the dimensions of the dataframe.
worksheet.autofilter(0, 0, df.shape[0], df.shape[1]-1)
workbook.close()
{kind=link}
© 2022 - 2024 — McMap. All rights reserved.