Does anyone know what are the Git limits for number of files and size of files?
What are the file limits in Git (number and size)?
1. Giving someone my 107 GB repo via my 11 GB
2. Comparing changes between copied folder revisions in
On Windows, the max filesize is 4 GB (as of July 2020), due to a bug: github.com/git-for-windows/git/issues/1063 –
Sldney
This message from Linus himself can help you with some other limits
[...] CVS, ie it really ends up being pretty much oriented to a "one file at a time" model.
Which is nice in that you can have a million files, and then only check out a few of them - you'll never even see the impact of the other 999,995 files.
Git fundamentally never really looks at less than the whole repo. Even if you limit things a bit (ie check out just a portion, or have the history go back just a bit), git ends up still always caring about the whole thing, and carrying the knowledge around.
So git scales really badly if you force it to look at everything as one huge repository. I don't think that part is really fixable, although we can probably improve on it.
And yes, then there's the "big file" issues. I really don't know what to do about huge files. We suck at them, I know.
See more in my other answer: the limit with Git is that each repository must represent a "coherent set of files", the "all system" in itself (you can not tag "part of a repository").
If your system is made of autonomous (but inter-dependent) parts, you must use submodules.
As illustrated by Talljoe's answer, the limit can be a system one (large number of files), but if you do understand the nature of Git (about data coherency represented by its SHA-1 keys), you will realize the true "limit" is a usage one: i.e, you should not try to store everything in a Git repository, unless you are prepared to always get or tag everything back. For some large projects, it would make no sense.
For a more in-depth look at git limits, see "git with large files"
(which mentions git-lfs: a solution to store large files outside the git repo. GitHub, April 2015)
The three issues that limits a git repo:
- huge files (the xdelta for packfile is in memory only, which isn't good with large files)
- huge number of files, which means, one file per blob, and slow git gc to generate one packfile at a time.
- huge packfiles, with a packfile index inefficient to retrieve data from the (huge) packfile.
A more recent thread (Feb. 2015) illustrates the limiting factors for a Git repo:
Will a few simultaneous clones from the central server also slow down other concurrent operations for other users?
There are no locks in server when cloning, so in theory cloning does not affect other operations. Cloning can use lots of memory though (and a lot of cpu unless you turn on reachability bitmap feature, which you should).
Will '
git pull' be slow?If we exclude the server side, the size of your tree is the main factor, but your 25k files should be fine (linux has 48k files).
'
git push'?This one is not affected by how deep your repo's history is, or how wide your tree is, so should be quick..
Ah the number of refs may affect both
git-pushandgit-pull.
I think Stefan knows better than I in this area.'
git commit'? (It is listed as slow in reference 3.) 'git status'? (Slow again in reference 3 though I don't see it.)
(alsogit-add)Again, the size of your tree. At your repo's size, I don't think you need to worry about it.
Some operations might not seem to be day-to-day but if they are called frequently by the web front-end to GitLab/Stash/GitHub etc then they can become bottlenecks. (e.g. '
git branch --contains' seems terribly adversely affected by large numbers of branches.)
git-blamecould be slow when a file is modified a lot.
@Thr4wn: see also https://mcmap.net/q/12700/-git-submodule-update/… for more on the GitPro submodule page. For a shorter version: stackoverflow.com/questions/2065559/… –
Ottava
Updated link for git submoules documentation = git-scm.com/book/en/Git-Tools-Submodules –
Birgitbirgitta
I really wonder, with so much of sqlite and many database alternatives available on linux, why they couldn't simply use database which is easy to backup, replicate and scale. –
Mach
"git scales really badly if you force it to look at everything as one huge repository" what does this say about the scalability of monorepos? –
Everyman
@Everyman What is says is... that citation is from 10 years ago. Since then, in 2017, Microsoft has its own monorepo (devblogs.microsoft.com/bharry/…: 300GB+) and improvements are still forthcoming in 2019: https://mcmap.net/q/12702/-how-does-git-create-commits-so-fast –
Ottava
There is no real limit -- everything is named with a 160-bit name. The size of the file must be representable in a 64 bit number so no real limit there either.
There is a practical limit, though. I have a repository that's ~8GB with >880,000 files and git gc takes a while. The working tree is rather large so operations that inspect the entire working directory take quite a while. This repo is only used for data storage, though, so it's just a bunch of automated tools that handle it. Pulling changes from the repo is much, much faster than rsyncing the same data.
%find . -type f | wc -l
791887
%time git add .
git add . 6.48s user 13.53s system 55% cpu 36.121 total
%time git status
# On branch master
nothing to commit (working directory clean)
git status 0.00s user 0.01s system 0% cpu 47.169 total
%du -sh .
29G .
%cd .git
%du -sh .
7.9G .
Although there is a "more correct" answer above talking about the theoretical limitations, this answer seems more helpful to me as it allows to compare the own situation with yours. Thanks. –
Emprise
Very interesting. How is it possible that the working copy is larger than the
.git directory? My naive assumption was that the .git contains a copy of the working directory plus the history, so it must be larger. Can anyone point me to a resource understanding how these sizes are related? –
Kolkhoz @Kolkhoz The content in
.git directory is compressed. So a repository with relatively few commits is likely to have a smaller compressed history than the uncompressed working directory. My experience shows that in practice, with C++ code, the whole history is typically about the same size as the working directory. –
Plasterwork If you add files that are too large (GBs in my case, Cygwin, XP, 3 GB RAM), expect this.
fatal: Out of memory, malloc failed
More details here
Update 3/2/11: Saw similar in Windows 7 x64 with Tortoise Git. Tons of memory used, very very slow system response.
Back in Feb 2012, there was a very interesting thread on the Git mailing list from Joshua Redstone, a Facebook software engineer testing Git on a huge test repository:
The test repo has 4 million commits, linear history and about 1.3 million files.
Tests that were run show that for such a repo Git is unusable (cold operation lasting minutes), but this may change in the future. Basically the performance is penalized by the number of stat() calls to the kernel FS module, so it will depend on the number of files in the repo, and the FS caching efficiency. See also this Gist for further discussion.
+1 Interesting. That echoes my own answers about git limits detailing the limitations on huge files/number of files/packfiles. –
Ottava
As of 2023, my rule of thumb is to try to keep your repo < 524288 total files (files + directories) and maybe a few hundred GB...but it just did 2.1M (2.1 million) files at 107 GB for me
The 524288 number seems to be the maximum number of inodes that Linux can track for changes at a time (via "inode watches"), which is I think how git status quickly finds changed files--via inode notifications or something. Update: from @VonC, below:
When you get the warning about not having enough
inotifywatches, it is because the number of files in your repository has exceeded the currentinotifylimit. Increasing the limit allowsinotify(and, by extension, Git) to track more files. However, this does not mean Git would not work beyond this limit: If the limit is reached,git statusorgit add -Awould not "miss" changes. Instead, these operations might become slower as Git would need to manually check for changes instead of getting updates from the inotify mechanism.
So, you can go beyond 524288 files (my repo below is 2.1M files), but things get slower.
My experiment:
I just added 2095789 (~2.1M) files, comprising ~107 GB, to a fresh repo. The data was basically just a 300 MB chunk of code and build data, duplicated several hundred times over many years, with each new folder being a slightly-changed revision of the one before it.
Git did it, but it didn't like it. I'm on a really high-end laptop (20 cores, fast, Dell Precision 5570 laptop, 64 GB RAM, high-speed real-world 3500 MB/sec m.2 2 TB SSD), running Linux Ubuntu 22.04.2, and here are my results:
git --versionshowsgit version 2.34.1.git initwas instant.time git add -Atook 17m37.621s.time git committook about 11 minutes, since it had to rungit gcapparently, to pack stuff.I recommend using
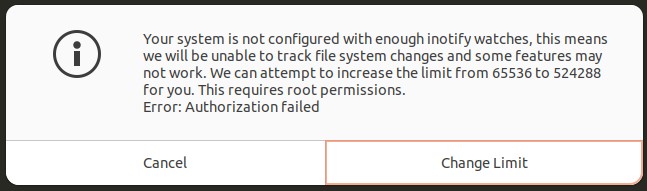
time git commit -m "Add all files"instead, to avoid having your text editor open up a 2.1M line file. Sublime Text was set as my git editor per my instructions here, and it handled it ok, but it took several seconds to open up, and it didn't have syntax highlighting like it normally does.While my commit editor was still open and I was typing the commit message, I got this GUI popup window:
![enter image description here]()
Text:
Your system is not configured with enough inotify watches, this means we will be unable to track file system changes and some features may not work. We can attempt to increase the limit from 65536 to 524288 for you. This requires root permissions.
Error: Authorization failedSo, I clicked "Change Limit" and typed in my root password.
This seems to indicate that if your repo has any more than 524288 (~500k) files and folders, then git cannot guarantee to notice changed files with
git status, no?After my commit editor closed, here's what my computer was thinking about while committing and packing the data:
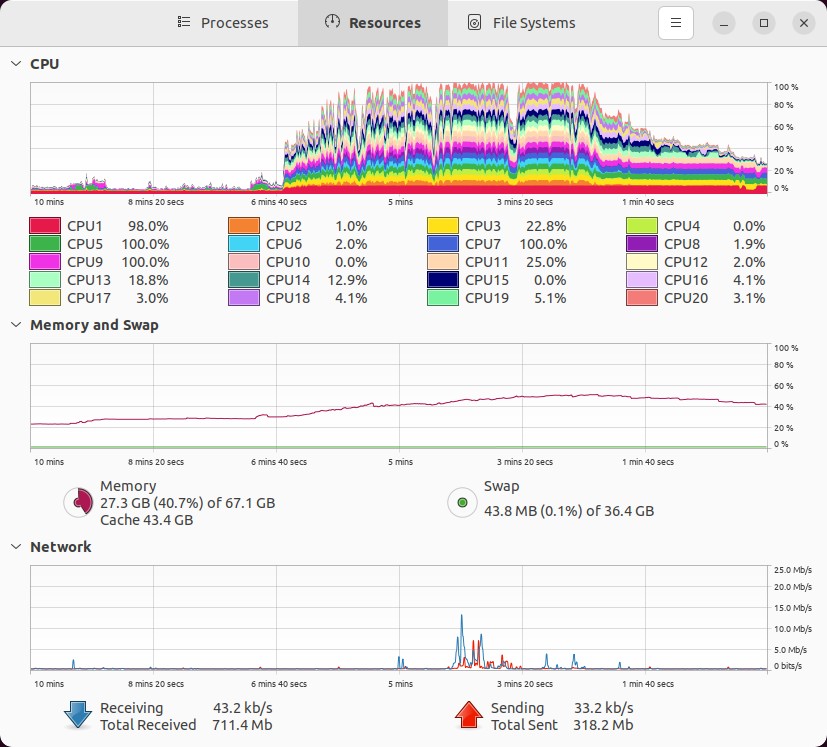
Note that my baseline RAM usage was somewhere around 17 GB, so I'm guessing only ~10 GB of this RAM usage is from
git gc. Actually, "eyeballing" the memory plot below shows my RAM usage went from ~25% before the commit, peaking up to ~53% during the commit, for a total usage of 53-23 = 28% x 67.1 GB = 18.79 GB approximate RAM usage.This makes sense, as looking after the fact, I see that my main pack file is 10.2 GB, here:
.git/objects/pack/pack-0eef596af0bd00e16a9ba77058e574c23280e28f.pack. So, it would take at least that much memory, thinking logically, to load that file into RAM and work with it to pack it up.![enter image description here]()
And here's what git printed to the screen:
$ time git commit Auto packing the repository in background for optimum performance. See "git help gc" for manual housekeeping.It took about 11 minutes to complete.
time git statusis now clean, but it takes about 2~3 seconds. Sometimes it prints out a normal message, like this:$ time git status On branch main nothing to commit, working tree clean real 0m2.651s user 0m1.558s sys 0m7.365sAnd sometimes it prints out something else with this warning-like/notification message:
$ time git status On branch main It took 2.01 seconds to enumerate untracked files. 'status -uno' may speed it up, but you have to be careful not to forget to add new files yourself (see 'git help status'). nothing to commit, working tree clean real 0m3.075s user 0m1.611s sys 0m7.443s^^^ I'm guessing this is what @VonC was talking about in his comment I put at the very top of this answer: how it takes longer since I don't have enough "inode watches" to track all files at once.
Compression is very good, as
du -sh .gitshows this:$ du -sh .git 11G .gitSo, my
.gitdir with all of the content (all 2.1M files and 107 GB of data) takes up only 11GB.Git does try to de-duplicate data between duplicate files (see my answer here), so this is good.
Running
git gcagain took about 43 seconds and had no additional affect on the size of my.gitdir, probably since my repo has only 1 single commit and it just rangit gcwhengit committing the first time minutes ago. See my answer just above for the output.The total directory size: active file system +
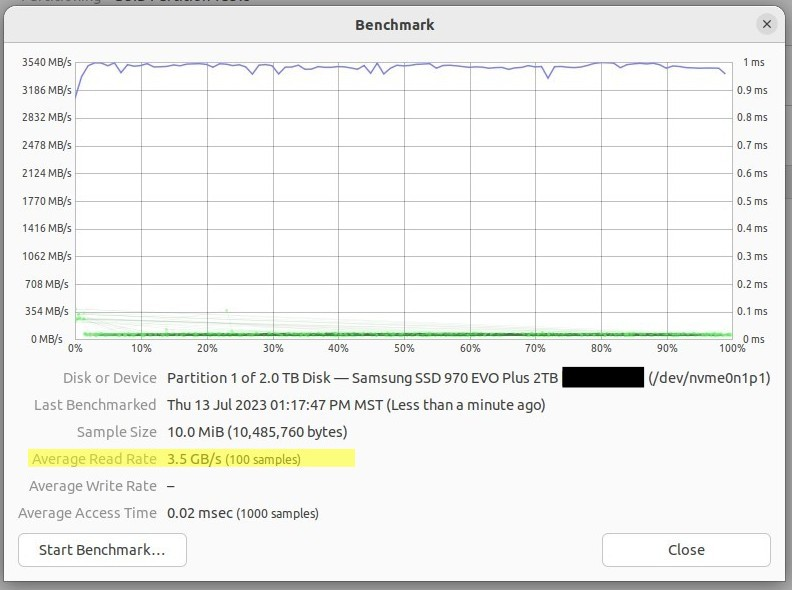
.gitdir, is 123 GB:$ time du -sh 123G . real 0m2.072s user 0m0.274s sys 0m1.781sHere's how fast my SSD is. This is part of why
git gconly took 11 minutes (the rest is my CPUs):Gnome Disks speed benchmark showing 3.5 GB/s read speed. I'd expect write speed to be ~75% of that:
![enter image description here]()
The above test is at the block level, I believe, which is lower than the filesystem level. I'd expect reads and writes at the filesystem level to be 1/10 of the speeds above (varying from 1/5 to 1/20 as fast as at the block level).
This concludes my real-life data test in git. I recommend you stick to < 500k files. Size wise, I don't know. Maybe you'd get away with 50 GB or 2 TB or 10 TB so long as your file count is closer to 500k files or less.
Going further:
1. Giving someone my 107 GB repo via my 11 GB .git dir
Now that git has compressed my 107 GB of 2.1M files into an 11 GB .git dir, I can easily recreate or share this .git dir with my colleagues to give them the whole repo! Don't copy the whole 123 GB repo directory. Instead, if your repo is called my_repo, simply create an empty my_repo dir on an external drive, copy just the .git dir into it, then give it to a colleague. They copy it to their computer, then they re-instantiate their whole working tree in the repo like this:
cd path/to/my_repo
# Unpack the whole working tree from the compressed .git dir.
# - WARNING: this permanently erases any changes not committed, so you better
# not have any uncommitted changes lying around when using `--hard`!
time git reset --hard
For me, on this same high-end computer, the time git reset --hard unpacking command took 7min 32sec, and git status is clean again.
If the .git dir is compressed in a .tar.xz file as my_repo.tar.xz, the instructions might look like this instead:
How to recover the entire 107 GB my_repo repo from my_repo.tar.xz, which just contains the 11 GB .git dir:
# Extract the archive (which just contains a .git dir)
mkdir -p my_repo
time tar -xf my_repo.tar.xz --directory my_repo
# In a **separate** terminal, watch the extraction progress by watching the
# output folder grow up to ~11 GB with:
watch -n 1 'du -sh my_repo'
# Now, have git unpack the entire repo
cd my_repo
time git status | wc -l # Takes ~4 seconds on a high-end machine, and shows
# that there are 1926587 files to recover.
time git reset --hard # Will unpack the entire repo from the .git dir!;
# takes about 8 minutes on a high-end machine.
2. Comparing changes between copied folder revisions in meld
Do this:
meld path/to/code_dir_rev1 path/to/code_dir_rev2
Meld opens up a folder comparison view, as though you were in a file explorer. Changed folders and files will be colored. Click down into folders, then on changed files, to see it open the file side-by-side comparison view to look at changes. Meld opens this up in a new tab. Close the tab when done, and go back to the folder view. Find another changed file, and repeat. This allows me to rapidly compare across these changed folder revisions without manually inputting them into a linear git history first, like they should have been in the first place.
See also:
- My answer: How to recursively run
dos2unix(or any other command) on your desired directory or path using multiple processes - Does git de-duplicate between files?
- Brian Harry, of Microsoft, on "The largest Git repo on the planet" - Microsoft apparently has a massive 300 GB mono-repo with 3.5M files containing pretty much all of their code. (I'd hate to be a remote worker and try to pull that...)
- @VonC on commit-graph chains, and how git is fast
Good analysis. Upvoted. As I mentioned below, Microsoft is managing a much larger repository since 2017, and has contributed to Git with the commit graphs, enabling you to instantiate large Git repositories. –
Ottava
Thanks, @VonC. Am I correct about the inode thing? What does it mean for my repo with 2.1M files when Linux can only track 524288 inodes? Will
git status and git add -A sometimes miss my changes? –
Unconnected When you get the warning about not having enough
inotify watches, it is because the number of files in your repository has exceeded the current inotify limit. Increasing the limit allows inotify (and, by extension, Git) to track more files. However, this does not mean Git would not work beyond this limit: If the limit is reached, git status or git add -A would not "miss" changes. Instead, these operations might become slower as Git would need to manually check for changes instead of getting updates from the inotify mechanism. –
Ottava @VonC, thanks! Makes sense. I added your quote to the top of my answer. I just added the
'status -uno' message I'm seeing with git status sometimes now too (search for it in my answer). Have you seen this before? Is this because I am beyond the limit of inotify watches? –
Unconnected Yes, I have seen this message before, as illustrated here. A good
git clean -ndfX is generally a good first step to avoid this. –
Ottava As of 2018-04-20 Git for Windows has a bug which effectively limits the file size to 4GB max using that particular implementation (this bug propagates to lfs as well).
It depends on what your meaning is. There are practical size limits (if you have a lot of big files, it can get boringly slow). If you have a lot of files, scans can also get slow.
There aren't really inherent limits to the model, though. You can certainly use it poorly and be miserable.
I think that it's good to try to avoid large file commits as being part of the repository (e.g. a database dump might be better off elsewhere), but if one considers the size of the kernel in its repository, you can probably expect to work comfortably with anything smaller in size and less complex than that.
I have a generous amount of data that's stored in my repo as individual JSON fragments. There's about 75,000 files sitting under a few directories and it's not really detrimental to performance.
Checking them in the first time was, obviously, a little slow.
I found this trying to store a massive number of files(350k+) in a repo. Yes, store. Laughs.
$ time git add .
git add . 333.67s user 244.26s system 14% cpu 1:06:48.63 total
The following extracts from the Bitbucket documentation are quite interesting.
When you work with a DVCS repository cloning, pushing, you are working with the entire repository and all of its history. In practice, once your repository gets larger than 500MB, you might start seeing issues.
... 94% of Bitbucket customers have repositories that are under 500MB. Both the Linux Kernel and Android are under 900MB.
The recommended solution on that page is to split your project into smaller chunks.
I guess this is quite outdated. Right now, there seem to be nothing about android (nor linux) repo on the site you are linking to. But I wonder if it wasn't inaccurate even back then? E.g. compare this answer. Maybe they meant something else? –
Bonnie
git has a 4G (32bit) limit for repo.
© 2022 - 2024 — McMap. All rights reserved.